$\texttt{BluePrint}$: A Social Media User Dataset for LLM Persona Evaluation and Training
作者: Aurélien Bück-Kaeffer, Je Qin Chooi, Dan Zhao, Maximilian Puelma Touzel, Kellin Pelrine, Jean-François Godbout, Reihaneh Rabbany, Zachary Yang
分类: cs.CL, cs.AI
发布日期: 2025-09-27
备注: 8 pages, 4 figures, 11 tables
💡 一句话要点
提出BluePrint数据集,用于评估和训练LLM在社交媒体用户建模中的Persona表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交媒体模拟 大型语言模型 Persona建模 行为预测 数据集构建
📋 核心要点
- 现有方法缺乏用于微调和评估LLM作为社交媒体代理的标准数据集,限制了社交媒体动态模拟研究。
- 提出SIMPACT框架,通过构建基于行为的、尊重隐私的社交媒体数据集,用于训练和评估LLM代理。
- 发布BluePrint数据集,包含政治讨论相关的Bluesky数据,可用于评估政治话语建模并作为构建其他领域数据集的模板。
📝 摘要(中文)
大型语言模型(LLMs)在模拟大规模社交媒体动态方面展现出巨大潜力,为伦理或后勤上难以通过人类受试者进行的研究提供了可能。然而,该领域缺乏标准化的数据资源来微调和评估LLM作为真实的社交媒体代理。为了解决这一问题,我们引入了SIMPACT,即面向模拟的Persona和行为捕获工具包,这是一个尊重隐私的框架,用于构建适合训练代理模型的、基于行为的社交媒体数据集。我们将下一个动作预测定义为训练和评估基于LLM的代理的任务,并引入了集群和群体层面的指标来评估行为保真度和风格真实性。作为一个具体的实现,我们发布了BluePrint,这是一个从公共Bluesky数据构建的大规模数据集,专注于政治讨论。BluePrint将匿名用户聚类成聚合行为的Persona,在通过假名化和删除个人身份信息来保护隐私的同时,捕获真实的参与模式。该数据集包括一个包含12种社交媒体互动类型(点赞、回复、转发等)的大型动作集,每个实例都与之前的发布活动相关联。这支持了代理的开发,这些代理不仅在语言上,而且在社交媒体的互动行为中使用上下文依赖性来建模社交媒体用户。通过标准化数据和评估协议,SIMPACT为推进严谨、符合伦理的社交媒体模拟奠定了基础。BluePrint既可以作为政治话语建模的评估基准,也可以作为构建特定领域数据集以研究诸如错误信息和两极分化等挑战的模板。
🔬 方法详解
问题定义:现有社交媒体模拟研究缺乏标准化的、高质量的数据集,用于训练和评估基于LLM的社交媒体代理。这阻碍了对社交媒体动态的深入研究,尤其是在伦理和后勤方面难以通过传统人类实验进行的研究。现有数据集可能存在隐私问题,或者缺乏足够的行为信息来训练具有真实行为模式的代理。
核心思路:论文的核心思路是构建一个尊重隐私、基于行为的社交媒体数据集,用于训练和评估LLM代理。通过将用户聚类成Persona,并捕获其社交媒体互动行为,可以训练出具有真实行为模式的代理,同时保护用户隐私。将下一个动作预测定义为训练和评估LLM代理的任务,并设计相应的评估指标。
技术框架:论文提出了SIMPACT框架,包含数据收集、用户聚类、行为捕获和评估等模块。首先,从公共社交媒体平台收集数据,并进行匿名化处理。然后,使用聚类算法将用户聚类成Persona,每个Persona代表一组具有相似行为模式的用户。接下来,捕获每个Persona的社交媒体互动行为,包括点赞、回复、转发等。最后,使用下一个动作预测任务来评估LLM代理的性能,并使用集群和群体层面的指标来评估行为保真度和风格真实性。
关键创新:论文的关键创新在于提出了SIMPACT框架,该框架能够构建尊重隐私、基于行为的社交媒体数据集,用于训练和评估LLM代理。此外,论文还提出了集群和群体层面的评估指标,用于评估LLM代理的行为保真度和风格真实性。BluePrint数据集的发布也为社交媒体模拟研究提供了一个重要的资源。
关键设计:BluePrint数据集包含12种社交媒体互动类型,每个实例都与之前的发布活动相关联,从而支持代理利用上下文依赖性进行建模。用户聚类采用匿名化处理,并删除个人身份信息,以保护用户隐私。评估指标包括集群层面的行为相似度和群体层面的行为分布相似度。
🖼️ 关键图片

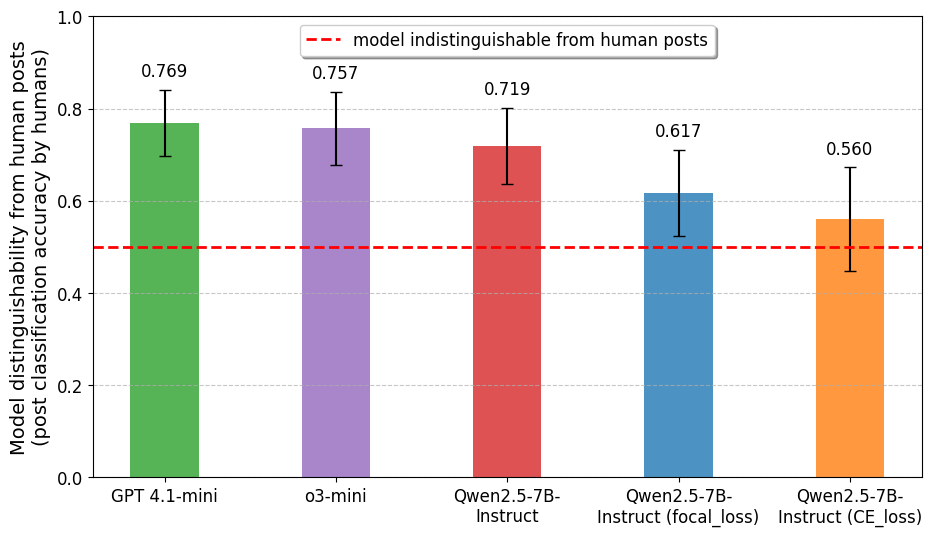
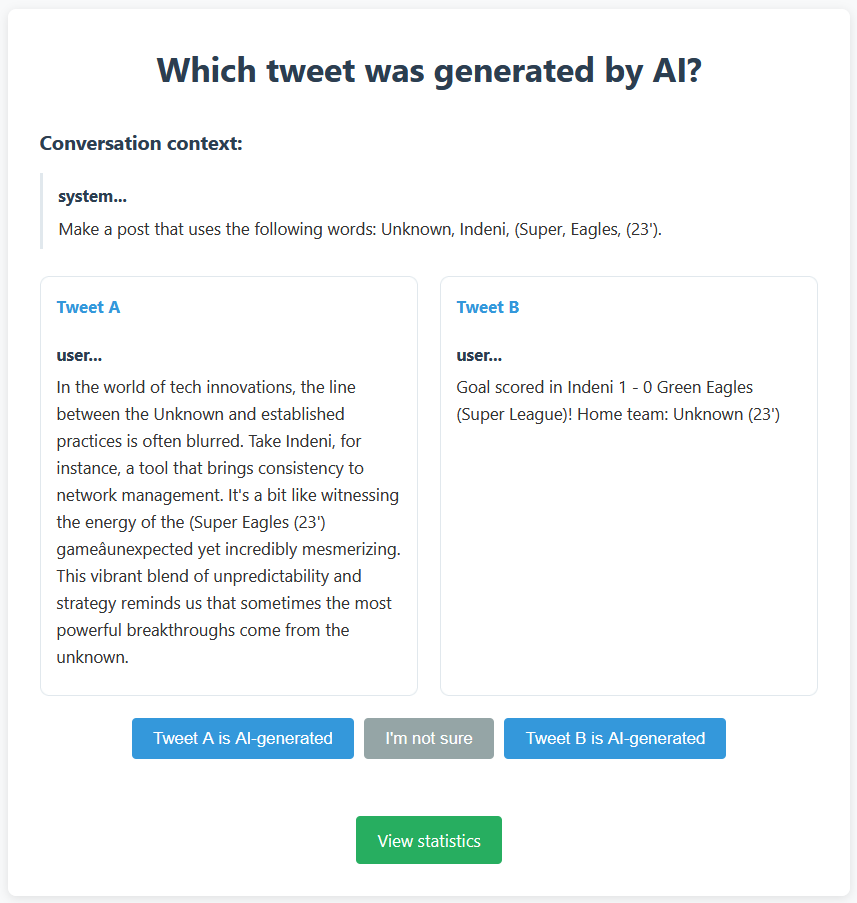
📊 实验亮点
论文发布了BluePrint数据集,该数据集包含大规模的Bluesky数据,涵盖政治讨论领域。该数据集包含12种社交媒体互动类型,并对用户进行了匿名化处理,保护了用户隐私。通过使用BluePrint数据集,可以训练出具有真实行为模式的LLM代理,并评估其在社交媒体模拟任务中的性能。具体的性能数据和对比基线将在后续研究中给出。
🎯 应用场景
该研究成果可应用于社交媒体动态模拟、舆情分析、虚假信息传播研究、个性化推荐系统等领域。通过训练具有真实行为模式的LLM代理,可以更准确地预测社交媒体用户的行为,从而为相关应用提供更可靠的支持。该数据集和评估框架也有助于推动社交媒体模拟研究的标准化和规范化。
📄 摘要(原文)
Large language models (LLMs) offer promising capabilities for simulating social media dynamics at scale, enabling studies that would be ethically or logistically challenging with human subjects. However, the field lacks standardized data resources for fine-tuning and evaluating LLMs as realistic social media agents. We address this gap by introducing SIMPACT, the SIMulation-oriented Persona and Action Capture Toolkit, a privacy respecting framework for constructing behaviorally-grounded social media datasets suitable for training agent models. We formulate next-action prediction as a task for training and evaluating LLM-based agents and introduce metrics at both the cluster and population levels to assess behavioral fidelity and stylistic realism. As a concrete implementation, we release BluePrint, a large-scale dataset built from public Bluesky data focused on political discourse. BluePrint clusters anonymized users into personas of aggregated behaviours, capturing authentic engagement patterns while safeguarding privacy through pseudonymization and removal of personally identifiable information. The dataset includes a sizable action set of 12 social media interaction types (likes, replies, reposts, etc.), each instance tied to the posting activity preceding it. This supports the development of agents that use context-dependence, not only in the language, but also in the interaction behaviours of social media to model social media users. By standardizing data and evaluation protocols, SIMPACT provides a foundation for advancing rigorous, ethically responsible social media simulations. BluePrint serves as both an evaluation benchmark for political discourse modeling and a template for building domain specific datasets to study challenges such as misinformation and polarization.