Comparison of Scoring Rationales Between Large Language Models and Human Raters
作者: Haowei Hua, Hong Jiao, Dan Song
分类: cs.CL, cs.LG
发布日期: 2025-09-27
备注: 23 Pages, 4 Tables, 13 Figures
💡 一句话要点
对比大型语言模型与人类评分者的评分理由,探究自动评分一致性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动评分 评分理由 一致性分析 教育评估
📋 核心要点
- 现有自动评分方法依赖于机器学习和自然语言处理,但对评分理由的理解不足,导致评分一致性难以保证。
- 本研究对比人类和LLM评分者的评分理由,通过分析理由的相似性和聚类模式,探究评分不一致的潜在原因。
- 实验结果表明,通过分析LLM的评分理由,可以深入了解其评分过程,从而改进自动评分系统的性能。
📝 摘要(中文)
自动评分的进步与机器学习和自然语言处理技术的进步密切相关。随着大型语言模型(LLM)的快速发展,ChatGPT、Gemini、Claude和其他生成式人工智能聊天机器人已被用于自动评分。鉴于LLM强大的推理能力,它们还可以生成评分理由来支持其分配的分数。因此,评估人类和LLM评分者提供的理由有助于更好地理解每种评分者在分配分数时应用的推理。本研究调查了人类和LLM评分者的理由,以识别评分不一致的潜在原因。使用来自大规模测试的论文,基于二次加权kappa和归一化互信息来检查GPT-4o、Gemini和其他LLM的评分准确性。使用余弦相似度来评估所提供理由的相似性。此外,使用基于理由嵌入的主成分分析来探索理由中的聚类模式。这项研究的结果为了解LLM在自动评分中的准确性和“思维”提供了见解,有助于提高对人类评分和基于LLM的自动评分背后的理由的理解。
🔬 方法详解
问题定义:论文旨在解决自动评分领域中,大型语言模型(LLM)与人类评分者在评分理由上存在差异,导致评分结果不一致的问题。现有方法缺乏对LLM评分过程的深入理解,难以解释和改进自动评分结果。
核心思路:论文的核心思路是通过对比分析LLM和人类评分者的评分理由,揭示两者在评分逻辑上的差异。通过量化评分理由的相似性,并探索理由的聚类模式,从而理解LLM的“思维”方式,并为改进自动评分系统提供依据。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:收集大规模测试中的论文及其人类评分和LLM评分;2) 评分理由生成:要求LLM为每个评分生成相应的评分理由;3) 相似性评估:使用余弦相似度计算人类和LLM评分理由之间的相似性;4) 聚类分析:使用主成分分析(PCA)对评分理由的嵌入进行降维,并进行聚类分析,探索理由的潜在模式;5) 准确性评估:使用二次加权kappa和归一化互信息评估LLM的评分准确性。
关键创新:论文的关键创新在于将评分理由作为理解LLM评分过程的桥梁,通过对比分析人类和LLM的评分理由,揭示了两者在评分逻辑上的差异。这种方法为改进自动评分系统提供了新的视角。
关键设计:论文的关键设计包括:1) 使用余弦相似度来量化评分理由的相似性,能够有效捕捉文本之间的语义关系;2) 使用主成分分析(PCA)进行降维,降低了计算复杂度,并保留了主要的信息;3) 使用二次加权kappa和归一化互信息作为评估指标,能够全面衡量LLM的评分准确性。
🖼️ 关键图片


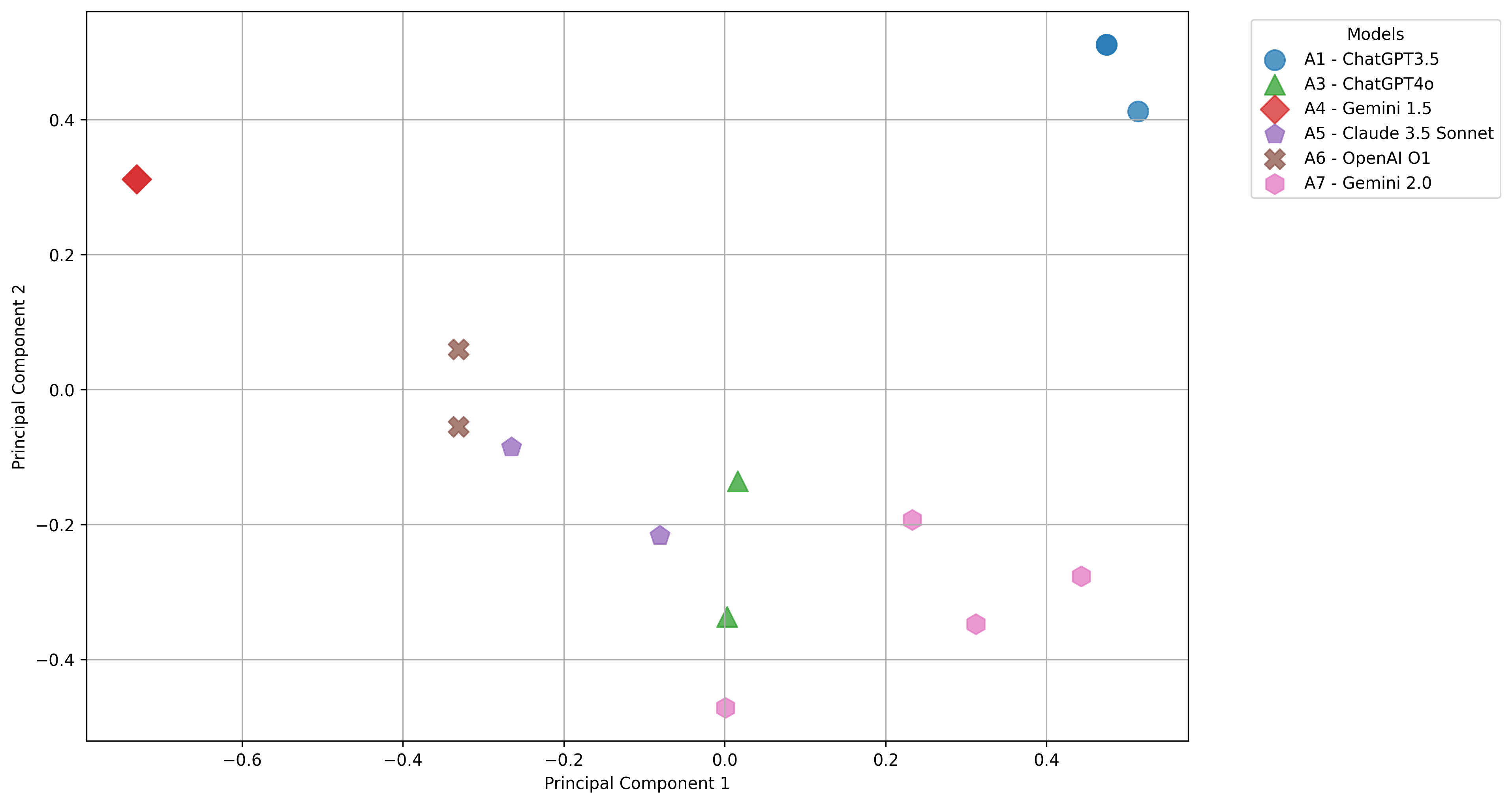
📊 实验亮点
研究通过实验验证了GPT-4o和Gemini等LLM在自动评分中的准确性,并分析了它们与人类评分者在评分理由上的差异。实验结果表明,LLM在某些方面能够达到与人类评分者相当的水平,但仍存在一定的偏差。通过分析评分理由,可以发现LLM的优势和不足,从而改进自动评分系统。
🎯 应用场景
该研究成果可应用于教育评估、论文评审、内容审核等领域。通过深入理解LLM的评分逻辑,可以开发更可靠、更公平的自动评分系统,提高评分效率,并为人类评分提供参考。此外,该研究还有助于提高人们对人工智能决策过程的理解,促进人机协作。
📄 摘要(原文)
Advances in automated scoring are closely aligned with advances in machine-learning and natural-language-processing techniques. With recent progress in large language models (LLMs), the use of ChatGPT, Gemini, Claude, and other generative-AI chatbots for automated scoring has been explored. Given their strong reasoning capabilities, LLMs can also produce rationales to support the scores they assign. Thus, evaluating the rationales provided by both human and LLM raters can help improve the understanding of the reasoning that each type of rater applies when assigning a score. This study investigates the rationales of human and LLM raters to identify potential causes of scoring inconsistency. Using essays from a large-scale test, the scoring accuracy of GPT-4o, Gemini, and other LLMs is examined based on quadratic weighted kappa and normalized mutual information. Cosine similarity is used to evaluate the similarity of the rationales provided. In addition, clustering patterns in rationales are explored using principal component analysis based on the embeddings of the rationales. The findings of this study provide insights into the accuracy and ``thinking'' of LLMs in automated scoring, helping to improve the understanding of the rationales behind both human scoring and LLM-based automated scoring.