Assessing Large Language Models in Updating Their Forecasts with New Information
作者: Zhangdie Yuan, Zifeng Ding, Andreas Vlachos
分类: cs.CL
发布日期: 2025-09-28
💡 一句话要点
EVOLVECAST框架评估LLM在接收新信息后预测更新能力,揭示其保守偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 未来事件预测 信念更新 置信度校准 保守偏差
📋 核心要点
- 现有未来事件预测研究忽略了新信息出现时预测和置信度应如何演变。
- 提出EVOLVECAST框架,评估LLM在接收训练截止日期后的新信息时,预测更新的合理性。
- 实验表明LLM对新信息有响应,但更新不一致或保守,置信度估计远低于人类水平。
📝 摘要(中文)
现有研究大多将未来事件预测视为静态任务,忽略了预测及其置信度应如何随着新证据的出现而演变。为了弥补这一差距,本文提出了EVOLVECAST,一个用于评估大型语言模型(LLM)是否能根据新信息适当修正其预测的框架。EVOLVECAST特别评估了LLM在接收到训练截止日期之后发布的信息时,是否会调整其预测。我们使用人类预测者作为比较参考,分析在更新的背景下预测的变化和置信度校准。虽然LLM表现出对新信息的一定响应性,但它们的更新往往不一致或过于保守。我们进一步发现,无论是口头表达的置信度估计还是基于logits的置信度估计,都没有始终优于对方,并且两者都远未达到人类的参考标准。在各种设置中,模型倾向于表现出保守偏差,这突显了需要更强大的信念更新方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在接收到新的、训练数据之外的信息后,如何有效地更新其预测的问题。现有方法通常将未来事件预测视为静态任务,没有充分考虑新信息对预测结果和置信度的影响。LLM可能无法正确地整合新信息,导致预测不准确或置信度校准不佳。
核心思路:论文的核心思路是构建一个评估框架,通过向LLM提供训练截止日期之后发布的新信息,观察其预测结果和置信度的变化。将LLM的预测更新行为与人类预测者进行比较,从而评估LLM在新信息环境下的预测能力。这种比较能够揭示LLM在信念更新方面的不足,例如保守偏差或不一致性。
技术框架:EVOLVECAST框架包含以下主要步骤:1) 选择未来事件预测任务;2) 确定LLM的训练截止日期;3) 收集训练截止日期之后发布的相关信息;4) 首先要求LLM在没有新信息的情况下进行预测,并估计置信度;5) 然后向LLM提供新信息,并要求其更新预测和置信度;6) 将LLM的预测更新行为与人类预测者进行比较,评估LLM的预测准确性、置信度校准和更新一致性。
关键创新:该论文的主要创新在于提出了EVOLVECAST框架,用于系统地评估LLM在接收到新信息后更新预测的能力。与以往研究不同,EVOLVECAST关注的是动态预测过程,而不是静态预测结果。通过与人类预测者进行比较,EVOLVECAST能够更全面地了解LLM在信念更新方面的优势和不足。
关键设计:EVOLVECAST的关键设计包括:1) 使用人类预测者作为参考标准,评估LLM的预测更新行为;2) 比较口头表达的置信度估计和基于logits的置信度估计,评估不同置信度估计方法的有效性;3) 分析LLM在不同设置下的保守偏差,揭示其信念更新的局限性。
🖼️ 关键图片
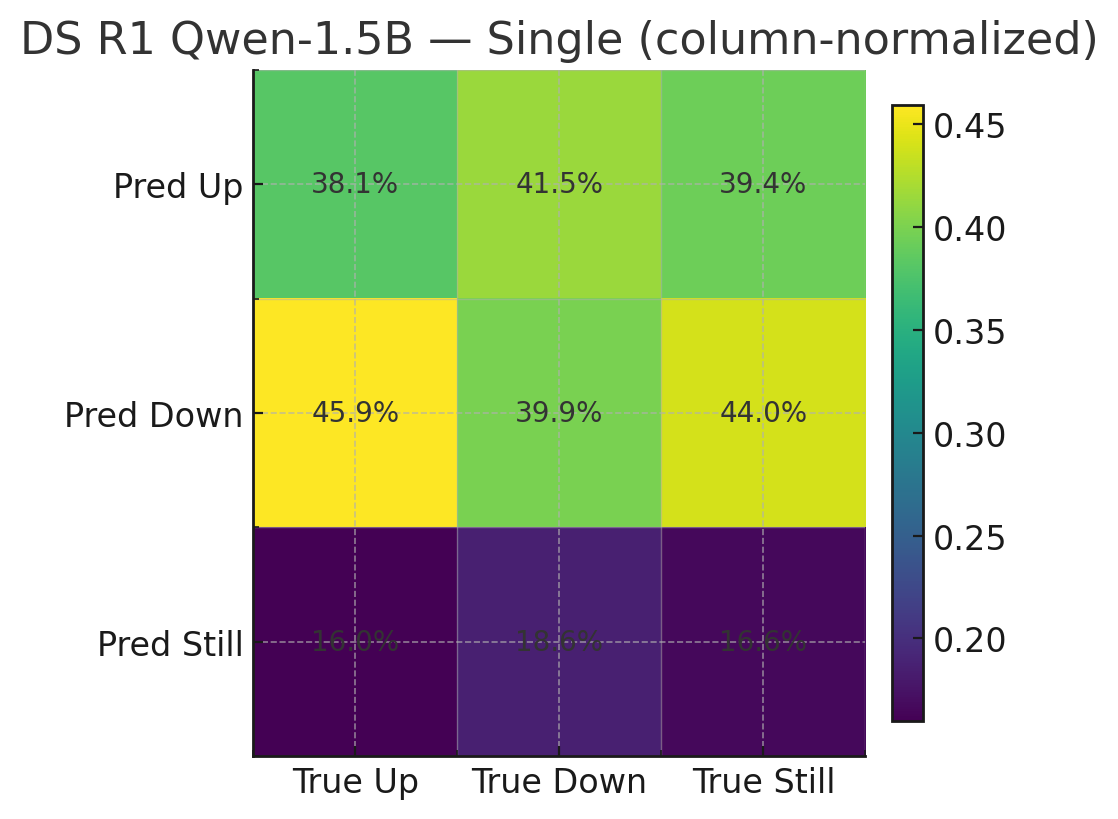
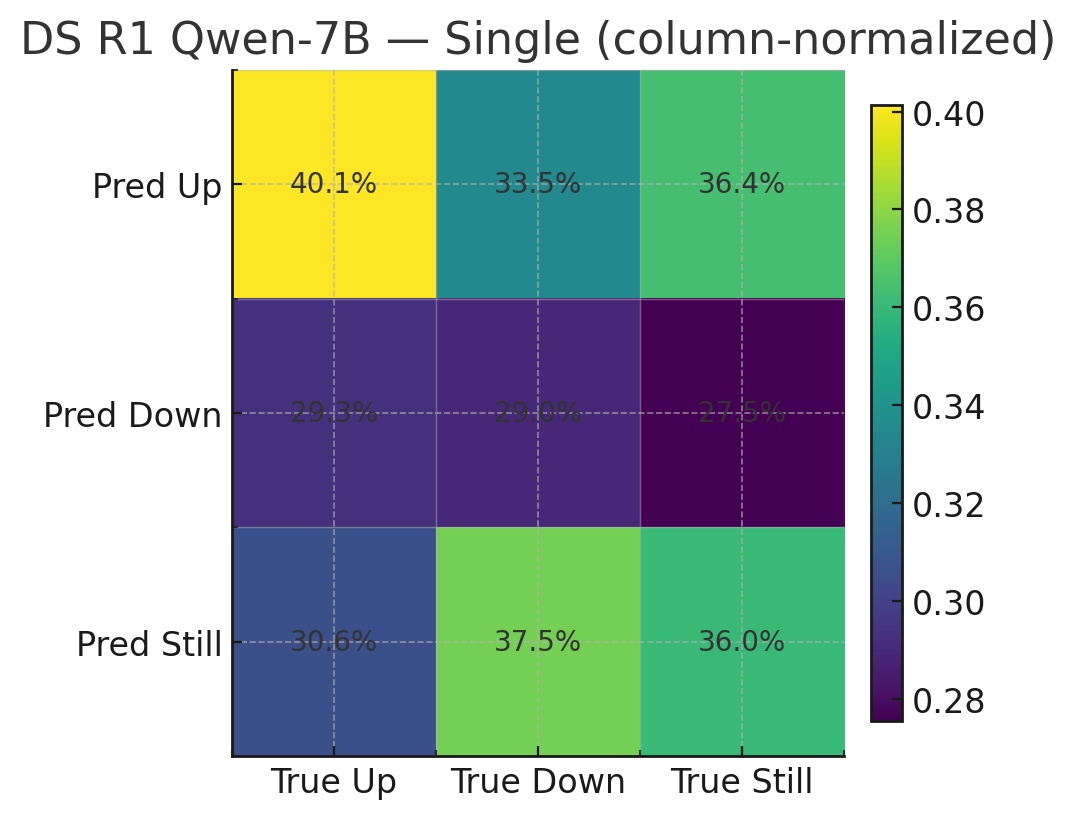

📊 实验亮点
实验结果表明,LLM在接收到新信息后能够做出一定的预测调整,但其更新行为往往不一致或过于保守。无论是口头表达的置信度估计还是基于logits的置信度估计,都远未达到人类的参考标准。模型普遍存在保守偏差,表明需要更强大的信念更新方法。这些发现为改进LLM的预测能力提供了重要的启示。
🎯 应用场景
该研究成果可应用于需要持续更新预测的领域,如金融市场预测、疫情发展预测、供应链风险管理等。通过改进LLM的信念更新能力,可以提高预测的准确性和可靠性,为决策提供更有效的支持。未来的研究可以探索更有效的信念更新方法,例如利用强化学习或元学习来训练LLM,使其能够更好地适应新信息。
📄 摘要(原文)
Prior work has largely treated future event prediction as a static task, failing to consider how forecasts and the confidence in them should evolve as new evidence emerges. To address this gap, we introduce EVOLVECAST, a framework for evaluating whether large language models appropriately revise their predictions in response to new information. In particular, EVOLVECAST assesses whether LLMs adjust their forecasts when presented with information released after their training cutoff. We use human forecasters as a comparative reference to analyze prediction shifts and confidence calibration under updated contexts. While LLMs demonstrate some responsiveness to new information, their updates are often inconsistent or overly conservative. We further find that neither verbalized nor logits-based confidence estimates consistently outperform the other, and both remain far from the human reference standard. Across settings, models tend to express conservative bias, underscoring the need for more robust approaches to belief updating.