How to Make Large Language Models Generate 100% Valid Molecules?
作者: Wen Tao, Jing Tang, Alvin Chan, Bryan Hooi, Baolong Bi, Nanyun Peng, Yuansheng Liu, Yiwei Wang
分类: cs.CL, cs.LG
发布日期: 2025-09-27
备注: EMNLP 2025 Main
🔗 代码/项目: GITHUB
💡 一句话要点
提出SmiSelf框架,确保大语言模型生成100%有效分子
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分子生成 大语言模型 SMILES SELFIES 化学信息学 药物发现 材料科学
📋 核心要点
- 大语言模型在分子生成任务中面临生成无效SMILES分子的挑战,尤其是在少样本学习场景下。
- SmiSelf框架通过将无效SMILES转换为SELFIES,利用SELFIES的特性来纠正错误,从而确保生成分子的有效性。
- 实验结果表明,SmiSelf不仅保证了100%的分子有效性,还保留了分子特性,并在其他性能指标上有所提升。
📝 摘要(中文)
分子生成是药物发现和材料科学的关键,它能够设计具有特定性质的新型化合物。大型语言模型(LLM)可以通过少量示例学习执行各种任务。然而,对于LLM来说,在少样本设置中使用SMILES等表示生成有效的分子具有挑战性。本文探讨了LLM如何生成100%有效的分子。我们评估了LLM是否可以使用SELFIES(一种每个字符串都对应于有效分子的表示)进行有效分子生成,但发现LLM在使用SELFIES时的表现比使用SMILES时更差。然后,我们检查了LLM纠正无效SMILES的能力,发现它们的能力有限。最后,我们引入了SmiSelf,一个用于无效SMILES校正的跨化学语言框架。SmiSelf使用语法规则将无效SMILES转换为SELFIES,利用SELFIES的机制来纠正无效SMILES。实验表明,SmiSelf确保了100%的有效性,同时保留了分子特性,并在其他指标上保持甚至提高了性能。SmiSelf有助于扩展LLM在生物医学中的实际应用,并且与所有基于SMILES的生成模型兼容。代码可在https://github.com/wentao228/SmiSelf 获取。
🔬 方法详解
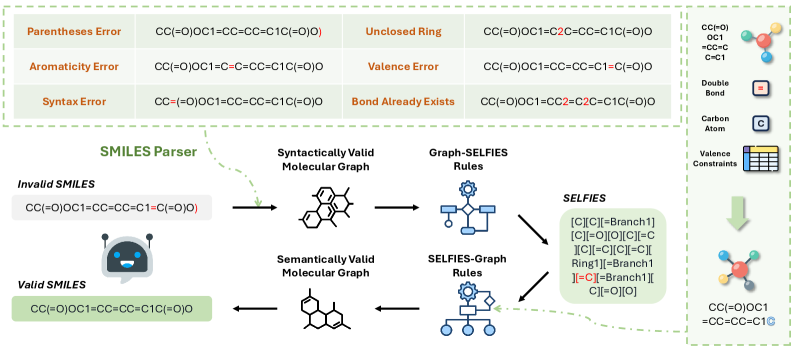
问题定义:论文旨在解决大语言模型(LLM)在分子生成任务中,使用SMILES表示时难以保证生成分子结构有效性的问题。现有的LLM在少样本学习场景下,容易生成无效的SMILES字符串,导致无法实际应用。
核心思路:论文的核心思路是利用SELFIES表示的特性,即任何SELFIES字符串都对应一个有效的分子结构。通过将无效的SMILES字符串转换为SELFIES,再利用SELFIES的内在机制进行校正,最终生成有效的分子结构。这种方法避免了直接在SMILES空间进行校正的困难。
技术框架:SmiSelf框架包含以下几个主要步骤:1) 输入无效的SMILES字符串;2) 使用预定义的语法规则将无效SMILES转换为SELFIES;3) 利用SELFIES的特性进行校正;4) 将校正后的SELFIES转换回SMILES(可选)。整个框架的核心在于SMILES到SELFIES的转换和SELFIES的校正机制。
关键创新:SmiSelf的关键创新在于它利用了跨化学语言的转换,巧妙地借助SELFIES的特性来解决SMILES生成有效性问题。与直接尝试纠正SMILES字符串相比,这种方法更加有效和可靠。此外,SmiSelf框架具有通用性,可以与各种基于SMILES的分子生成模型结合使用。
关键设计:SmiSelf框架的关键设计包括:1) SMILES到SELFIES的转换规则,需要保证转换的准确性和效率;2) SELFIES的校正机制,需要能够有效地纠正SELFIES字符串中的错误,同时保持分子结构的合理性;3) 损失函数的设计,可能需要考虑分子性质的保持,例如使用分子相似性作为正则项。
🖼️ 关键图片

📊 实验亮点
SmiSelf框架能够确保生成100%有效的分子,显著优于直接使用LLM生成SMILES的方法。实验表明,SmiSelf不仅保证了分子有效性,还在分子特性保持方面表现出色,甚至在某些指标上有所提升。该框架与现有的基于SMILES的生成模型兼容,易于集成和应用。
🎯 应用场景
SmiSelf框架在药物发现、材料科学等领域具有广泛的应用前景。它可以帮助研究人员利用大语言模型快速生成大量有效的候选分子,加速新药和新材料的研发进程。此外,SmiSelf还可以应用于分子性质预测、逆向合成等任务,提高相关研究的效率和准确性。
📄 摘要(原文)
Molecule generation is key to drug discovery and materials science, enabling the design of novel compounds with specific properties. Large language models (LLMs) can learn to perform a wide range of tasks from just a few examples. However, generating valid molecules using representations like SMILES is challenging for LLMs in few-shot settings. In this work, we explore how LLMs can generate 100% valid molecules. We evaluate whether LLMs can use SELFIES, a representation where every string corresponds to a valid molecule, for valid molecule generation but find that LLMs perform worse with SELFIES than with SMILES. We then examine LLMs' ability to correct invalid SMILES and find their capacity limited. Finally, we introduce SmiSelf, a cross-chemical language framework for invalid SMILES correction. SmiSelf converts invalid SMILES to SELFIES using grammatical rules, leveraging SELFIES' mechanisms to correct the invalid SMILES. Experiments show that SmiSelf ensures 100% validity while preserving molecular characteristics and maintaining or even enhancing performance on other metrics. SmiSelf helps expand LLMs' practical applications in biomedicine and is compatible with all SMILES-based generative models. Code is available at https://github.com/wentao228/SmiSelf.