Test-Time Policy Adaptation for Enhanced Multi-Turn Interactions with LLMs
作者: Chenxing Wei, Hong Wang, Ying He, Fei Yu, Yao Shu
分类: cs.CL
发布日期: 2025-09-27
备注: 32 pages, 7 figures
💡 一句话要点
提出测试时策略自适应(T2PAM)框架,增强LLM多轮交互中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多轮交互 策略自适应 用户反馈 在线学习
📋 核心要点
- 现有LLM在静态数据上训练,难以适应多轮交互中用户的实时反馈,导致性能下降。
- 提出T2PAM框架,利用用户反馈作为奖励信号,估计最优策略并更新模型参数。
- ROSA算法以单步更新方式实现T2PAM,避免迭代优化,实验证明其有效性和效率。
📝 摘要(中文)
大型语言模型(LLMs)采用多轮交互作为完成复杂任务的基本范例。然而,由于它们通常在静态的单轮数据上进行训练,因此在扩展的交互中,它们的性能经常会下降,这阻碍了它们适应实时用户反馈的能力。为了解决这个限制,我们首先提出了一种新的范例:多轮交互的测试时策略自适应(T2PAM),它利用来自正在进行的交互的用户反馈作为奖励信号,以估计与用户偏好对齐的潜在最优策略,然后更新一小部分参数,以引导模型朝着这个策略发展,最终实现高效的对话内自我纠正。然后,我们引入了最优参考单步自适应(ROSA),这是一种轻量级算法,用于实现T2PAM。ROSA在一个高效的更新步骤中将模型参数引导到理论上的最优策略,避免了代价高昂的迭代梯度优化,并最大限度地减少了计算开销。我们提供了严格的理论分析,保证ROSA的策略随着交互次数的增加而收敛到用户的偏好。在具有挑战性的基准上进行的大量实验表明,ROSA在任务有效性和效率方面都取得了显著的改进。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在多轮交互中性能下降的问题。现有的LLMs通常在静态的、单轮的数据上进行训练,这使得它们难以适应用户在对话过程中的实时反馈,从而导致在长时间的交互中表现不佳。痛点在于缺乏一种有效的机制,使LLMs能够根据用户的偏好进行自我修正和优化。
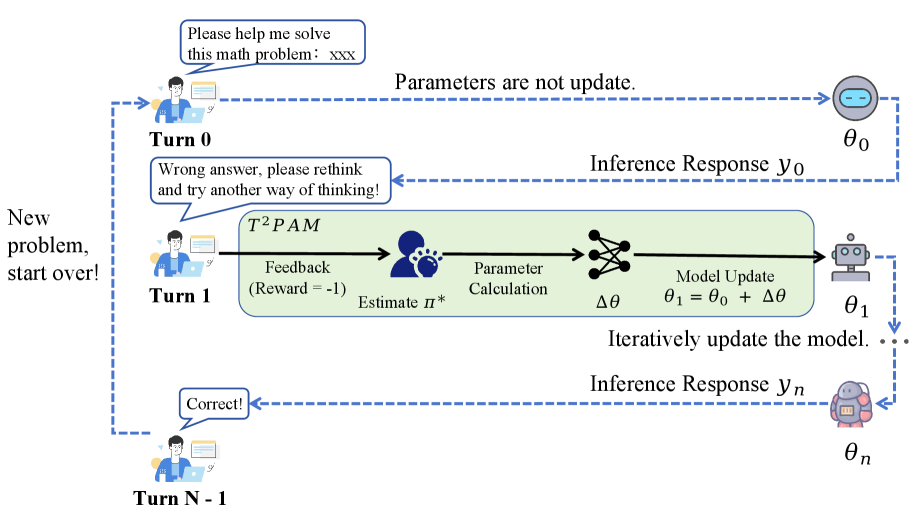
核心思路:论文的核心思路是引入测试时策略自适应(Test-Time Policy Adaptation,T2PAM)框架。该框架利用用户在交互过程中提供的反馈作为奖励信号,以此来估计一个与用户偏好对齐的潜在最优策略。然后,通过更新模型的一小部分参数,引导模型朝着这个最优策略的方向发展,从而实现对话内的自我纠正。这种方法的关键在于将用户反馈转化为可用于模型优化的信号。
技术框架:T2PAM框架的核心是利用用户反馈来优化LLM的策略。具体而言,该框架包含以下几个主要步骤:1) 在多轮交互过程中,收集用户对LLM输出的反馈。2) 将用户反馈转化为奖励信号,用于评估当前策略的优劣。3) 基于奖励信号,估计一个与用户偏好对齐的潜在最优策略。4) 使用ROSA算法,通过单步更新的方式,调整模型参数,使其朝着最优策略的方向发展。ROSA算法避免了传统的迭代梯度优化,降低了计算成本。
关键创新:论文最重要的技术创新点在于提出了T2PAM框架和ROSA算法。T2PAM框架提供了一种新的范式,允许LLMs在测试时根据用户反馈进行策略自适应。ROSA算法则是一种轻量级的实现方式,它通过单步更新将模型参数引导到理论上的最优策略,避免了昂贵的迭代优化。与现有方法相比,T2PAM和ROSA能够更有效地利用用户反馈,实现对话内的自我纠正,并且计算成本更低。
关键设计:ROSA算法的关键设计在于如何将用户反馈转化为有效的奖励信号,并利用该信号来更新模型参数。具体而言,ROSA算法通过计算当前策略与最优策略之间的差异,然后利用该差异来调整模型参数。这种调整是通过一个单步更新来实现的,避免了迭代优化。此外,论文还提供了理论分析,证明ROSA算法的策略随着交互次数的增加而收敛到用户的偏好。具体的参数设置和损失函数细节在论文中有详细描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ROSA算法在任务有效性和效率方面都取得了显著的改进。具体性能数据和对比基线在摘要中未提供,但强调了ROSA在具有挑战性的基准测试中表现出色,证明了T2PAM框架和ROSA算法的有效性。
🎯 应用场景
该研究成果可应用于各种需要与用户进行多轮交互的LLM应用场景,例如智能客服、对话式AI助手、个性化推荐系统等。通过实时学习用户偏好,提升交互质量和用户满意度,具有重要的实际应用价值和商业潜力。未来可进一步探索更复杂的奖励信号设计和更高效的参数更新方法。
📄 摘要(原文)
Large Language Models (LLMs) employ multi-turn interaction as a fundamental paradigm for completing complex tasks. However, their performance often degrades in extended interactions, as they are typically trained on static, single-turn data, which hinders their ability to adapt to real-time user feedback. To address this limitation, we first propose a new paradigm: Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM), which utilizes user feedback from the ongoing interaction as a reward signal to estimate a latent optimal policy aligned with user preferences, then updates a small subset of parameters to steer the model toward this policy, ultimately enabling efficient in-conversation self-correction. We then introduce Optimum-Referenced One-Step Adaptation (ROSA), a lightweight algorithm that operationalizes T2PAM. ROSA guides the model parameters toward a theoretical optimal policy in a single, efficient update step, avoiding costly iterative gradient-based optimization and minimizing computational overhead. We provide a rigorous theoretical analysis guaranteeing that the policy of ROSA converges to the preference of user as the number of interactions increases. Extensive experiments on challenging benchmark demonstrate that ROSA achieves significant improvements in both task effectiveness and efficiency.