LLMSQL: Upgrading WikiSQL for the LLM Era of Text-to-SQL
作者: Dzmitry Pihulski, Karol Charchut, Viktoria Novogrodskaia, Jan Kocoń
分类: cs.CL, cs.AI
发布日期: 2025-09-27 (更新: 2025-12-09)
备注: To appear in the Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW)
💡 一句话要点
LLMSQL:为大语言模型时代升级WikiSQL文本到SQL数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到SQL 自然语言接口 大型语言模型 数据集构建 数据清洗
📋 核心要点
- WikiSQL数据集存在大小写不敏感、数据类型不匹配等问题,限制了其在大语言模型时代的有效应用。
- LLMSQL通过自动化方法清理和重新标注WikiSQL,生成干净的自然语言问题和完整的SQL查询。
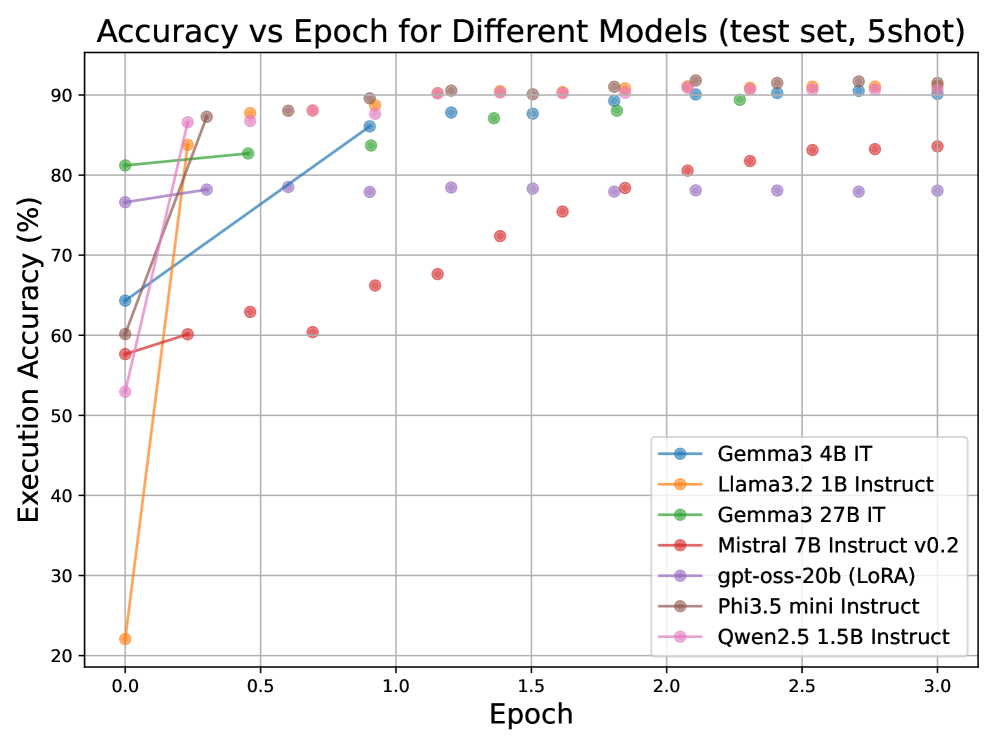
- 实验表明,DeepSeek-R1在LLMSQL上零样本准确率达到88.40%,小参数模型微调后准确率超过90%。
📝 摘要(中文)
将自然语言问题转换为SQL查询,使得非专业用户能够与关系数据库交互,一直是数据自然语言接口的核心任务。WikiSQL数据集在早期的文本到SQL研究中发挥了关键作用,但由于结构和标注问题(包括大小写敏感性不一致、数据类型不匹配、语法错误和未回答的问题),其使用量有所下降。我们提出了LLMSQL,对WikiSQL进行系统的修订和转换,专为大型语言模型时代设计。我们对这些错误进行分类,并实施自动化的清理和重新标注方法。为了评估这些改进的影响,我们评估了多个大型语言模型,包括Gemma 3、LLaMA 3.2、Mistral 7B、gpt-oss 20B、Phi-3.5 Mini、Qwen 2.5、OpenAI o4-mini、DeepSeek-R1等。值得注意的是,DeepSeek-R1在零样本设置中达到了88.40%的准确率,而参数小于10B的模型在微调后超过了90%的准确率。LLMSQL并非作为更新,而是作为LLM-ready的基准推出。与最初为指针网络模型量身定制的WikiSQL(从输入中选择token)不同,LLMSQL提供干净的自然语言问题和完整的SQL查询作为纯文本,从而能够为现代自然语言到SQL模型提供直接的生成和评估。
🔬 方法详解
问题定义:论文旨在解决WikiSQL数据集在大语言模型时代面临的挑战,包括数据质量问题(如大小写不一致、数据类型错误、语法错误)以及数据集设计与现代LLM不兼容的问题。现有方法难以直接利用WikiSQL训练和评估LLM,阻碍了文本到SQL任务的进一步发展。
核心思路:核心思路是对WikiSQL进行系统性的清洗、修复和重新标注,使其适应LLM的训练和评估。通过自动化方法解决数据质量问题,并提供纯文本格式的自然语言问题和SQL查询,方便LLM直接生成和评估SQL。
技术框架:LLMSQL的构建流程主要包括以下几个阶段:1) 错误分类:对WikiSQL中存在的各类错误进行详细分类。2) 自动化清洗:开发自动化脚本,修复数据类型不匹配、语法错误等问题。3) 重新标注:对存在歧义或未回答的问题进行重新标注,确保数据集的准确性和完整性。4) 数据格式转换:将数据转换为纯文本格式,方便LLM直接使用。
关键创新:关键创新在于系统性地解决了WikiSQL数据集的质量问题,并将其改造为LLM-ready的基准。与原始WikiSQL不同,LLMSQL提供干净的自然语言问题和完整的SQL查询作为纯文本,避免了指针网络模型对token选择的依赖,更符合现代LLM的生成式范式。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构,因为LLMSQL主要关注数据集的构建和改进。关键设计在于自动化清洗和重新标注的算法,以及将数据转换为纯文本格式的策略。具体的清洗和标注算法细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLMSQL数据集的改进显著提升了LLM在文本到SQL任务上的性能。DeepSeek-R1模型在零样本设置下达到了88.40%的准确率,超过了以往在WikiSQL上的最佳结果。此外,参数小于10B的模型在LLMSQL上进行微调后,准确率超过了90%,表明LLMSQL能够有效提升小参数模型的性能。
🎯 应用场景
LLMSQL可应用于各种需要自然语言接口访问数据库的场景,例如智能助手、数据分析平台、企业信息系统等。它能够帮助非专业用户通过自然语言查询数据库,提高数据访问的效率和便捷性。LLMSQL作为一个高质量的基准数据集,也将促进文本到SQL领域的研究和发展,推动更强大的自然语言数据库交互技术的出现。
📄 摘要(原文)
Converting natural language questions into SQL queries enables non-expert users to interact with relational databases and has long been a central task for natural language interfaces to data. While the WikiSQL dataset played a key role in early text-to-SQL research, its usage has declined due to structural and annotation issues, including case sensitivity inconsistencies, data type mismatches, syntax errors, and unanswered questions. We present LLMSQL, a systematic revision and transformation of WikiSQL designed for the large language model era. We classify these errors and implement automated methods for cleaning and re-annotation. To assess the impact of these improvements, we evaluated multiple large language models, including Gemma 3, LLaMA 3.2, Mistral 7B, gpt-oss 20B, Phi-3.5 Mini, Qwen 2.5, OpenAI o4-mini, DeepSeek-R1, and others. Notably, DeepSeek-R1 achieves 88.40% accuracy in a zero-shot setting, and models under 10B parameters surpass 90% accuracy after fine-tuning. Rather than serving as an update, LLMSQL is introduced as an LLM-ready benchmark. Unlike the original WikiSQL, which was tailored for pointer-network models selecting tokens from input, LLMSQL provides clean natural language questions and full SQL queries as plain text, enabling straightforward generation and evaluation for modern natural-language-to-SQL models.