Jackal: A Real-World Execution-Based Benchmark Evaluating Large Language Models on Text-to-JQL Tasks
作者: Kevin Frank, Anmol Gulati, Elias Lumer, Sindy Campagna, Vamse Kumar Subbiah
分类: cs.CL
发布日期: 2025-09-28
备注: 17 pages
💡 一句话要点
提出Jackal:一个基于真实执行的文本到JQL的大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到JQL 大语言模型 执行评估 Jira查询语言 自然语言处理
📋 核心要点
- 现有方法缺乏在真实Jira环境下,对自然语言到JQL转换的有效评估基准,难以反映实际应用场景。
- Jackal通过构建包含10万个真实世界文本到JQL的配对数据集,并结合执行结果进行评估,弥补了这一空白。
- 实验表明,即使是先进的LLM在Jackal数据集上表现仍有提升空间,尤其是在处理短自然语言和语义相似请求时。
📝 摘要(中文)
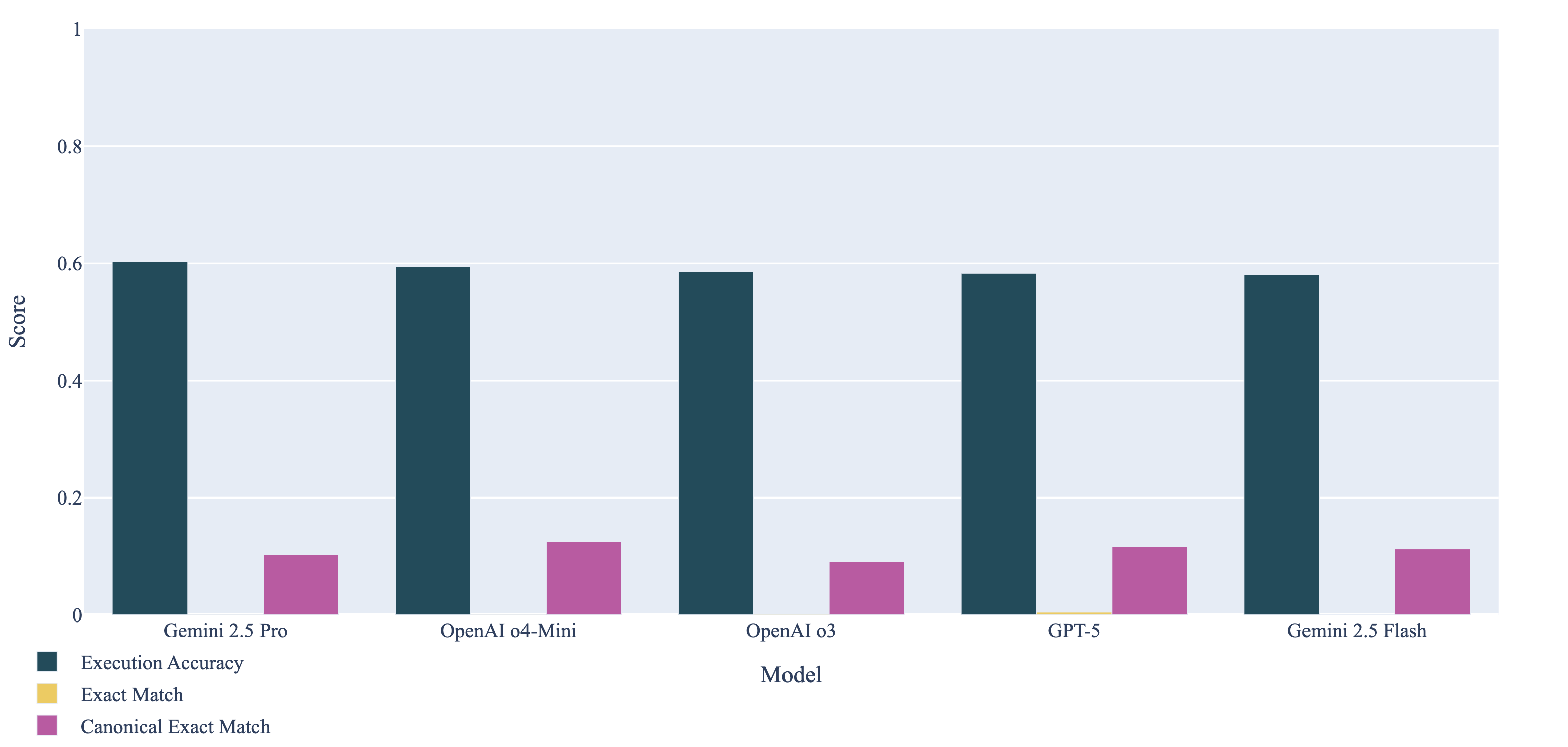
企业团队依赖Jira查询语言(JQL)从Jira中检索和过滤问题。然而,据我们所知,目前还没有开放的、真实的、基于执行的基准来评估自然语言查询到JQL的映射。我们推出了Jackal,这是一个新颖的大规模文本到JQL基准,包含10万个自然语言(NL)请求,并配有经过验证的JQL查询以及在包含超过20万个问题的实时Jira实例上执行的结果。为了反映真实世界的用法,每个JQL查询都与四种类型的用户请求相关联:(i)长自然语言,(ii)短自然语言,(iii)语义相似,以及(iv)语义精确。我们发布了Jackal,一个包含10万个文本到JQL对的语料库,以及一个基于执行的评分工具包,以及一个用于重现性的已评估Jira实例的静态快照。我们报告了23个大语言模型(LLM)在文本到JQL上的结果,这些模型涵盖了参数大小、开源和闭源模型,以及执行准确率、精确匹配和规范精确匹配。在本文中,我们报告了Jackal-5K的结果,它是Jackal的一个5000对的子集。在Jackal-5K上,最佳整体模型(Gemini 2.5 Pro)在四种用户请求类型上平均仅达到60.3%的执行准确率。性能在用户请求类型之间差异显著:(i)长自然语言(86.0%),(ii)短自然语言(35.7%),(iii)语义相似(22.7%),以及(iv)语义精确(99.3%)。通过基准测试LLM生成正确且可执行的JQL查询的能力,Jackal揭示了当前最先进的LLM的局限性,并为Jira企业数据中的未来研究提出了一个新的、基于执行的挑战。
🔬 方法详解
问题定义:论文旨在解决将自然语言查询转换为JQL查询的问题,并提供一个可靠的评估基准。现有方法缺乏在真实Jira环境下的评估,无法准确反映LLM在实际应用中的性能。现有数据集规模较小,难以覆盖真实世界JQL查询的多样性。
核心思路:论文的核心思路是构建一个大规模、真实世界的文本到JQL数据集,并采用基于执行的评估方法。通过在真实的Jira实例上执行生成的JQL查询,可以更准确地评估LLM的性能。同时,数据集包含多种类型的用户请求,以反映真实世界的使用场景。
技术框架:Jackal数据集的构建流程包括:1) 收集真实的Jira问题和查询日志;2) 将自然语言请求与对应的JQL查询进行配对;3) 在真实的Jira实例上执行JQL查询,并记录执行结果;4) 对数据进行清洗和验证,确保数据的质量和准确性。评估流程包括:1) 使用LLM生成JQL查询;2) 在Jira实例上执行生成的JQL查询;3) 将执行结果与真实结果进行比较,计算执行准确率、精确匹配等指标。
关键创新:Jackal的关键创新在于:1) 它是第一个大规模、真实世界的文本到JQL数据集;2) 它采用基于执行的评估方法,可以更准确地评估LLM的性能;3) 它包含多种类型的用户请求,可以更全面地反映真实世界的使用场景。
关键设计:Jackal数据集包含10万个文本到JQL的配对,其中Jackal-5K是包含5000个配对的子集。数据集中的每个JQL查询都与四种类型的用户请求相关联:长自然语言、短自然语言、语义相似和语义精确。评估指标包括执行准确率、精确匹配和规范精确匹配。执行准确率是指生成的JQL查询在Jira实例上执行后返回的结果与真实结果一致的比例。精确匹配是指生成的JQL查询与真实JQL查询完全一致的比例。规范精确匹配是指生成的JQL查询与真实JQL查询在规范化后完全一致的比例。
🖼️ 关键图片


📊 实验亮点
在Jackal-5K数据集上,最佳模型Gemini 2.5 Pro的平均执行准确率仅为60.3%。在不同类型的用户请求中,性能差异显著:长自然语言请求的准确率高达86.0%,而短自然语言请求的准确率仅为35.7%。这表明现有LLM在处理简洁或语义模糊的自然语言查询时仍存在挑战。
🎯 应用场景
该研究成果可应用于企业级智能助手、自动化测试、缺陷管理等领域。通过提升LLM在文本到JQL转换任务上的性能,可以帮助用户更高效地从Jira等问题跟踪系统中检索和过滤信息,提高工作效率。未来,该研究可以扩展到其他企业级数据查询语言,例如SQL。
📄 摘要(原文)
Enterprise teams rely on the Jira Query Language (JQL) to retrieve and filter issues from Jira. Yet, to our knowledge, there is no open, real-world, execution-based benchmark for mapping natural language queries to JQL. We introduce Jackal, a novel, large-scale text-to-JQL benchmark comprising 100,000 natural language (NL) requests paired with validated JQL queries and execution-based results on a live Jira instance with over 200,000 issues. To reflect real-world usage, each JQL query is associated with four types of user requests: (i) Long NL, (ii) Short NL, (iii) Semantically Similar, and (iv) Semantically Exact. We release Jackal, a corpus of 100,000 text-to-JQL pairs, together with an execution-based scoring toolkit, and a static snapshot of the evaluated Jira instance for reproducibility. We report text-to-JQL results on 23 Large Language Models (LLMs) spanning parameter sizes, open and closed source models, across execution accuracy, exact match, and canonical exact match. In this paper, we report results on Jackal-5K, a 5,000-pair subset of Jackal. On Jackal-5K, the best overall model (Gemini 2.5 Pro) achieves only 60.3% execution accuracy averaged equally across four user request types. Performance varies significantly across user request types: (i) Long NL (86.0%), (ii) Short NL (35.7%), (iii) Semantically Similar (22.7%), and (iv) Semantically Exact (99.3%). By benchmarking LLMs on their ability to produce correct and executable JQL queries, Jackal exposes the limitations of current state-of-the-art LLMs and sets a new, execution-based challenge for future research in Jira enterprise data.