Fast Thinking for Large Language Models
作者: Haoyu Zheng, Zhuonan Wang, Yuqian Yuan, Tianwei Lin, Wenqiao Zhang, Zheqi Lv, Juncheng Li, Siliang Tang, Yueting Zhuang, Hongyang He
分类: cs.CL
发布日期: 2025-09-28
💡 一句话要点
提出基于隐式码本的快速推理框架,提升大语言模型推理效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 快速推理 思维链 隐式码本 策略学习
📋 核心要点
- 现有大语言模型推理依赖显式token生成,效率低,CoT方法虽提升性能但引入了长推理轨迹。
- 提出隐式码本框架,训练阶段学习CoT草图的离散策略先验,推理阶段使用少量连续思考向量。
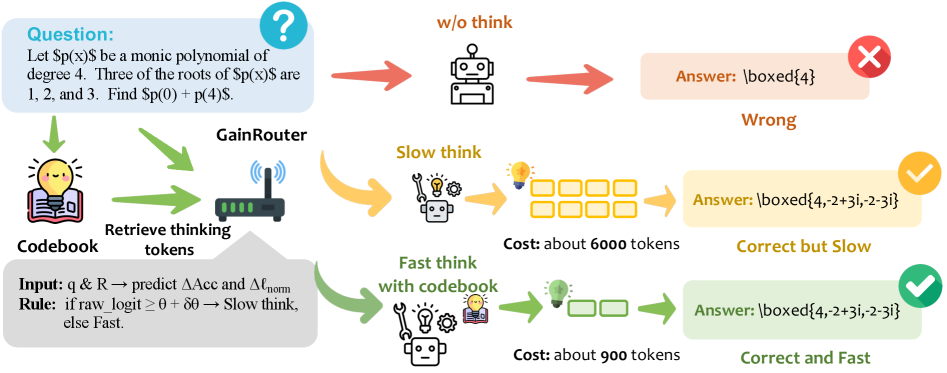
- 引入GainRouter路由机制,自适应切换快速码本引导推理和慢速显式推理,降低token生成。
📝 摘要(中文)
面向推理的大语言模型通常依赖于逐步生成显式token,其有效性通常取决于大规模的监督微调或强化学习。虽然思维链(CoT)技术显著提高了复杂推理任务的性能,但它们仍然效率低下,需要长的推理轨迹,从而增加了延迟和token使用量。本文提出了一种用于快速思考的隐式码本框架,该框架仅在训练期间使用简洁的CoT草图来学习离散策略先验的码本。在推理时,模型在单个pass中以从码本中提取的少量连续思考向量为条件,从而实现策略级别的指导,而无需生成显式推理token。为了补充这种设计,我们提出了一种轻量级的路由机制GainRouter,它可以自适应地在快速码本引导推理和慢速显式推理之间切换,从而抑制过度思考并减少不必要的token生成。在多个推理基准上的实验表明,我们的方法在显著降低推理成本的同时,实现了有竞争力或更优越的准确性,为大型语言模型中高效且可控的推理提供了一条实用的途径。
🔬 方法详解
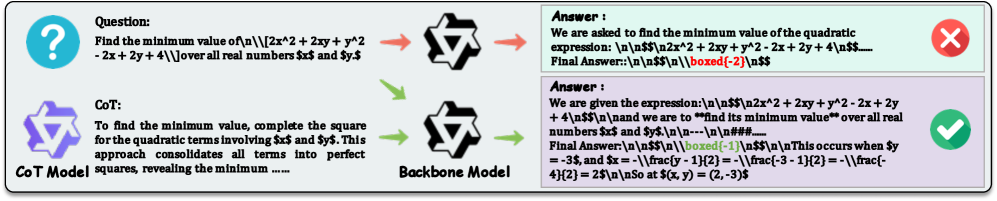
问题定义:现有的大语言模型在进行复杂推理时,通常采用Chain-of-Thought (CoT) 的方法,即逐步生成中间推理步骤。这种方法虽然提高了推理的准确性,但是由于需要生成大量的token,导致推理速度慢,计算成本高。因此,如何提高大语言模型的推理效率,同时保持较高的推理准确率,是一个重要的研究问题。
核心思路:本文的核心思路是利用隐式码本学习离散策略先验,从而在推理阶段避免生成显式的推理token。具体来说,在训练阶段,模型学习CoT草图,并将其压缩成一个离散的码本。在推理阶段,模型直接从码本中提取少量连续思考向量,作为策略级别的指导,从而实现快速推理。
技术框架:该框架主要包含两个部分:隐式码本学习和GainRouter路由机制。隐式码本学习阶段,模型通过学习CoT草图,构建一个离散的策略先验码本。GainRouter路由机制则负责在推理阶段,自适应地选择使用快速码本引导推理或慢速显式推理。整体流程是,输入问题后,GainRouter决定是否使用码本进行快速推理。如果使用,则从码本中提取连续思考向量,并将其输入到模型中进行推理。否则,模型将采用传统的CoT方法进行推理。
关键创新:该论文的关键创新在于提出了隐式码本的概念,并将其应用于大语言模型的推理加速。与传统的CoT方法相比,该方法避免了生成大量的显式推理token,从而显著提高了推理效率。此外,GainRouter路由机制能够自适应地选择推理方式,进一步提高了模型的灵活性和效率。
关键设计:在隐式码本学习阶段,需要设计合适的损失函数来保证码本的质量。在GainRouter路由机制中,需要设计合适的策略来决定何时使用快速码本引导推理,何时使用慢速显式推理。具体的参数设置和网络结构细节在论文中进行了详细描述,例如码本的大小、连续思考向量的维度、GainRouter的决策阈值等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个推理基准上取得了有竞争力的准确率,同时显著降低了推理成本。具体来说,与传统的CoT方法相比,该方法可以将推理速度提高数倍,并显著减少token的使用量。在某些任务上,该方法甚至可以取得比CoT方法更高的准确率。
🎯 应用场景
该研究成果可广泛应用于需要快速推理的大语言模型应用场景,例如在线问答系统、智能客服、实时决策支持等。通过降低推理延迟和计算成本,可以提升用户体验,并降低部署和维护成本。未来,该方法可以进一步扩展到其他类型的推理任务和模型架构中。
📄 摘要(原文)
Reasoning-oriented Large Language Models (LLMs) often rely on generating explicit tokens step by step, and their effectiveness typically hinges on large-scale supervised fine-tuning or reinforcement learning. While Chain-of-Thought (CoT) techniques substantially enhance performance on complex reasoning tasks, they remain inefficient, requiring long reasoning traces that increase latency and token usage. In this work, we introduce Latent Codebooks for Fast Thinking, a framework that uses concise CoT sketches only during training to learn a codebook of discrete strategy priors. At inference, the model conditions on a handful of continuous thinking vectors distilled from the codebook in a single pass, enabling strategy-level guidance without producing explicit reasoning tokens. To complement this design, we propose GainRouter, a lightweight routing mechanism that adaptively switches between fast codebook guided inference and slow explicit reasoning, thereby suppressing overthinking and reducing unnecessary token generation. Experiments across multiple reasoning benchmarks show that our approach achieves competitive or superior accuracy while substantially lowering inference cost, offering a practical path toward efficient and controllable reasoning in large language models.