Detecting Corpus-Level Knowledge Inconsistencies in Wikipedia with Large Language Models
作者: Sina J. Semnani, Jirayu Burapacheep, Arpandeep Khatua, Thanawan Atchariyachanvanit, Zheng Wang, Monica S. Lam
分类: cs.CL
发布日期: 2025-09-27
备注: EMNLP 2025 (Main Conference)
💡 一句话要点
提出CLAIRE系统,检测维基百科语料库级别知识不一致性,提升编辑效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识不一致性检测 大型语言模型 维基百科 信息检索 智能代理
📋 核心要点
- 维基百科作为重要知识来源,其准确性至关重要,但现有方法难以有效检测语料库级别的知识不一致性。
- 论文提出CLAIRE系统,利用LLM推理和检索,自动发现潜在的不一致性,并提供上下文证据辅助人工审查。
- 实验表明,CLAIRE显著提升了维基百科编辑识别不一致性的效率和信心,并构建了首个维基百科不一致性基准WIKICOLLIDE。
📝 摘要(中文)
维基百科是最大的开放知识语料库,被广泛使用,是训练大型语言模型(LLM)和检索增强生成(RAG)系统的关键资源。确保其准确性至关重要。本文关注不一致性,一种特殊的factual不准确类型,并引入了语料库级别不一致性检测的任务。我们提出了CLAIRE,一个agentic系统,它结合了LLM推理和检索,以发现潜在的不一致性声明以及上下文证据,供人工审查。在一项与经验丰富的维基百科编辑的用户研究中,87.5%的人报告在使用CLAIRE时信心更高,参与者在相同的时间内识别出64.7%更多的不一致性。结合CLAIRE和人工标注,我们贡献了WIKICOLLIDE,这是第一个真实的维基百科不一致性基准。通过使用CLAIRE辅助分析的随机抽样,我们发现至少3.3%的英语维基百科事实与另一个事实相矛盾,不一致性传播到7.3%的FEVEROUS和4.0%的AmbigQA示例中。对该数据集上的强大基线进行基准测试表明,存在很大的提升空间:最佳的完全自动化系统仅达到75.1%的AUROC。
🔬 方法详解
问题定义:论文旨在解决维基百科等大型知识库中存在的语料库级别知识不一致性问题。现有方法主要依赖人工审核,效率低下且难以覆盖所有内容。此外,现有自动化方法在处理复杂上下文和推理方面存在局限性,导致检测准确率较低。
核心思路:论文的核心思路是利用大型语言模型(LLM)的推理能力和信息检索技术,构建一个智能代理系统(CLAIRE),自动识别潜在的不一致性。CLAIRE通过检索相关上下文信息,并利用LLM进行推理,判断不同信息之间是否存在矛盾。这种方法旨在模拟人工审核的过程,提高检测效率和准确率。
技术框架:CLAIRE系统主要包含以下几个模块:1) 信息检索模块:根据给定的声明,从维基百科中检索相关的上下文信息。2) LLM推理模块:利用LLM对声明和检索到的上下文信息进行推理,判断是否存在矛盾。3) 证据呈现模块:将潜在的不一致性声明和相关的上下文证据呈现给人工审核员。整个流程旨在辅助人工审核,提高效率和准确性。
关键创新:论文的关键创新在于将LLM的推理能力与信息检索技术相结合,构建了一个智能代理系统,用于自动检测语料库级别的知识不一致性。与现有方法相比,CLAIRE能够更好地处理复杂上下文和推理,从而提高检测准确率。此外,论文还构建了首个维基百科不一致性基准WIKICOLLIDE,为后续研究提供了数据基础。
关键设计:CLAIRE系统在设计上注重实用性和可扩展性。在信息检索模块中,采用了高效的检索算法,以保证检索速度。在LLM推理模块中,采用了预训练的LLM模型,并针对知识不一致性检测任务进行了微调。在证据呈现模块中,采用了清晰易懂的界面设计,方便人工审核员进行判断。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片


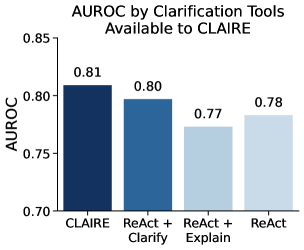
📊 实验亮点
实验结果表明,使用CLAIRE系统后,维基百科编辑的信心提高了87.5%,在相同时间内识别出的不一致性增加了64.7%。通过CLAIRE辅助分析,发现至少3.3%的英语维基百科事实存在矛盾。在WIKICOLLIDE基准测试中,最佳自动化系统仅达到75.1%的AUROC,表明仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于大规模知识库的质量控制,例如维基百科、知识图谱等。通过自动检测和修复知识不一致性,可以提高知识库的准确性和可靠性,从而提升下游应用(如问答系统、搜索引擎)的性能。未来,该技术还可应用于自动知识库构建和维护,降低人工成本。
📄 摘要(原文)
Wikipedia is the largest open knowledge corpus, widely used worldwide and serving as a key resource for training large language models (LLMs) and retrieval-augmented generation (RAG) systems. Ensuring its accuracy is therefore critical. But how accurate is Wikipedia, and how can we improve it? We focus on inconsistencies, a specific type of factual inaccuracy, and introduce the task of corpus-level inconsistency detection. We present CLAIRE, an agentic system that combines LLM reasoning with retrieval to surface potentially inconsistent claims along with contextual evidence for human review. In a user study with experienced Wikipedia editors, 87.5% reported higher confidence when using CLAIRE, and participants identified 64.7% more inconsistencies in the same amount of time. Combining CLAIRE with human annotation, we contribute WIKICOLLIDE, the first benchmark of real Wikipedia inconsistencies. Using random sampling with CLAIRE-assisted analysis, we find that at least 3.3% of English Wikipedia facts contradict another fact, with inconsistencies propagating into 7.3% of FEVEROUS and 4.0% of AmbigQA examples. Benchmarking strong baselines on this dataset reveals substantial headroom: the best fully automated system achieves an AUROC of only 75.1%. Our results show that contradictions are a measurable component of Wikipedia and that LLM-based systems like CLAIRE can provide a practical tool to help editors improve knowledge consistency at scale.