Dual-Space Smoothness for Robust and Balanced LLM Unlearning
作者: Han Yan, Zheyuan Liu, Meng Jiang
分类: cs.CL, cs.AI
发布日期: 2025-09-27
备注: A unified framework that enforces dual-space smoothness in representation and parameter spaces to improve robustness and balance unlearning metrics
💡 一句话要点
PRISM:通过双空间平滑实现鲁棒且均衡的大语言模型不可学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 机器不可学习 隐私保护 鲁棒性 双空间平滑
📋 核心要点
- 现有大语言模型不可学习方法存在灾难性遗忘和指标不平衡问题,难以兼顾有效性、效用和隐私。
- PRISM框架通过在表示空间和参数空间中强制执行双空间平滑,提升模型鲁棒性并平衡各项指标。
- 实验表明,PRISM在多种攻击下优于现有方法,并在关键指标间取得了更好的平衡。
📝 摘要(中文)
随着大型语言模型的快速发展,机器不可学习(Machine Unlearning)已成为解决用户隐私、版权侵犯和整体安全等日益增长的担忧的关键技术。然而,目前最先进的不可学习方法通常遭受灾难性遗忘和指标不平衡的困扰,例如,以牺牲其他目标(如不可学习有效性、效用保持或隐私保护)为代价过度优化一个目标。此外,表示或参数空间中的微小扰动可能被重新学习(relearn)和越狱攻击(jailbreak attacks)利用。为了应对这些挑战,我们提出了PRISM,一个统一的框架,它在表示和参数空间中强制执行双空间平滑,以提高鲁棒性并平衡不可学习指标。PRISM包含两个平滑优化阶段:(i)表示空间阶段,采用鲁棒训练的探针来防御越狱攻击;(ii)参数空间阶段,解耦保留-遗忘梯度冲突,减少不平衡,并平滑参数空间以减轻重新学习攻击。在WMDP和MUSE上,跨越对话和连续文本设置的大量实验表明,在多种攻击下,PRISM优于SOTA基线,同时在关键指标之间实现了更好的平衡。
🔬 方法详解
问题定义:现有的大语言模型不可学习方法在追求遗忘效果的同时,容易导致模型性能下降(灾难性遗忘),并且难以在遗忘效果、模型效用和隐私保护之间取得平衡。此外,模型容易受到重新学习攻击和越狱攻击,安全性不足。
核心思路:PRISM的核心思路是通过在模型的表示空间和参数空间中引入平滑性约束,来提高模型的鲁棒性和平衡性。表示空间平滑旨在防御越狱攻击,参数空间平滑旨在减轻重新学习攻击,同时解耦保留-遗忘梯度冲突,从而更好地平衡各项指标。
技术框架:PRISM框架包含两个主要阶段:表示空间平滑和参数空间平滑。在表示空间平滑阶段,使用鲁棒训练的探针来学习对输入扰动不敏感的表示。在参数空间平滑阶段,通过解耦保留数据和遗忘数据的梯度,并对参数空间进行平滑处理,来减少重新学习攻击的风险。整体流程是先进行表示空间平滑,再进行参数空间平滑。
关键创新:PRISM的关键创新在于提出了双空间平滑的概念,并将其应用于大语言模型的不可学习任务中。通过同时在表示空间和参数空间中引入平滑性约束,可以有效地提高模型的鲁棒性和平衡性,从而缓解现有方法中存在的灾难性遗忘、指标不平衡和安全性不足等问题。
关键设计:在表示空间平滑阶段,使用对抗训练来增强探针的鲁棒性,使其对输入扰动不敏感。在参数空间平滑阶段,使用梯度手术(Gradient Surgery)等技术来解耦保留数据和遗忘数据的梯度,避免相互干扰。此外,还可能使用正则化方法来平滑参数空间,例如权重衰减或谱归一化。
🖼️ 关键图片
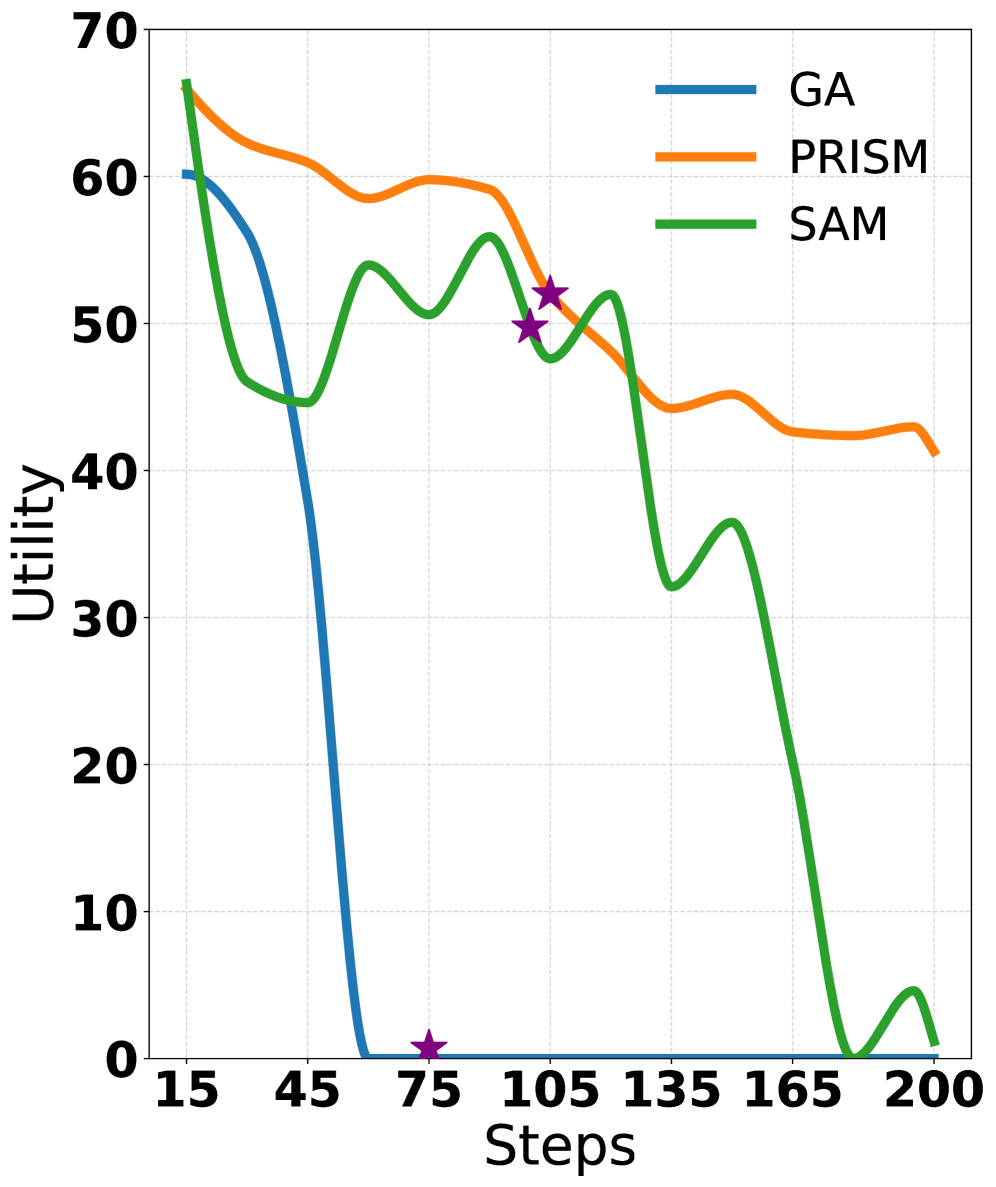


📊 实验亮点
PRISM在WMDP和MUSE数据集上进行了广泛的实验,结果表明PRISM在多种攻击下均优于SOTA基线。具体来说,PRISM在不可学习有效性、效用保持和隐私保护等指标上都取得了显著的提升,并且在这些指标之间实现了更好的平衡。实验结果验证了PRISM框架的有效性和优越性。
🎯 应用场景
PRISM框架可应用于各种需要保护用户隐私、版权或模型安全的场景,例如:在线教育、智能客服、金融风控等。通过不可学习技术,可以安全地删除模型中与特定用户或数据相关的知识,避免信息泄露和侵权风险,提升用户信任度和数据安全性,促进人工智能技术的健康发展。
📄 摘要(原文)
With the rapid advancement of large language models, Machine Unlearning has emerged to address growing concerns around user privacy, copyright infringement, and overall safety. Yet state-of-the-art (SOTA) unlearning methods often suffer from catastrophic forgetting and metric imbalance, for example by over-optimizing one objective (e.g., unlearning effectiveness, utility preservation, or privacy protection) at the expense of others. In addition, small perturbations in the representation or parameter space can be exploited by relearn and jailbreak attacks. To address these challenges, we propose PRISM, a unified framework that enforces dual-space smoothness in representation and parameter spaces to improve robustness and balance unlearning metrics. PRISM consists of two smoothness optimization stages: (i) a representation space stage that employs a robustly trained probe to defend against jailbreak attacks, and (ii) a parameter-space stage that decouples retain-forget gradient conflicts, reduces imbalance, and smooths the parameter space to mitigate relearning attacks. Extensive experiments on WMDP and MUSE, across conversational-dialogue and continuous-text settings, show that PRISM outperforms SOTA baselines under multiple attacks while achieving a better balance among key metrics.