HiPO: Hybrid Policy Optimization for Dynamic Reasoning in LLMs
作者: Ken Deng, Zizheng Zhan, Wen Xiang, Wenqiang Zhu, Weihao Li, Jingxuan Xu, Tianhao Peng, Xinping Lei, Kun Wu, Yifan Yao, Haoyang Huang, Huaixi Tang, Kepeng Lei, Zhiyi Lai, Songwei Yu, Zongxian Feng, Zuchen Gao, Weihao Xie, Chenchen Zhang, Yanan Wu, Yuanxing Zhang, Lecheng Huang, Yuqun Zhang, Jie Liu, Zhaoxiang Zhang, Haotian Zhang, Bin Chen, Jiaheng Liu
分类: cs.CL
发布日期: 2025-09-28 (更新: 2025-10-21)
💡 一句话要点
HiPO:面向LLM动态推理的混合策略优化框架,提升效率并保持精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 强化学习 策略优化 自适应推理
📋 核心要点
- 现有LLM在复杂任务中过度依赖冗长的CoT推理,导致效率低下和推理成本高昂。
- HiPO框架通过混合策略优化,使LLM能够自适应地选择详细推理或直接响应,平衡准确性和效率。
- 实验表明,HiPO在数学和编码任务中,显著减少token使用,同时保持甚至提升了准确性。
📝 摘要(中文)
大型语言模型(LLM)越来越多地依赖于思维链(CoT)推理来提高复杂任务的准确性。然而,始终生成冗长的推理过程是低效的,导致过多的token使用和更高的推理成本。本文介绍了一种混合策略优化(HiPO)框架,用于自适应推理控制,使LLM能够选择性地决定何时进行详细推理(Think-on)以及何时直接响应(Think-off)。具体来说,HiPO结合了混合数据管道(提供配对的Think-on和Think-off响应)和混合强化学习奖励系统,该系统平衡了准确性和效率,同时避免过度依赖详细推理。在数学和编码基准测试中的实验表明,HiPO可以显著减少token长度,同时保持或提高准确性。我们希望HiPO能够成为一种高效自适应推理的原则性方法,从而推动面向推理的LLM在现实世界、资源敏感型环境中的部署。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂任务中进行推理时,过度依赖思维链(Chain-of-Thought, CoT)而导致的效率问题。现有方法的痛点在于,无论任务难度如何,LLM都倾向于生成冗长的推理过程,这导致了过高的token使用量和推理成本,尤其是在资源受限的环境中,这种低效性更加明显。
核心思路:HiPO的核心思路是让LLM具备自适应推理的能力,即根据任务的复杂程度,动态地决定是否需要进行详细的CoT推理(Think-on)或者直接给出答案(Think-off)。这种自适应性是通过结合混合数据管道和混合强化学习奖励系统来实现的,旨在平衡推理的准确性和效率。
技术框架:HiPO框架包含以下几个主要组成部分:1) 混合数据管道:构建包含配对的Think-on和Think-off响应的数据集,用于训练LLM。2) 混合策略网络:LLM作为策略网络,负责决定何时进行Think-on或Think-off。3) 混合强化学习奖励系统:设计一个综合考虑准确性和效率的奖励函数,鼓励LLM在保证准确性的前提下,尽可能减少推理步骤。4) 策略优化:使用强化学习算法(如PPO)优化策略网络,使其能够做出更明智的推理决策。
关键创新:HiPO的关键创新在于其混合策略优化方法,它允许LLM在推理过程中动态地切换推理模式,而不是像传统方法那样始终采用固定的推理模式。这种自适应性使得LLM能够更好地适应不同难度的任务,从而在保证准确性的同时,显著提高推理效率。与现有方法的本质区别在于,HiPO不再是简单地追求更高的准确率,而是更加注重准确率和效率之间的平衡。
关键设计:HiPO的关键设计包括:1) 奖励函数设计:奖励函数需要综合考虑准确率和token使用量,例如,可以设计一个奖励函数,当LLM给出正确答案时,给予正向奖励,同时根据token使用量给予负向奖励。2) 策略网络结构:策略网络可以使用Transformer结构,输入是任务描述和LLM的当前状态,输出是选择Think-on或Think-off的概率。3) 强化学习算法选择:可以使用Proximal Policy Optimization (PPO)等算法来优化策略网络,PPO算法能够有效地平衡探索和利用,从而避免策略崩溃。
🖼️ 关键图片


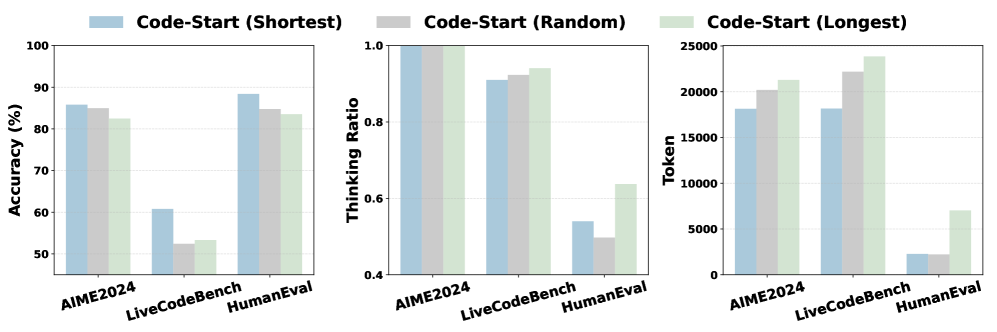
📊 实验亮点
实验结果表明,HiPO在数学和编码基准测试中表现出色。例如,在某些数学问题求解任务中,HiPO可以在保持甚至提高准确率的同时,将token使用量减少高达50%。与传统的CoT方法相比,HiPO能够更有效地利用计算资源,从而实现更高的推理效率。
🎯 应用场景
HiPO框架具有广泛的应用前景,尤其适用于资源受限的场景,如移动设备、边缘计算和低功耗设备。它可以应用于各种需要LLM进行推理的任务,例如问答系统、代码生成、数学问题求解等。通过自适应地控制推理过程,HiPO可以显著降低LLM的计算成本和能耗,从而使其能够在更多场景中得到应用。
📄 摘要(原文)
Large Language Models (LLMs) increasingly rely on Chain-of-Thought (CoT) reasoning to improve accuracy on complex tasks. However, always generating lengthy reasoning traces is inefficient, leading to excessive token usage and higher inference costs. This paper introduces the Hybrid Policy Optimization (i.e., HiPO), a framework for adaptive reasoning control that enables LLMs to selectively decide when to engage in detailed reasoning (Think-on) and when to respond directly (Think-off). Specifically, HiPO combines a hybrid data pipelineproviding paired Think-on and Think-off responseswith a hybrid reinforcement learning reward system that balances accuracy and efficiency while avoiding over-reliance on detailed reasoning. Experiments across mathematics and coding benchmarks demonstrate that HiPO can substantially reduce token length while maintaining or improving accuracy. Finally, we hope HiPO a can be a principled approach for efficient adaptive reasoning, advancing the deployment of reasoning-oriented LLMs in real-world, resource-sensitive settings.