Breaking the MoE LLM Trilemma: Dynamic Expert Clustering with Structured Compression
作者: Peijun Zhu, Ning Yang, Jiayu Wei, Jinghang Wu, Haijun Zhang
分类: cs.CL, cs.AI, cs.DC, cs.LG, cs.NE
发布日期: 2025-09-27
备注: 12 pages, 2 figures, 3 tables. Under review as a conference paper at ICLR 2026
💡 一句话要点
提出基于动态专家聚类与结构化压缩的MoE LLM优化框架,解决负载不均衡、参数冗余和通信开销问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 动态聚类 结构化压缩 低秩分解 模型优化 大语言模型
📋 核心要点
- MoE LLM面临负载不均衡、参数冗余和通信开销的三重困境,限制了其应用。
- 论文提出动态专家聚类与结构化压缩的统一框架,通过在线聚类和权重分解优化模型结构。
- 实验表明,该框架在参数减少80%的同时,吞吐量提升10%-20%,专家负载方差降低三倍以上。
📝 摘要(中文)
本文提出了一种统一的框架,该框架基于动态专家聚类和结构化压缩,旨在解决MoE LLM中负载不均衡、参数冗余和通信开销这三个难题。该方法采用在线聚类程序,定期使用参数和激活相似度的融合指标对专家进行重新分组,从而稳定专家的利用率。据我们所知,这是首批利用路由器的语义嵌入能力在训练期间动态重新配置模型架构以实现显著效率提升的框架之一。在每个集群内,我们将专家权重分解为共享的基础矩阵和极低秩的残差适配器,从而在每个组中实现高达五倍的参数减少,同时保持专业化。这种结构支持两阶段分层路由策略:token首先被分配到一个集群,然后分配到该集群内的特定专家,从而大大减少了路由搜索空间和全互联通信量。此外,异构精度方案(将共享基础存储在FP16中,将残差因子存储在INT4中)与非活动集群的动态卸载相结合,将峰值内存消耗降低到与密集模型相当的水平。在GLUE和WikiText-103上的评估表明,我们的框架在参数减少约80%、吞吐量提高10%至20%以及专家负载方差降低三倍以上的同时,匹配了标准MoE模型的质量。我们的工作表明,结构重组是实现可扩展、高效和内存高效的MoE LLM的一条可行路径。
🔬 方法详解
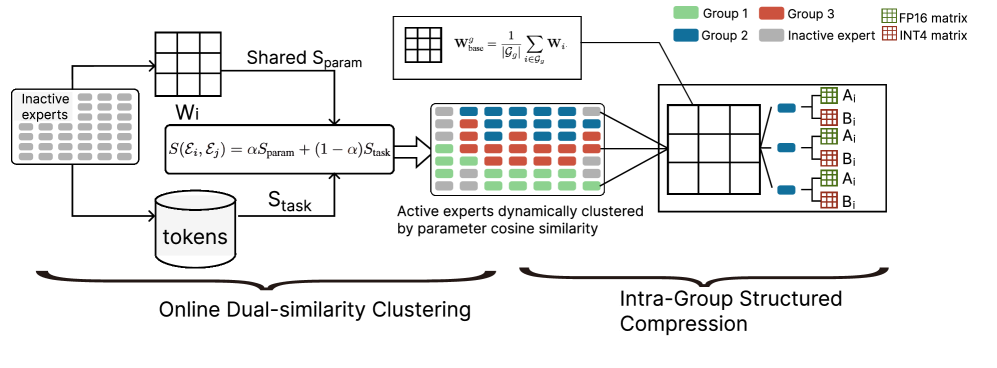
问题定义:MoE LLM虽然具有扩展模型容量的潜力,但同时也面临着负载不均衡,参数冗余和通信开销过大的问题。负载不均衡导致部分专家利用率低,参数冗余增加了计算负担,而全互联通信则限制了模型的扩展性。现有方法通常只关注其中一个或两个问题,缺乏一个统一的解决方案。
核心思路:本文的核心思路是通过动态调整专家结构和压缩专家权重来解决上述问题。动态专家聚类能够根据专家之间的相似性重新分配专家,从而平衡负载。结构化压缩则通过将专家权重分解为共享基础矩阵和低秩残差适配器来减少参数量。这种设计旨在在保持模型性能的同时,降低计算和通信开销。
技术框架:该框架包含三个主要模块:动态专家聚类、结构化压缩和分层路由。动态专家聚类模块定期使用参数和激活相似度的融合指标对专家进行重新分组。结构化压缩模块将每个集群内的专家权重分解为共享的基础矩阵和极低秩的残差适配器。分层路由模块首先将token分配到集群,然后分配到集群内的特定专家。
关键创新:该论文的关键创新在于提出了一个统一的框架,能够同时解决MoE LLM的负载不均衡、参数冗余和通信开销问题。动态专家聚类和结构化压缩的结合,以及分层路由策略,使得模型能够在保持性能的同时,显著降低计算和通信成本。此外,利用路由器的语义嵌入能力动态重构模型架构也是一个创新点。
关键设计:动态专家聚类使用参数和激活相似度的融合指标,具体融合方式未知。结构化压缩中,共享基础矩阵使用FP16精度,残差因子使用INT4精度,以进一步降低内存消耗。非活动集群会被动态卸载,以减少峰值内存占用。路由策略采用两阶段分层路由,先路由到cluster,再路由到cluster内的expert。具体的损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在GLUE和WikiText-103数据集上,能够在参数减少约80%的情况下,匹配标准MoE模型的性能。同时,吞吐量提高了10%至20%,专家负载方差降低了三倍以上。这些结果表明,该框架在效率和性能方面都具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要大规模语言模型的场景,例如自然语言处理、机器翻译、文本生成等。通过降低MoE LLM的计算和内存需求,该方法可以使得这些模型更容易部署在资源受限的设备上,并加速其在实际应用中的普及。此外,该方法还可以促进更大规模MoE模型的训练和研究。
📄 摘要(原文)
Mixture-of-Experts (MoE) Large Language Models (LLMs) face a trilemma of load imbalance, parameter redundancy, and communication overhead. We introduce a unified framework based on dynamic expert clustering and structured compression to address these issues cohesively. Our method employs an online clustering procedure that periodically regroups experts using a fused metric of parameter and activation similarity, which stabilizes expert utilization. To our knowledge, this is one of the first frameworks to leverage the semantic embedding capability of the router to dynamically reconfigure the model's architecture during training for substantial efficiency gains. Within each cluster, we decompose expert weights into a shared base matrix and extremely low-rank residual adapters, achieving up to fivefold parameter reduction per group while preserving specialization. This structure enables a two-stage hierarchical routing strategy: tokens are first assigned to a cluster, then to specific experts within it, drastically reducing the routing search space and the volume of all-to-all communication. Furthermore, a heterogeneous precision scheme, which stores shared bases in FP16 and residual factors in INT4, coupled with dynamic offloading of inactive clusters, reduces peak memory consumption to levels comparable to dense models. Evaluated on GLUE and WikiText-103, our framework matches the quality of standard MoE models while reducing total parameters by approximately 80%, improving throughput by 10% to 20%, and lowering expert load variance by a factor of over three. Our work demonstrates that structural reorganization is a principled path toward scalable, efficient, and memory-effective MoE LLMs.