PARL-MT: Learning to Call Functions in Multi-Turn Conversation with Progress Awareness
作者: Huacan Chai, Zijie Cao, Maolin Ran, Yingxuan Yang, Jianghao Lin, Xin Peng, Hairui Wang, Renjie Ding, Ziyu Wan, Muning Wen, Weiwen Liu, Weinan Zhang, Fei Huang, Ying Wen
分类: cs.CL, cs.AI
发布日期: 2025-09-27 (更新: 2025-10-09)
💡 一句话要点
PARL-MT:通过进度感知学习在多轮对话中进行函数调用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮对话 函数调用 大型语言模型 强化学习 进度感知 任务规划 对话摘要
📋 核心要点
- 现有方法在多轮对话函数调用中,要么忽略任务级规划,要么使用端到端强化学习,存在冗余和缺乏进度感知的问题。
- PARL-MT框架通过进度感知生成(PAG)和进度感知引导的强化学习(PAG-RL),显式地将进度感知融入LLM训练中。
- 实验结果表明,PARL-MT在两个公共基准上显著优于现有方法,验证了进度感知在多轮函数调用中的有效性。
📝 摘要(中文)
大型语言模型(LLMs)在单轮函数调用中取得了显著成功,但旅行规划或多阶段数据分析等实际应用通常发生在多轮对话中。在这些场景中,LLMs不仅需要在每个步骤发出准确的函数调用,还需要保持进度感知,即总结过去交互并规划未来行动的能力,以确保连贯的长程任务执行。然而,现有方法要么将多轮训练简化为孤立的单轮样本,忽略了任务级规划,要么采用端到端强化学习(RL),这难以处理冗余并且缺乏对进度感知的显式整合。为了克服这些限制,我们引入了PARL-MT,一个将进度感知显式地融入到LLM多轮函数调用训练中的框架。PARL-MT结合了(i)进度感知生成(PAG)流程,该流程自动构建将对话摘要与未来任务规划相结合的数据集,以及(ii)进度感知引导的强化学习(PAG-RL)算法,该算法将进度感知集成到RL训练中,以减少上下文冗余并改善局部动作与全局任务完成之间的一致性。在两个公共基准上的实验结果表明,PARL-MT显著优于现有方法,突出了进度感知在实现鲁棒且高效的多轮函数调用方面的有效性。
🔬 方法详解
问题定义:论文旨在解决多轮对话场景下,大型语言模型进行函数调用时缺乏任务级规划和进度感知的问题。现有方法要么将多轮对话简化为单轮样本,忽略了上下文信息和长期规划,要么采用端到端强化学习,但容易产生冗余,且无法有效整合进度感知。
核心思路:论文的核心思路是显式地将进度感知融入到LLM的训练过程中。通过让模型学习对话的摘要和未来的任务规划,从而提高模型在多轮对话中进行函数调用的准确性和效率。这种方法旨在弥合局部动作和全局任务完成之间的差距,减少上下文冗余。
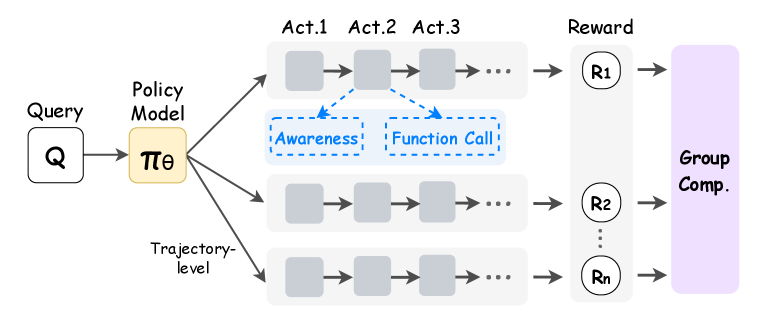
技术框架:PARL-MT框架包含两个主要模块:进度感知生成(PAG)和进度感知引导的强化学习(PAG-RL)。PAG模块负责自动构建数据集,该数据集包含对话摘要和未来任务规划。PAG-RL模块则将进度感知信息整合到强化学习训练过程中,以指导模型的动作选择。整体流程是先通过PAG生成训练数据,然后使用PAG-RL对LLM进行训练。
关键创新:该论文的关键创新在于显式地引入了进度感知的概念,并将其融入到LLM的多轮函数调用训练中。与现有方法相比,PARL-MT不仅关注当前的对话状态,还考虑了历史对话信息和未来的任务规划,从而提高了模型在复杂多轮对话场景下的表现。PAG和PAG-RL的结合,使得模型能够更好地理解对话的上下文,并做出更合理的函数调用。
关键设计:PAG流程的具体实现细节未知,但其核心目标是生成包含对话摘要和未来任务规划的数据集。PAG-RL算法的关键在于如何将进度感知信息有效地融入到强化学习的奖励函数或状态表示中。具体的参数设置、损失函数和网络结构等细节在论文摘要中未提及,需要查阅论文全文才能了解。
🖼️ 关键图片


📊 实验亮点
PARL-MT在两个公共基准测试中显著优于现有方法,证明了其有效性。具体的性能数据和提升幅度需要在论文中查找。该结果表明,显式地引入进度感知可以显著提高LLM在多轮对话函数调用任务中的表现。
🎯 应用场景
PARL-MT的研究成果可应用于各种需要多轮对话和函数调用的场景,例如智能助手、旅行规划、数据分析等。通过提高LLM在多轮对话中的函数调用能力,可以实现更智能、更高效的人机交互,并为用户提供更便捷的服务。该研究还有助于推动LLM在实际应用中的落地。
📄 摘要(原文)
Large language models (LLMs) have achieved impressive success in single-turn function calling, yet real-world applications such as travel planning or multi-stage data analysis typically unfold across multi-turn conversations. In these settings, LLMs must not only issue accurate function calls at each step but also maintain progress awareness, the ability to summarize past interactions and plan future actions to ensure coherent, long-horizon task execution. Existing approaches, however, either reduce multi-turn training to isolated single-turn samples, which neglects task-level planning, or employ end-to-end reinforcement learning (RL) that struggles with redundancy and lacks explicit integration of progress awareness. To overcome these limitations, we introduce PARL-MT, a framework that explicitly incorporates progress awareness into LLM training for multi-turn function calling. PARL-MT combines (i) a Progress Awareness Generation (PAG) pipeline, which automatically constructs datasets coupling conversation summaries with future task planning, and (ii) a Progress Awareness-Guided Reinforcement Learning (PAG-RL) algorithm, which integrates progress awareness into RL training to reduce contextual redundancy and improve alignment between local actions and global task completion. Empirical results on two public benchmarks demonstrate that PARL-MT significantly outperforms existing methods, highlighting the effectiveness of progress awareness in enabling robust and efficient multi-turn function calling.