Tagging the Thought: Unlocking Personalization Reasoning via Reinforcement Learning
作者: Song Jin, Juntian Zhang, Yong Liu, Xun Zhang, Yufei Zhang, Fei Jiang, Guojun Yin, Wei Lin, Rui Yan
分类: cs.CL
发布日期: 2025-09-27
💡 一句话要点
TagPR:通过强化学习和思维标注提升LLM的个性化推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化推理 大型语言模型 强化学习 思维标注 用户偏好 奖励模型 监督式微调
📋 核心要点
- 现有LLM在通用推理方面表现出色,但在分析用户历史、推断偏好并生成定制化响应的个性化推理方面存在不足。
- TagPR框架通过标注推理链,并结合监督式微调和强化学习,使LLM能够更好地理解和模拟用户个性化推理过程。
- 实验结果表明,TagPR在个性化推理任务上显著优于现有方法,平均提升高达32.65%,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为TagPR的训练框架,旨在显著提升大型语言模型(LLM)的个性化推理能力。该框架通过“标注思维”的方法,首先开发一个数据驱动的流程来自动生成和语义标注推理链,从而创建一个结构化的数据集,促进可解释的推理。然后,提出一种协同训练策略,首先在此标注数据上进行监督式微调(SFT),以建立基本的推理模式,然后进行多阶段强化学习(RL)过程。此RL阶段由独特的复合奖励信号引导,该信号集成了基于标签的约束和一个新颖的带有用户嵌入的个性化奖励模型(PRMU),以实现与用户特定逻辑的细粒度对齐。在公共LaMP基准和一个自构建数据集上的大量实验表明,该方法实现了最先进的结果,在所有任务中,相对于基础模型平均提高了32.65%。这项工作验证了结构化、可解释的推理是释放LLM中真正个性化能力的高度有效途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在个性化推理方面的不足。现有方法难以有效利用用户历史信息,准确推断用户偏好,并生成高度定制化的响应。这主要是因为LLM缺乏对用户特定逻辑的细粒度理解和建模能力。
核心思路:论文的核心思路是通过“标注思维”的方式,显式地建模LLM的推理过程,使其更易于理解和控制。具体来说,首先生成带有语义标签的推理链,然后利用这些标注数据进行训练,使LLM能够学习到个性化推理的模式。同时,引入强化学习,利用奖励信号引导LLM生成更符合用户偏好的响应。
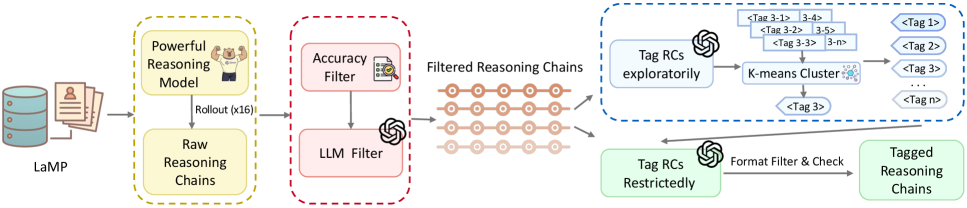
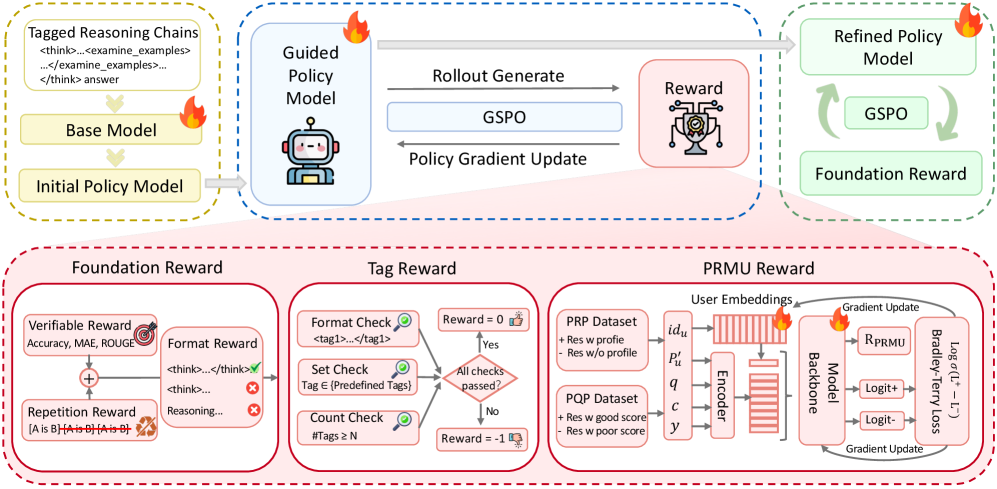
技术框架:TagPR框架包含以下几个主要阶段:1) 数据生成与标注:利用数据驱动的流程自动生成推理链,并进行语义标注,构建结构化数据集。2) 监督式微调(SFT):在标注数据上进行SFT,使LLM学习基本的推理模式。3) 强化学习(RL):通过多阶段RL过程,利用复合奖励信号引导LLM生成更符合用户偏好的响应。复合奖励信号包括基于标签的约束和个性化奖励模型(PRMU)。
关键创新:论文的关键创新在于以下几点:1) 提出了一种“标注思维”的方法,通过显式地建模推理过程,提升LLM的可解释性和可控性。2) 设计了一种新颖的复合奖励信号,集成了基于标签的约束和个性化奖励模型(PRMU),实现了与用户特定逻辑的细粒度对齐。3) 提出了一种协同训练策略,结合了监督式微调和强化学习,充分利用了标注数据的优势。
关键设计:PRMU模型利用用户嵌入来预测奖励,从而更好地捕捉用户偏好。复合奖励函数的设计平衡了推理链的正确性(通过标签约束)和用户偏好(通过PRMU)。强化学习阶段采用了多阶段训练策略,逐步提升LLM的个性化推理能力。具体参数设置和网络结构细节在论文中有详细描述,此处未知。
🖼️ 关键图片

📊 实验亮点
TagPR在LaMP基准测试和自构建数据集上取得了显著的性能提升,相对于基线模型平均提高了32.65%。实验结果表明,TagPR能够有效地提升LLM的个性化推理能力,生成更符合用户偏好的响应。此外,消融实验验证了各个模块的有效性,例如标注数据、复合奖励信号和多阶段训练策略。
🎯 应用场景
TagPR框架可应用于各种需要个性化推荐和对话的场景,例如电商推荐、智能客服、个性化教育等。通过提升LLM的个性化推理能力,可以为用户提供更精准、更贴心的服务,提高用户满意度和参与度。未来,该方法有望进一步扩展到其他领域,例如医疗诊断和金融风控等。
📄 摘要(原文)
Recent advancements have endowed Large Language Models (LLMs) with impressive general reasoning capabilities, yet they often struggle with personalization reasoning - the crucial ability to analyze user history, infer unique preferences, and generate tailored responses. To address this limitation, we introduce TagPR, a novel training framework that significantly enhances an LLM's intrinsic capacity for personalization reasoning through a tagging the thought approach. Our method first develops a data-driven pipeline to automatically generate and semantically label reasoning chains, creating a structured dataset that fosters interpretable reasoning. We then propose a synergistic training strategy that begins with Supervised Fine-Tuning (SFT) on this tagged data to establish foundational reasoning patterns, followed by a multi-stage reinforcement learning (RL) process. This RL phase is guided by a unique composite reward signal, which integrates tag-based constraints and a novel Personalization Reward Model with User Embeddings (PRMU) to achieve fine-grained alignment with user-specific logic. Extensive experiments on the public LaMP benchmark and a self-constructed dataset demonstrate that our approach achieves state-of-the-art results, delivering an average improvement of 32.65% over the base model across all tasks. Our work validates that structured, interpretable reasoning is a highly effective pathway to unlocking genuine personalization capabilities in LLMs.