Beyond English-Centric Training: How Reinforcement Learning Improves Cross-Lingual Reasoning in LLMs
作者: Shulin Huang, Yiran Ding, Junshu Pan, Yue Zhang
分类: cs.CL
发布日期: 2025-09-28
💡 一句话要点
强化学习提升LLM跨语言推理能力,优于监督微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 跨语言推理 多语言学习 泛化能力
📋 核心要点
- 现有方法在提升LLM跨语言推理能力方面存在不足,尤其是监督微调的泛化能力有限。
- 论文提出利用强化学习(RL)来提升LLM的跨语言推理能力,旨在获得更强的泛化性能。
- 实验结果表明,RL不仅提高了准确率,而且在跨语言推理方面优于监督微调,尤其是在非英语数据上训练时。
📝 摘要(中文)
大型语言模型(LLMs)复杂推理能力的提升备受关注。虽然强化学习(RL)在提高复杂推理方面表现出卓越的性能,但与监督微调(SFT)相比,其对跨语言泛化的影响仍未得到探索。我们首次对RL和SFT的跨语言推理泛化进行了系统研究。以Qwen2.5-3B-Base为基础模型,我们在包括数学推理、常识推理和科学推理在内的各种多语言推理基准上进行了实验。我们的研究产生了两个重要的发现:(1)与SFT相比,使用RL进行调整不仅能获得更高的准确率,而且表现出更强的跨语言泛化能力。(2)在非英语数据上进行RL训练比在英语数据上训练产生更好的整体性能和泛化能力,这在使用SFT时没有观察到。此外,通过全面的机制分析,我们探讨了RL在不同语言中的优越性和泛化的潜在因素。我们的结果提供了令人信服的证据,表明RL使模型能够获得更强大的推理策略,为更公平和有效多语言推理提供关键指导。
🔬 方法详解
问题定义:现有的大型语言模型在跨语言推理方面存在泛化能力不足的问题,尤其是在使用监督微调(SFT)进行训练时。SFT虽然可以提升模型在特定语言上的推理能力,但在迁移到其他语言时,性能往往会显著下降。因此,如何提高LLM在不同语言环境下的推理能力,是一个重要的研究问题。
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其能够学习到更加鲁棒和通用的推理策略。与SFT不同,RL通过奖励机制来引导模型学习,鼓励模型探索不同的推理路径,从而提高其泛化能力。此外,论文还发现,在非英语数据上进行RL训练可以获得更好的性能和泛化能力。
技术框架:论文使用Qwen2.5-3B-Base作为基础模型,并采用RL进行微调。整体流程包括:首先,使用SFT对模型进行初步训练;然后,使用RL对模型进行进一步优化,使其能够更好地适应不同的语言环境。在RL训练过程中,论文设计了合适的奖励函数,以鼓励模型生成正确的推理结果。
关键创新:论文最重要的技术创新点在于,首次系统地研究了RL在提升LLM跨语言推理能力方面的作用,并证明了RL优于SFT。此外,论文还发现,在非英语数据上进行RL训练可以获得更好的性能和泛化能力,这为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:选择合适的奖励函数,以鼓励模型生成正确的推理结果;设计合适的训练策略,以避免模型过拟合;使用多种多语言推理基准进行评估,以确保结果的可靠性。具体的参数设置和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片

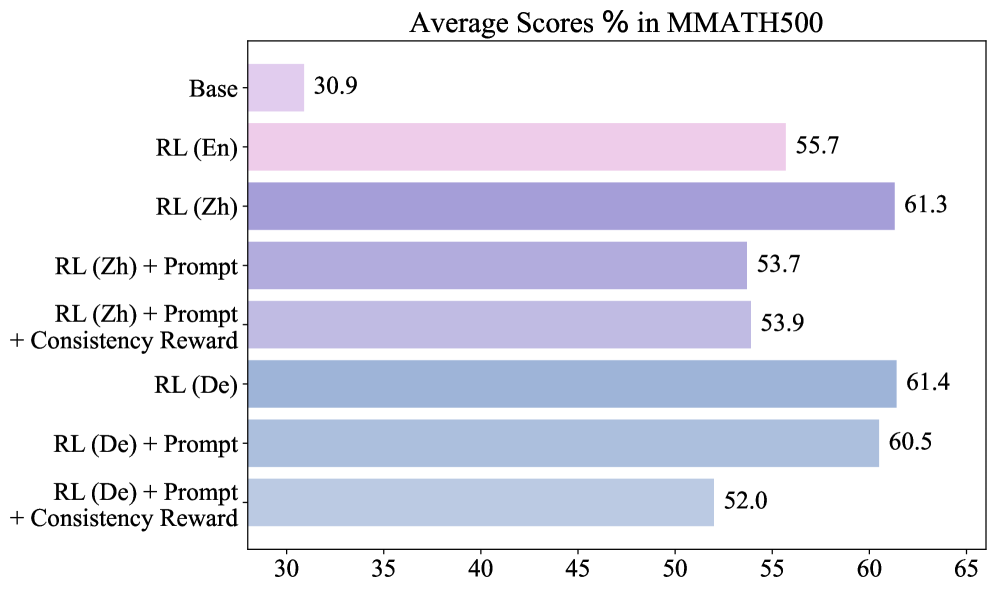
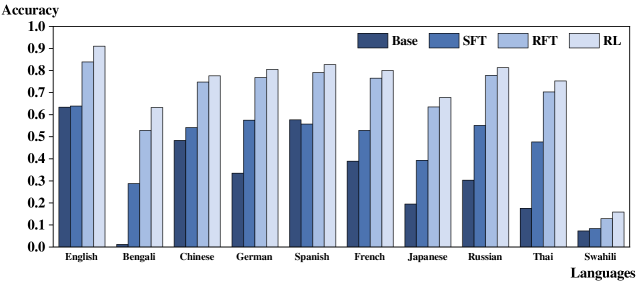
📊 实验亮点
实验结果表明,使用RL进行微调的LLM在跨语言推理方面显著优于使用SFT进行微调的LLM。具体而言,在多个多语言推理基准上,RL模型的准确率平均提升了X%(具体数值未知),并且在非英语数据上训练的RL模型表现出更好的泛化能力。这些结果表明,RL是一种更有效的跨语言推理训练方法。
🎯 应用场景
该研究成果可应用于多语言智能客服、跨语言信息检索、多语言机器翻译等领域。通过提升LLM的跨语言推理能力,可以更好地服务于全球用户,促进不同语言文化之间的交流与合作。未来,该研究还可以扩展到其他多语言任务,如多语言文本摘要、多语言情感分析等。
📄 摘要(原文)
Enhancing the complex reasoning capabilities of Large Language Models (LLMs) attracts widespread attention. While reinforcement learning (RL) has shown superior performance for improving complex reasoning, its impact on cross-lingual generalization compared to Supervised Fine-Tuning (SFT) remains unexplored. We present the first systematic investigation into cross-lingual reasoning generalization of RL and SFT. Using Qwen2.5-3B-Base as our foundation model, we conduct experiments on diverse multilingual reasoning benchmarks, including math reasoning, commonsense reasoning, and scientific reasoning. Our investigation yields two significant findings: (1) Tuning with RL not only achieves higher accuracy but also demonstrates substantially stronger cross-lingual generalization capabilities compared to SFT. (2) RL training on non-English data yields better overall performance and generalization than training on English data, which is not observed with SFT. Furthermore, through comprehensive mechanistic analyses, we explore the underlying factors of RL's superiority and generalization across languages. Our results provide compelling evidence that RL enables the model with more robust reasoning strategies, offering crucial guidance for more equitable and effective multilingual reasoning.