MedCritical: Enhancing Medical Reasoning in Small Language Models via Self-Collaborative Correction
作者: Xinchun Su, Chunxu Luo, Yixuan Li, Weidong Yang, Lipeng Ma
分类: cs.CL, cs.AI
发布日期: 2025-09-27
💡 一句话要点
MedCritical:通过自协同校正增强小语言模型在医疗推理中的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学推理 小语言模型 知识蒸馏 自协同学习 直接偏好优化
📋 核心要点
- 小语言模型在复杂医学推理任务中表现不足,现有知识蒸馏方法成本高、效率低。
- MedCritical框架利用小语言模型自对抗学习,通过两阶段训练提升推理能力。
- 实验表明,MedCritical 7B模型在CMExam基准上超越其他7B模型,达到SOTA性能。
📝 摘要(中文)
在医学领域,临床诊断、治疗计划和医学知识整合等复杂推理任务极具挑战性,小语言模型在这方面的表现通常不如GPT-4和Deepseek等大型语言模型。最近基于知识蒸馏的方法旨在通过教师引导的错误纠正来解决这些问题,但这种将LLM作为评判者的方法在成本、时间和效率方面仍然具有挑战性。为了规避这个问题,我们提出了一种新颖的两阶段框架MedCritical,它使用由大型教师模型微调的小语言模型与自身进行对抗。在第一阶段,我们从教师模型中提取高层次和详细的长链思维模板,以指导学生模型生成更复杂的推理思维。在第二阶段,我们通过模型自迭代协作引入直接偏好优化(DPO),通过在训练期间与微调模型的校正轨迹进行对抗,来增强学生模型的推理能力。这种模型自学习DPO方法教导学生模型利用自身错误驱动的见解来巩固其技能和知识,从而解决复杂问题,并以较低的成本实现了与使用教师模型的传统知识蒸馏方法相当的结果。值得注意的是,我们的MedCritical 7B模型在CMExam基准测试中优于Taiyi和Huatuo-o1-7B模型,分别提高了3.04%和10.12%,在7B级别的小模型中实现了新的SOTA性能。
🔬 方法详解
问题定义:论文旨在解决小语言模型在复杂医学推理任务中表现不佳的问题。现有基于知识蒸馏的方法依赖大型语言模型作为教师,成本高昂且效率低下,难以在资源受限的环境中应用。
核心思路:论文的核心思路是利用小语言模型自身进行自协同校正,通过与自身微调后的模型进行对抗学习,提升推理能力。这种方法避免了对大型教师模型的依赖,降低了成本,并提高了效率。
技术框架:MedCritical框架包含两个主要阶段:1) 长链思维模板引导:从大型教师模型中提取高层次和详细的推理链模板,引导学生模型生成更复杂的推理过程。2) 自迭代DPO优化:通过直接偏好优化(DPO),让学生模型与自身微调后的模型进行对抗学习,从而学习到更好的推理策略。
关键创新:最重要的技术创新点是模型自学习的DPO方法。与传统的知识蒸馏方法不同,MedCritical不依赖外部教师模型,而是通过模型自身的错误驱动的见解来巩固技能和知识。这种自学习的方式更具成本效益,并且能够更好地适应特定任务的需求。
关键设计:在第一阶段,使用教师模型生成的高质量推理链作为模板,指导学生模型生成更复杂的推理过程。在第二阶段,使用DPO损失函数,鼓励学生模型生成更符合人类偏好的推理结果。具体来说,DPO损失函数基于学生模型和微调后的模型生成的推理轨迹之间的偏好差异进行优化。
🖼️ 关键图片


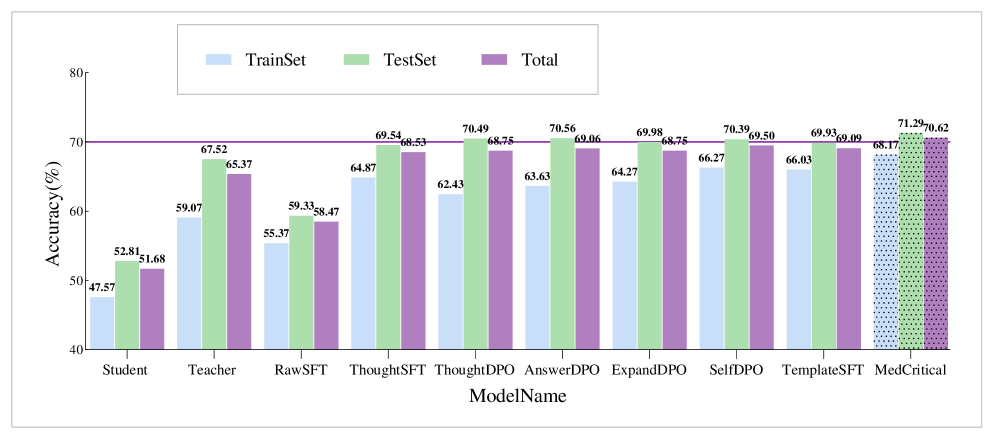
📊 实验亮点
MedCritical 7B模型在CMExam基准测试中取得了显著的性能提升,超越了Taiyi和Huatuo-o1-7B模型,分别提高了3.04%和10.12%,在7B级别的小模型中实现了新的SOTA性能。这表明MedCritical框架能够有效提升小语言模型在复杂医学推理任务中的能力。
🎯 应用场景
MedCritical框架可应用于医疗诊断辅助、治疗方案制定、医学知识问答等领域。该研究成果有助于提升小语言模型在医疗领域的应用价值,降低医疗AI的部署成本,并为资源受限的医疗机构提供更有效的AI解决方案。未来,该方法有望推广到其他需要复杂推理的领域。
📄 摘要(原文)
In the field of medicine, complex reasoning tasks such as clinical diagnosis, treatment planning, and medical knowledge integration pose significant challenges, where small language models often underperform compared to large language models like GPT-4 and Deepseek. Recent knowledge distillation-based methods aim to address these issues through teacher-guided error correction, but this LLM as judge approach remains challenging in terms of cost, time, and efficiency. To circumvent this issue, we propose a novel two-stage framework, MedCritical, which uses a small language model fine-tuned by a large teacher model to play against itself. In the first stage, we extract high-level and detailed long-chain thought templates from the teacher model to guide the student model to generate more complex reasoning thoughts. In the second stage, we introduce direct preference optimization (DPO) through model self-iteration collaboration to enhance the reasoning ability of the student model by playing against the correction trajectory of the fine-tuned model during training. This model self-learning DPO approach teaches the student model to use its own error-driven insights to consolidate its skills and knowledge to solve complex problems, and achieves comparable results to traditional knowledge distillation methods using teacher models at a lower cost. Notably, our MedCritical 7B model outperforms the Taiyi and Huatuo-o1-7B models by 3.04\% and 10.12\% respectively on the CMExam benchmark, achieving new SOTA performance among 7B-class small models.