Aligning LLMs for Multilingual Consistency in Enterprise Applications
作者: Amit Agarwal, Hansa Meghwani, Hitesh Laxmichand Patel, Tao Sheng, Sujith Ravi, Dan Roth
分类: cs.CL, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-25)
备注: Accepted at EMNLP 2025
💡 一句话要点
提出批量对齐微调策略,解决企业应用中LLM多语言一致性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言一致性 大型语言模型 批量对齐 微调 企业应用
📋 核心要点
- 现有LLM在多语言环境下表现不一致,尤其是在非英语语言上,这限制了其在企业级应用中的可靠性。
- 论文提出一种批量对齐策略,通过在训练时对齐不同语言的语义等价数据,来提高LLM的多语言一致性。
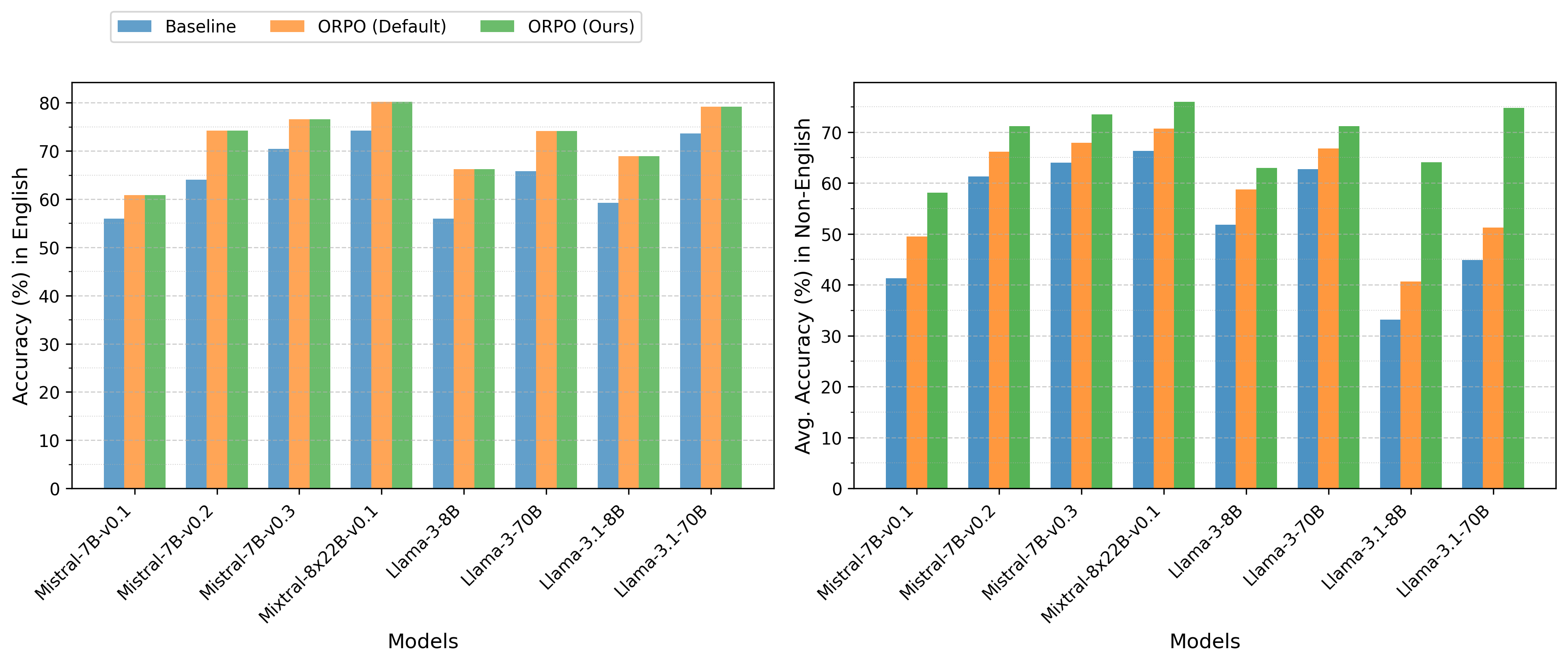
- 实验结果表明,该方法在不影响英语性能的前提下,显著提高了非英语语言的准确率,最高提升达23.9%。
📝 摘要(中文)
大型语言模型(LLM)由于以英语为中心的预训练和内部推理偏差,在高资源语言和中/低资源语言之间存在显著的性能差距,导致其在全球企业应用中的可靠性不足。这种不一致性损害了客户支持、内容审核和信息检索等多语言环境中的客户体验和运营可靠性。即使使用先进的检索增强生成(RAG)系统,非英语语言的准确率也比英语低29%。我们提出了一种实用的批量对齐策略来微调LLM,利用每个训练批次中语义等价的多语言数据,直接对齐模型在不同语言上的输出。这种方法在不影响英语性能、模型推理或检索质量的前提下,将非英语的准确率提高了23.9%。我们的方法易于实现、可扩展,并能与现有的LLM训练和部署流程无缝集成,从而在行业中实现更稳健和公平的多语言AI解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多语言企业应用中表现出的不一致性问题。具体而言,由于LLM通常以英语为中心进行预训练,导致其在非英语语言上的性能显著低于英语,即使采用检索增强生成(RAG)等技术,非英语语言的准确率仍然较低。现有方法未能有效解决这种语言间的性能差异,影响了多语言场景下的用户体验和运营效率。
核心思路:论文的核心思路是通过批量对齐策略,在LLM的微调阶段直接对齐不同语言的输出。该策略利用语义等价的多语言数据,确保模型在处理相同含义的不同语言文本时,能够产生一致的输出。通过这种方式,可以减少模型对英语的偏见,提高其在非英语语言上的性能。
技术框架:该方法的核心在于训练数据的组织方式和损失函数的设计。在每个训练批次中,包含语义等价的多语言数据样本。模型接收这些样本作为输入,并生成相应的输出。损失函数的设计目标是最小化不同语言输出之间的差异,同时保持模型在英语上的性能。整个框架可以无缝集成到现有的LLM训练和部署流程中。
关键创新:该方法最重要的创新点在于其批量对齐的训练策略。与传统的微调方法不同,该方法不是独立地处理不同语言的数据,而是将语义等价的多语言数据放在同一个批次中进行训练,从而直接促使模型学习不同语言之间的对应关系。这种方法能够更有效地减少语言间的性能差异,提高模型的多语言一致性。
关键设计:关键设计包括:1) 构建包含语义等价的多语言数据的训练集;2) 设计合适的损失函数,以最小化不同语言输出之间的差异,例如可以使用交叉熵损失或余弦相似度损失;3) 调整训练批次的大小,以确保每个批次包含足够的多语言数据样本;4) 在微调过程中,可以采用不同的学习率和优化器,以获得最佳的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该批量对齐策略在不影响英语性能的前提下,显著提高了非英语语言的准确率,最高提升达23.9%。与传统的微调方法相比,该方法能够更有效地减少语言间的性能差异。此外,实验还验证了该方法不会影响模型的推理能力和检索质量,表明其具有良好的通用性和实用性。
🎯 应用场景
该研究成果可广泛应用于需要多语言支持的企业级应用,例如:多语言客户支持系统,可以提高不同语言用户的服务质量;全球内容审核平台,确保对不同语言内容的审核标准一致;跨语言信息检索系统,提升非英语用户的搜索体验。该方法能够提升LLM在多语言环境下的可靠性和公平性,具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Large language models (LLMs) remain unreliable for global enterprise applications due to substantial performance gaps between high-resource and mid/low-resource languages, driven by English-centric pretraining and internal reasoning biases. This inconsistency undermines customer experience and operational reliability in multilingual settings such as customer support, content moderation, and information retrieval. Even with advanced Retrieval-Augmented Generation (RAG) systems, we observe up to an 29% accuracy drop in non-English languages compared to English. We propose a practical, batch-wise alignment strategy for fine-tuning LLMs, leveraging semantically equivalent multilingual data in each training batch to directly align model outputs across languages. This approach improves non-English accuracy by up to 23.9% without compromising English performance, model reasoning, or retrieval quality. Our method is simple to implement, scalable, and integrates seamlessly with existing LLM training & deployment pipelines, enabling more robust and equitable multilingual AI solutions in industry.