Taming Masked Diffusion Language Models via Consistency Trajectory Reinforcement Learning with Fewer Decoding Step
作者: Jingyi Yang, Guanxu Chen, Xuhao Hu, Jing Shao
分类: cs.CL, cs.AI
发布日期: 2025-09-28
备注: 10 pages, 4 figures, 7 tables. Code: https://github.com/yjyddq/EOSER-ASS-RL
🔗 代码/项目: GITHUB
💡 一句话要点
提出EOSER、ASS与CJ-GRPO,提升Masked Diffusion语言模型推理效率与一致性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Masked Diffusion模型 语言模型 强化学习 解码策略 并行解码 推理效率 一致性训练
📋 核心要点
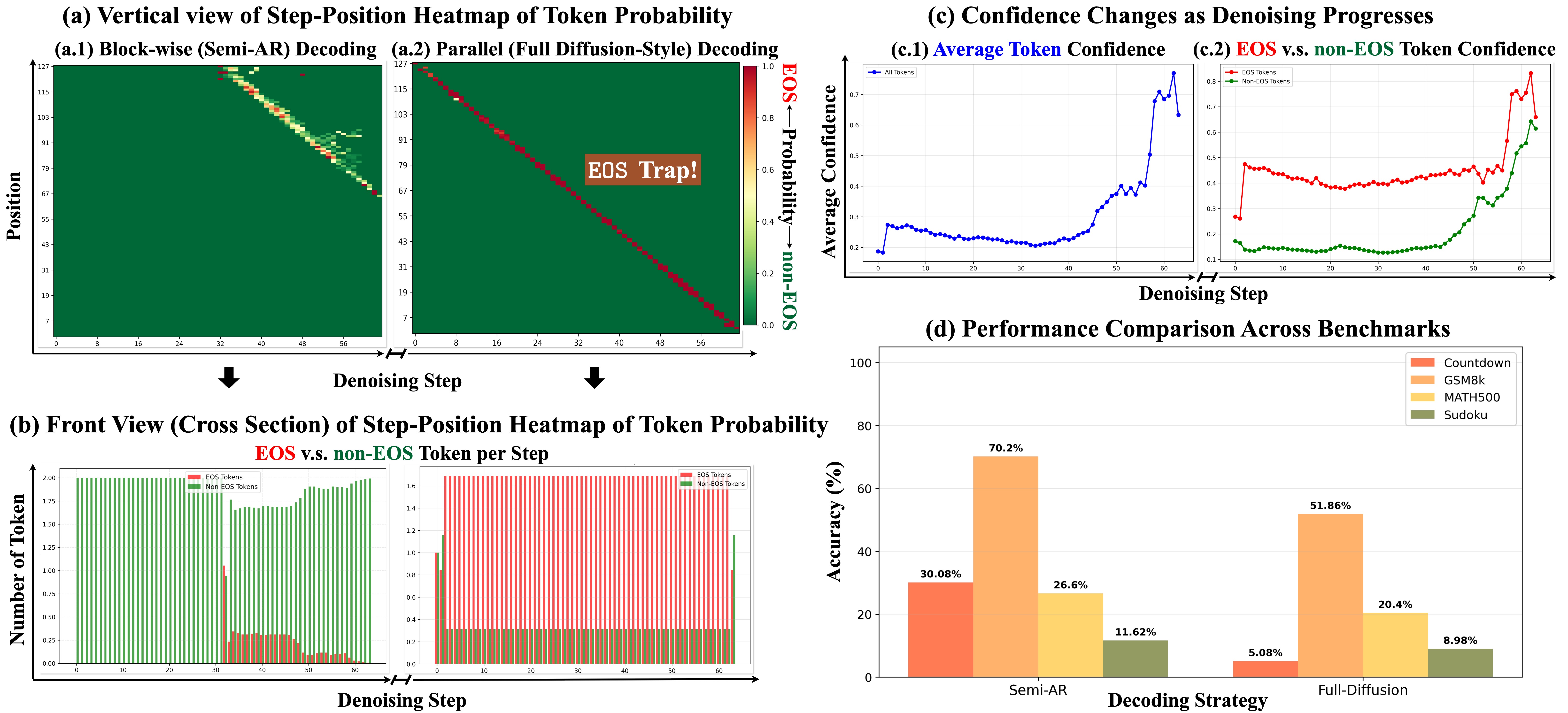
- 现有MDLM解码策略和强化学习算法研究不足,直接迁移自回归模型技术可能并非最优。
- 提出EOSER和ASS解码调度器,使MDLM能够进行完整的diffusion式解码,减少推理步骤并提升性能。
- 引入CJ-GRPO强化学习算法,强调rollout轨迹和优化轨迹的一致性,减少优化误差。
📝 摘要(中文)
Masked diffusion语言模型(MDLMs)作为自回归(AR)语言模型的一种有前景的替代方案,具有并行解码、灵活的生成顺序和更少推理步骤的潜力。尽管有这些优点,但针对MDLM的解码策略和强化学习(RL)算法仍未得到充分探索。直接将AR模型的成熟技术转移到MDLM上并非最优。例如,MDLM训练期间未使用Block-wise和semi-AR解码策略,为何推理时它们优于完整diffusion式解码?将为AR模型设计的RL算法直接应用于MDLM会产生训练-推理不一致,因为MDLM解码是非因果的(并行的)。这导致rollout轨迹和优化轨迹之间的不一致。为了解决这些挑战,我们提出了EOS Early Rejection (EOSER)和Ascending Step-Size (ASS)解码调度器,释放MDLM执行完整diffusion式解码的潜力,以更少的解码步骤实现有竞争力的性能。此外,我们引入了Consistency Trajectory Group Relative Policy Optimization (CJ-GRPO)来驯服MDLM,强调rollout轨迹和优化轨迹之间的一致性,并减少skip-step优化造成的优化误差。我们在数学和规划基准等推理任务上使用LLaDA-8B-Instruct进行了大量实验。结果表明,所提出的EOSER和ASS机制,以及CJ-GRPO,对于有效和高效地驯服MDLM具有重要的前景。
🔬 方法详解
问题定义:论文旨在解决Masked Diffusion语言模型(MDLM)在解码策略和强化学习训练方面存在的不足。现有方法直接将自回归语言模型(AR模型)的技术迁移到MDLM上,但忽略了MDLM的并行解码特性,导致训练和推理不一致,以及次优的解码效率。现有方法在MDLM训练时未使用Block-wise和semi-AR解码策略,导致推理时性能不佳。
核心思路:论文的核心思路是设计更适合MDLM特性的解码策略和强化学习算法,以提高MDLM的推理效率和性能。具体来说,通过EOSER和ASS解码调度器,使MDLM能够以更少的步骤进行完整的diffusion式解码。同时,通过CJ-GRPO强化学习算法,保证rollout轨迹和优化轨迹的一致性,从而更有效地训练MDLM。
技术框架:论文提出的方法主要包含两个部分:解码策略和强化学习算法。解码策略包括EOSER(EOS Early Rejection)和ASS(Ascending Step-Size)两种调度器,用于控制MDLM的解码过程。强化学习算法是CJ-GRPO(Consistency Trajectory Group Relative Policy Optimization),用于训练MDLM。整体流程是:首先使用EOSER和ASS进行解码,然后使用CJ-GRPO进行强化学习训练,从而优化MDLM的性能。
关键创新:论文的关键创新在于:1) 提出了EOSER和ASS解码调度器,能够充分利用MDLM的并行解码能力,以更少的步骤实现高性能。2) 提出了CJ-GRPO强化学习算法,解决了MDLM训练和推理不一致的问题,提高了训练效率。与现有方法相比,论文提出的方法更适合MDLM的特性,能够更有效地训练和使用MDLM。
关键设计:EOSER的关键设计在于提前拒绝不合理的EOS token,从而减少不必要的计算。ASS的关键设计在于逐渐增加解码步长,从而在保证性能的同时减少解码步骤。CJ-GRPO的关键设计在于强调rollout轨迹和优化轨迹的一致性,通过Group Relative Policy Optimization来减少skip-step优化带来的误差。具体的参数设置和损失函数细节在论文中进行了详细描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的EOSER和ASS机制,以及CJ-GRPO,能够显著提高MDLM在推理任务上的性能。具体来说,在数学和规划基准测试中,使用LLaDA-8B-Instruct模型,该方法能够以更少的解码步骤实现与现有方法相当甚至更好的性能。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要高效文本生成的场景,例如机器翻译、文本摘要、对话系统、代码生成等。通过提高MDLM的推理效率和性能,可以降低计算成本,并提升用户体验。未来,该研究可以进一步扩展到其他类型的生成模型,并应用于更广泛的领域。
📄 摘要(原文)
Masked diffusion language models (MDLMs) have recently emerged as a promising alternative to autoregressive (AR) language models, offering properties such as parallel decoding, flexible generation orders, and the potential for fewer inference steps. Despite these advantages, decoding strategies and reinforcement learning (RL) algorithms tailored for MDLMs remain underexplored. A naive approach is to directly transfer techniques well-established for AR models to MDLMs. However, this raises an immediate question: Is such a naive transfer truly optimal? For example, 1) Block-wise and semi-AR decoding strategies are not employed during the training of MDLMs, so why do they outperform full diffusion-style decoding during inference? 2) Applying RL algorithms designed for AR models directly to MDLMs exhibits a training-inference inconsistency, since MDLM decoding are non-causal (parallel). This results in inconsistencies between the rollout trajectory and the optimization trajectory. To address these challenges, we propose EOS Early Rejection (EOSER) and Ascending Step-Size (ASS) decoding scheduler, which unlock the potential of MDLMs to perform full diffusion-style decoding, achieving competitive performance with fewer decoding steps. Additionally, we introduce Consistency Trajectory Group Relative Policy Optimization (CJ-GRPO) for taming MDLMs, which emphasizes the consistency between rollout trajectory and optimization trajectory, and reduces the optimization errors caused by skip-step optimization. We conduct extensive experiments on reasoning tasks, such as mathematical and planning benchmarks, using LLaDA-8B-Instruct. The results demonstrate that the proposed EOSER and ASS mechanisms, together with CJ-GRPO, hold significant promise for effectively and efficiently taming MDLMs. Code: https://github.com/yjyddq/EOSER-ASS-RL.