Large-Scale Constraint Generation -- Can LLMs Parse Hundreds of Constraints?
作者: Matteo Boffa, Jiaxuan You
分类: cs.CL, cs.AI
发布日期: 2025-09-28
💡 一句话要点
提出大规模约束生成问题LSCG,并设计FoCusNet提升LLM在复杂约束下的解析能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模约束生成 大型语言模型 约束解析 FoCusNet 文本生成
📋 核心要点
- 现有方法在约束生成任务中,难以有效处理大规模、细粒度的约束条件,导致性能显著下降。
- 论文提出FoCusNet,通过将原始约束列表提炼为更小的相关子集,引导LLM关注关键约束,提升解析效率。
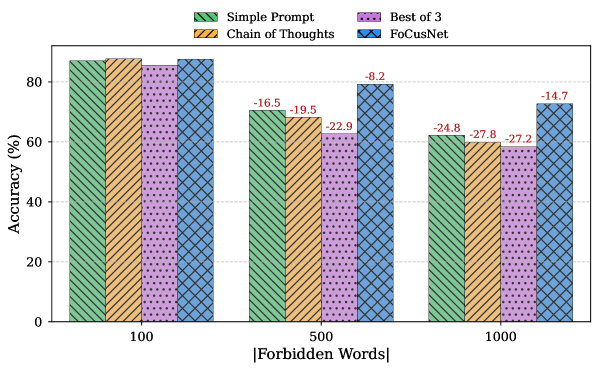
- 实验表明,随着约束数量增加,现有方法性能急剧下降,而FoCusNet能够显著提升LLM在复杂约束下的生成准确率。
📝 摘要(中文)
本文提出了大规模约束生成(LSCG)问题,旨在评估大型语言模型(LLM)解析大量、细粒度、通用约束列表的能力。为了检验LLM处理日益增多约束的能力,作者构建了一个名为Words Checker的LSCG实例。通过Words Checker,评估了模型特性(如模型大小、模型家族)和引导技术(如简单提示、思维链、Best of N)对性能的影响。此外,作者还提出了FoCusNet,一个小型专用模型,用于将原始约束列表解析为更小的子集,从而帮助LLM专注于相关约束。实验表明,现有解决方案的性能随着约束数量的增加而显著下降,而FoCusNet的准确率提高了8-13%。
🔬 方法详解
问题定义:论文旨在解决LLM在大规模约束生成(LSCG)场景下的性能瓶颈问题。具体而言,当LLM需要同时满足大量细粒度的约束条件时,其生成质量会显著下降。现有的约束生成方法难以有效处理这种大规模约束,导致生成结果不符合要求。
核心思路:论文的核心思路是引入一个预处理模块,即FoCusNet,用于从原始的大规模约束列表中提取出与当前生成任务最相关的约束子集。通过减少LLM需要考虑的约束数量,降低其计算复杂度,从而提高生成质量和效率。
技术框架:整体框架包含两个主要模块:1) FoCusNet:一个小型神经网络,用于从大规模约束列表中筛选出相关约束子集。2) LLM:负责根据FoCusNet提供的约束子集生成目标文本。流程如下:首先,将原始约束列表输入FoCusNet,得到一个精简的约束子集。然后,将该子集作为提示输入LLM,LLM根据这些约束生成最终结果。
关键创新:论文的关键创新在于提出了FoCusNet,这是一个专门用于约束筛选的神经网络。与直接将所有约束输入LLM相比,FoCusNet能够有效地减少LLM需要处理的约束数量,从而提高生成质量。此外,LSCG问题的提出本身也是一个创新,为后续研究提供了一个新的评估基准。
关键设计:FoCusNet的具体结构和训练方式未知,论文中可能没有详细描述。关键设计在于如何训练FoCusNet,使其能够准确地识别出与当前生成任务最相关的约束。这可能涉及到使用特定的损失函数,例如交叉熵损失,来衡量FoCusNet的预测结果与真实相关约束之间的差异。具体的网络结构和参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Words Checker数据集上,随着约束数量的增加,现有解决方案的性能显著下降。而引入FoCusNet后,LLM的准确率提高了8-13%。这表明FoCusNet能够有效地帮助LLM处理大规模约束,提升生成质量。
🎯 应用场景
该研究成果可应用于需要满足大量约束条件的文本生成任务,例如自动代码生成、创意写作、法律文本生成等。通过提高LLM在复杂约束下的生成能力,可以显著提升这些应用的实用性和可靠性。未来,该方法有望扩展到其他领域,如机器人控制、优化问题求解等。
📄 摘要(原文)
Recent research has explored the constrained generation capabilities of Large Language Models (LLMs) when explicitly prompted by few task-specific requirements. In contrast, we introduce Large-Scale Constraint Generation (LSCG), a new problem that evaluates whether LLMs can parse a large, fine-grained, generic list of constraints. To examine the LLMs' ability to handle an increasing number constraints, we create a practical instance of LSCG, called Words Checker. In Words Checker, we evaluate the impact of model characteristics (e.g., size, family) and steering techniques (e.g., Simple Prompt, Chain of Thought, Best of N) on performance. We also propose FoCusNet, a small and dedicated model that parses the original list of constraints into a smaller subset, helping the LLM focus on relevant constraints. Experiments reveal that existing solutions suffer a significant performance drop as the number of constraints increases, with FoCusNet showing an 8-13% accuracy boost.