A Structured Framework for Evaluating and Enhancing Interpretive Capabilities of Multimodal LLMs in Culturally Situated Tasks
作者: Haorui Yu, Ramon Ruiz-Dolz, Qiufeng Yi
分类: cs.CL
发布日期: 2025-09-27 (更新: 2026-01-31)
备注: EMNLP 2025 submission, 10 pages, 6 figures, 5 tables
期刊: Findings of the Association for Computational Linguistics: EMNLP 2025, pages 1945-1971, Suzhou, China
DOI: 10.18653/v1/2025.findings-emnlp.103
🔗 代码/项目: GITHUB
💡 一句话要点
构建结构化框架,提升多模态LLM在中国文化情境下的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 文化情境理解 艺术评论生成 零样本学习
📋 核心要点
- 现有视觉语言模型在文化情境下的理解能力不足,尤其是在生成具有文化背景的评论时。
- 论文提出一个量化框架,通过提取专家评论的多维特征来定义评论角色,并以此引导VLM生成评论。
- 实验评估了Llama、Qwen、Gemini等VLM在生成中国绘画评论方面的表现,揭示了它们的优势和不足。
📝 摘要(中文)
本研究旨在测试和评估当前主流视觉语言模型(VLM)在生成中国传统绘画评论方面的能力和特点。为此,我们首先开发了一个用于中国绘画评论的量化框架。该框架通过使用零样本分类模型,从人类专家评论中提取多维评估特征,包括评估立场、特征关注点和评论质量。基于这些特征,定义并量化了几个具有代表性的评论角色。然后,该框架被用于评估选定的VLM,如Llama、Qwen或Gemini。实验设计包括角色引导提示,以评估VLM从不同角度生成评论的能力。我们的发现揭示了当前VLM在艺术评论领域的性能水平、优势和改进领域,为它们在复杂语义理解和内容生成任务中的潜力和局限性提供了见解。实验代码可在https://github.com/yha9806/VULCA-EMNLP2025公开获取。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在理解和评论具有深厚文化背景的艺术作品时表现出的不足。现有方法缺乏对文化情境的深入理解,导致生成的评论缺乏专业性和针对性,难以满足文化领域的需求。特别是在中国传统绘画评论方面,VLM需要理解绘画的风格、意境、历史背景等多方面信息,才能生成高质量的评论。
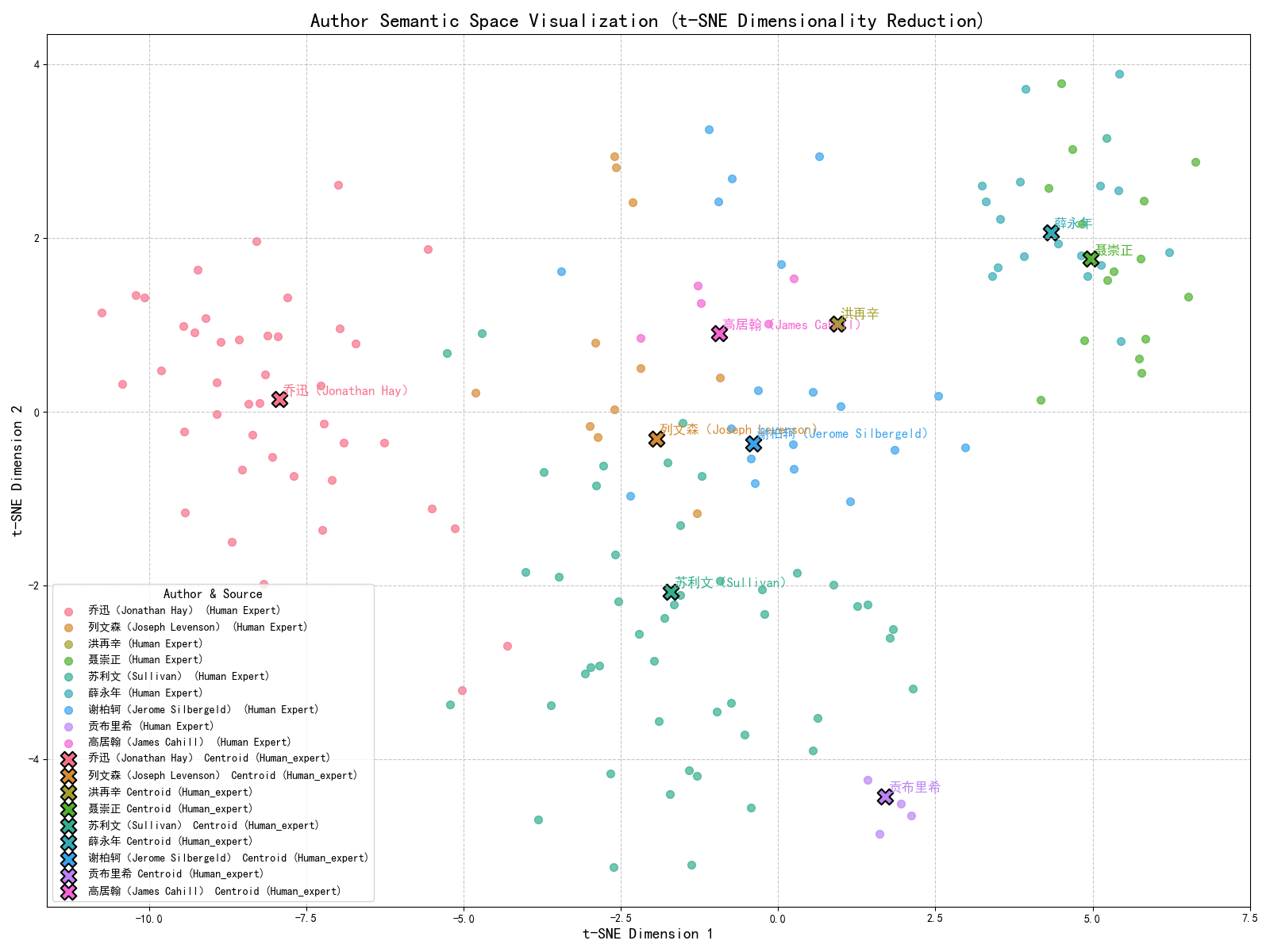
核心思路:论文的核心思路是通过构建一个量化的评估框架,将专家对中国绘画的评论分解为多个可量化的特征维度,例如评估立场(积极、消极、中立)、特征关注点(笔墨、意境、构图)和评论质量(深度、广度、准确性)。然后,基于这些特征定义不同的评论角色,并利用这些角色引导VLM生成评论。这种方法旨在使VLM能够模仿专家的思维方式,从而生成更具专业性和文化敏感性的评论。
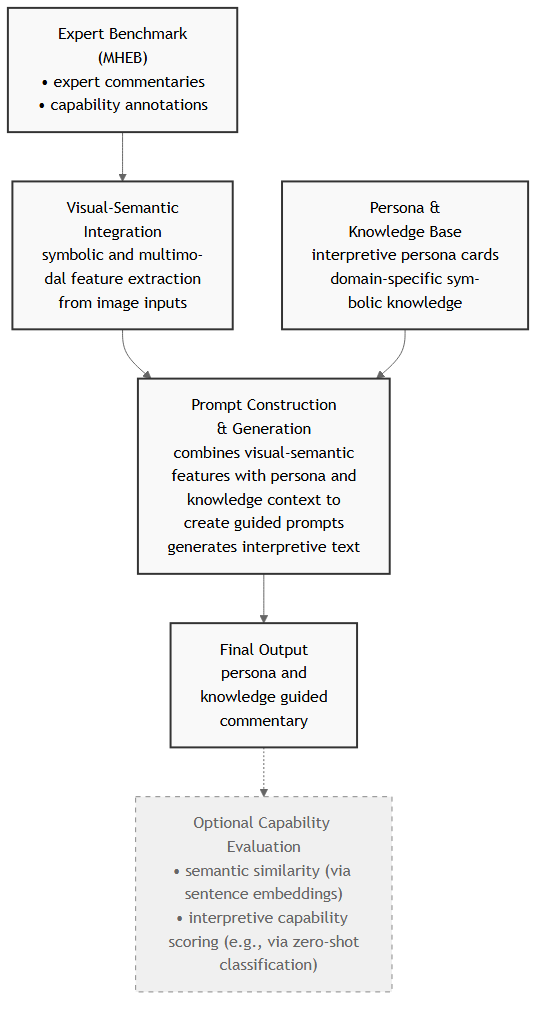
技术框架:整体框架包括以下几个主要模块:1) 数据收集与预处理:收集中国绘画专家评论数据,并进行清洗和标注。2) 特征提取:使用零样本分类模型从专家评论中提取多维评估特征。3) 角色定义与量化:基于提取的特征,定义具有代表性的评论角色,并对每个角色进行量化描述。4) 角色引导提示:设计角色引导提示,引导VLM生成特定角色的评论。5) VLM评估:使用量化框架评估VLM生成的评论质量。
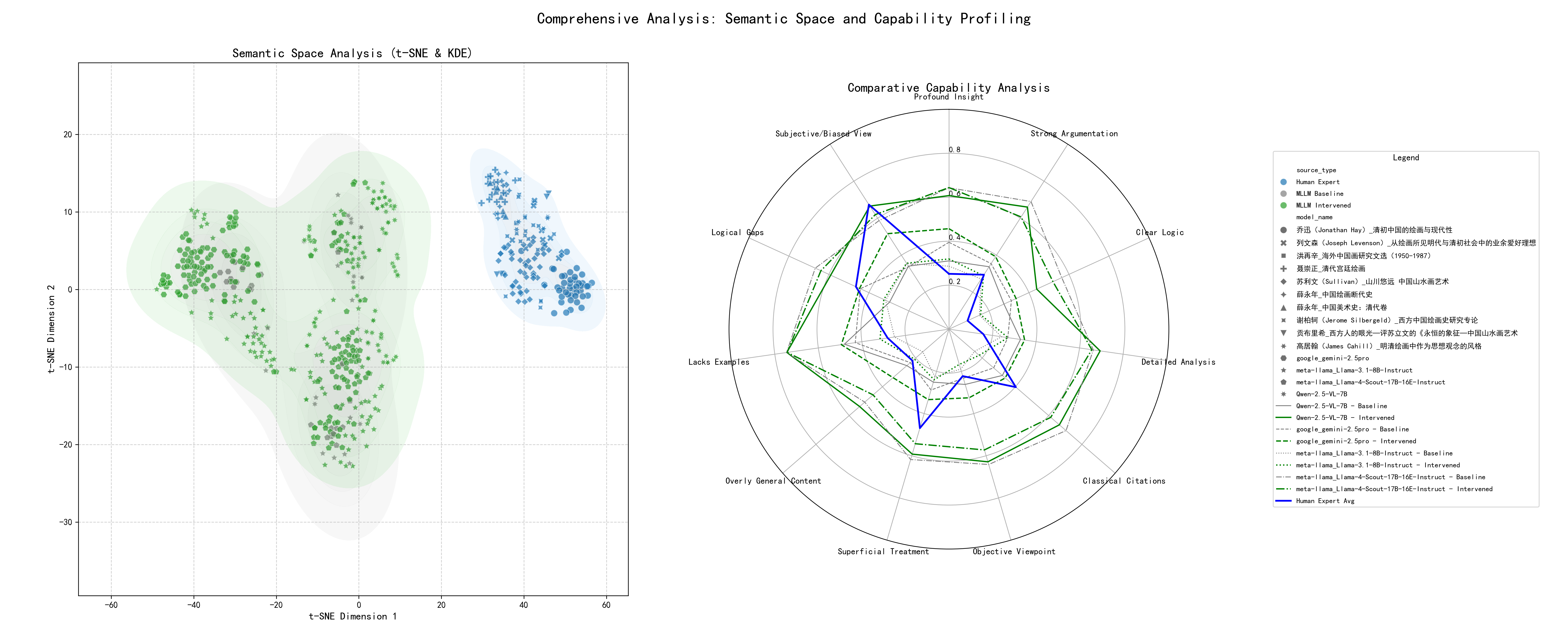
关键创新:论文的关键创新在于提出了一个结构化的、可量化的框架,用于评估和提升VLM在文化情境下的理解能力。该框架不仅能够量化专家评论的特征,还能够将这些特征用于引导VLM生成评论,从而提高了VLM生成评论的质量和专业性。与现有方法相比,该框架更加注重文化情境的理解,能够更好地适应文化领域的需求。
关键设计:在特征提取方面,论文使用了零样本分类模型,避免了人工标注的成本。在角色定义方面,论文根据专家评论的特征,定义了多个具有代表性的评论角色,例如“注重笔墨的评论家”、“注重意境的评论家”等。在角色引导提示方面,论文设计了特定的提示语,引导VLM模仿特定角色的思维方式。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过角色引导提示,VLM能够生成具有不同风格和观点的中国绘画评论。该框架能够有效评估VLM在艺术评论领域的性能水平,并揭示其优势和不足。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。代码已开源,方便后续研究。
🎯 应用场景
该研究成果可应用于艺术评论生成、文化遗产保护、文化教育等领域。通过提升VLM在文化情境下的理解能力,可以自动生成高质量的艺术评论,辅助文化遗产的数字化保护和传播,并为文化教育提供个性化的学习资源。未来,该方法有望扩展到其他文化领域,促进人工智能在文化领域的应用。
📄 摘要(原文)
This study aims to test and evaluate the capabilities and characteristics of current mainstream Visual Language Models (VLMs) in generating critiques for traditional Chinese painting. To achieve this, we first developed a quantitative framework for Chinese painting critique. This framework was constructed by extracting multi-dimensional evaluative features covering evaluative stance, feature focus, and commentary quality from human expert critiques using a zero-shot classification model. Based on these features, several representative critic personas were defined and quantified. This framework was then employed to evaluate selected VLMs such as Llama, Qwen, or Gemini. The experimental design involved persona-guided prompting to assess the VLM's ability to generate critiques from diverse perspectives. Our findings reveal the current performance levels, strengths, and areas for improvement of VLMs in the domain of art critique, offering insights into their potential and limitations in complex semantic understanding and content generation tasks. The code used for our experiments can be publicly accessed at: https://github.com/yha9806/VULCA-EMNLP2025.