SPELL: Self-Play Reinforcement Learning for evolving Long-Context Language Models
作者: Ziyi Yang, Weizhou Shen, Chenliang Li, Ruijun Chen, Fanqi Wan, Ming Yan, Xiaojun Quan, Fei Huang
分类: cs.CL
发布日期: 2025-09-28 (更新: 2025-12-22)
备注: Preprint under review
💡 一句话要点
提出SPELL框架,通过自博弈强化学习提升长文本语言模型的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 自博弈学习 强化学习 语言模型 无监督学习 自动课程学习 多角色交互
📋 核心要点
- 现有长文本语言模型在长文本推理方面进展缓慢,缺乏可靠的人工标注和可编程验证的奖励信号。
- SPELL框架通过多角色自博弈,让模型在提问、回答和验证的循环中持续学习,无需人工标注。
- 实验表明,SPELL在多个长文本基准测试中显著提升了LLM的性能,超越了同等规模的微调模型。
📝 摘要(中文)
本文提出SPELL,一个多角色自博弈强化学习框架,旨在实现长文本推理能力的可扩展、无标签优化。SPELL在一个模型中集成了三种循环角色——提问者、回答者和验证者,以实现持续的自我改进。提问者从原始文档和参考答案中生成问题;回答者学习基于文档解决这些问题;验证者评估回答者输出与提问者参考答案之间的语义等价性,产生奖励信号以指导持续训练。为了稳定训练,引入了自动课程,逐步增加文档长度,并采用奖励函数来调整问题难度以适应模型不断发展的能力。在六个长文本基准上的大量实验表明,SPELL始终如一地提高了各种LLM的性能,并且优于在大型带注释数据上微调的同等规模模型。值得注意的是,SPELL在强大的推理模型Qwen3-30B-A3B-Thinking上实现了pass@8平均7.6个百分点的提升,提高了其性能上限,并显示出扩展到更强大模型的潜力。
🔬 方法详解
问题定义:现有的大语言模型在处理长文本推理任务时面临挑战,主要原因是缺乏高质量的标注数据和可验证的奖励信号,导致模型难以有效地学习长文本中的复杂关系和依赖。
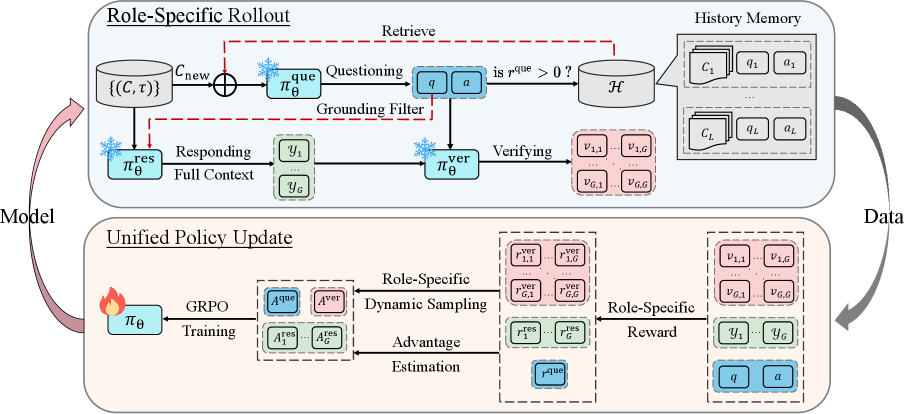
核心思路:SPELL的核心思路是利用自博弈强化学习,构建一个闭环的学习系统,让模型在没有人工干预的情况下,通过自我生成数据和自我评估来提升长文本推理能力。通过提问者、回答者和验证者三个角色之间的循环交互,模型可以不断地学习和改进。
技术框架:SPELL框架包含三个主要模块:提问者(Questioner)、回答者(Responder)和验证者(Verifier)。提问者负责从给定的文档和参考答案中生成问题;回答者负责根据文档内容回答提问者提出的问题;验证者负责评估回答者的答案与参考答案之间的语义相似度,并生成奖励信号。这三个模块循环交互,形成一个闭环的自学习系统。
关键创新:SPELL的关键创新在于利用自博弈强化学习来解决长文本推理问题,避免了对大量人工标注数据的依赖。通过提问者、回答者和验证者三个角色的循环交互,模型可以不断地生成新的训练数据,并根据验证者的反馈进行自我改进。此外,自动课程学习策略和自适应奖励函数进一步提高了训练的稳定性和效率。
关键设计:SPELL框架中,提问者可以使用各种问题生成策略,例如基于关键词提取或模板生成。回答者可以使用各种预训练语言模型,并进行微调以适应长文本推理任务。验证者可以使用各种语义相似度度量方法,例如基于BERT的句子嵌入或基于规则的匹配。自动课程学习策略逐步增加文档长度,自适应奖励函数根据模型的能力调整问题难度。具体损失函数的设计需要根据实际任务进行调整,通常包括回答的准确性和验证者奖励的优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SPELL框架在六个长文本基准测试中均取得了显著的性能提升。特别是在Qwen3-30B-A3B-Thinking模型上,SPELL实现了pass@8指标平均7.6个百分点的提升,超过了在大型标注数据集上微调的同等规模模型。这表明SPELL框架能够有效地提高长文本语言模型的推理能力。
🎯 应用场景
SPELL框架可应用于需要长文本理解和推理的各种场景,例如文档摘要、问答系统、信息检索和知识图谱构建。该方法降低了对人工标注数据的依赖,使得长文本语言模型能够更有效地应用于实际问题,具有广泛的应用前景。
📄 摘要(原文)
Progress in long-context reasoning for large language models (LLMs) has lagged behind other recent advances. This gap arises not only from the intrinsic difficulty of processing long texts, but also from the scarcity of reliable human annotations and programmatically verifiable reward signals. In this paper, we propose SPELL, a multi-role self-play reinforcement learning framework that enables scalable, label-free optimization for long-context reasoning. SPELL integrates three cyclical roles-questioner, responder, and verifier-within a single model to enable continual self-improvement. The questioner generates questions from raw documents paired with reference answers; the responder learns to solve these questions based on the documents; and the verifier evaluates semantic equivalence between the responder's output and the questioner's reference answer, producing reward signals to guide continual training. To stabilize training, we introduce an automated curriculum that gradually increases document length and a reward function that adapts question difficulty to the model's evolving capabilities. Extensive experiments on six long-context benchmarks show that SPELL consistently improves performance across diverse LLMs and outperforms equally sized models fine-tuned on large-scale annotated data. Notably, SPELL achieves an average 7.6-point gain in pass@8 on the strong reasoning model Qwen3-30B-A3B-Thinking, raising its performance ceiling and showing promise for scaling to even more capable models.