From Evidence to Trajectory: Abductive Reasoning Path Synthesis for Training Retrieval-Augmented Generation Agents
作者: Muzhi Li, Jinhu Qi, Yihong Wu, Minghao Zhao, Liheng Ma, Yifan Li, Xinyu Wang, Yingxue Zhang, Ho-fung Leung, Irwin King
分类: cs.CL, cs.AI
发布日期: 2025-09-27
💡 一句话要点
提出EviPath,通过证据推理路径合成训练RAG Agent,提升开放域问答性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RAG Agent 推理路径合成 演绎推理 证据检索 开放域问答
📋 核心要点
- 现有RAG Agent训练缺乏过程级监督,难以指导任务分解和决策。
- EviPath通过演绎式子任务规划和证据支持的子问题回答合成训练数据。
- 实验表明,使用EviPath训练的8B模型在开放域问答上显著优于SOTA基线。
📝 摘要(中文)
检索增强生成(RAG)Agent的开发受到缺乏过程级监督的阻碍,难以有效指导Agent的任务分解、检索器调用和逐步决策等能力。强化学习虽然是一种潜在的解决方案,但面临奖励稀疏和大语言模型(LLM)推理能力有限的问题。现有的数据合成方法仅生成思维链推理,无法模拟环境交互。本文提出了EviPath,一种基于证据的推理路径合成范式,用于RAG Agent的开发。EviPath包括:(i)演绎式子任务规划,将问题分解为子问题,并基于它们之间的依赖关系迭代地规划最优解决方案路径;(ii)忠实的子问题回答,使用支持性证据构建代理环境,为每个子问题生成推理思路和答案;(iii)对话式微调,将完整的Agent-环境交互轨迹格式化为适合监督微调的对话格式。EviPath使LLM能够直接从合成数据中学习复杂的推理和工具使用能力。在广泛使用的问答基准上的大量实验表明,使用EviPath合成数据训练的80亿参数模型在开放域问答中显著且持续地优于最先进的基线,绝对EM增益高达14.7%。
🔬 方法详解
问题定义:现有RAG Agent的训练缺乏有效的过程级监督,导致Agent在任务分解、检索器调用和逐步决策等能力上表现不足。强化学习方法面临奖励稀疏和LLM推理能力限制的问题,而现有数据合成方法无法模拟Agent与环境的交互,难以有效提升Agent的整体性能。
核心思路:EviPath的核心思路是通过合成高质量的Agent-环境交互轨迹来提供有效的训练数据。它模拟了Agent解决问题的完整过程,包括任务分解、证据检索和逐步推理,从而使LLM能够学习复杂的推理和工具使用能力。这种方法避免了对真实环境的依赖,降低了训练成本。
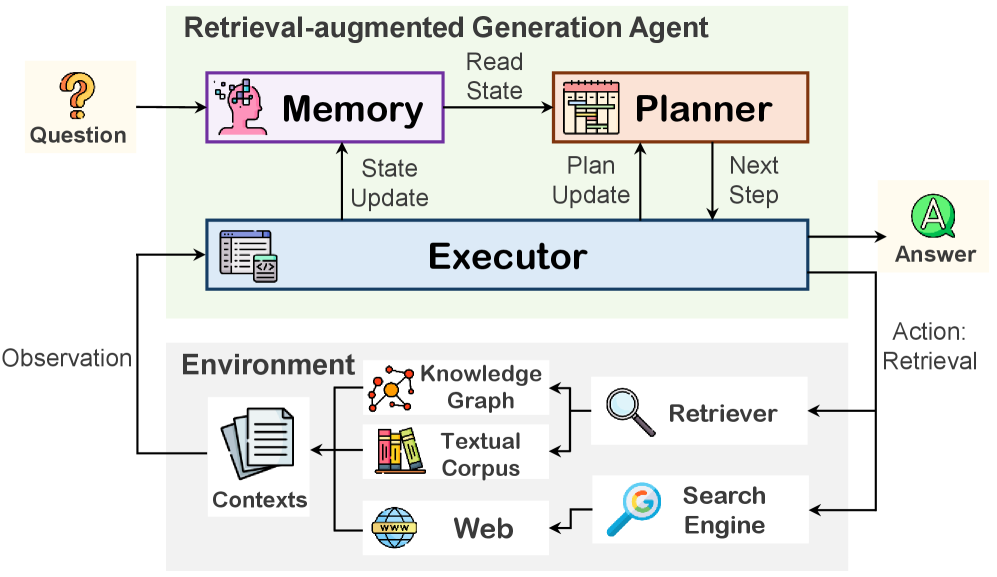
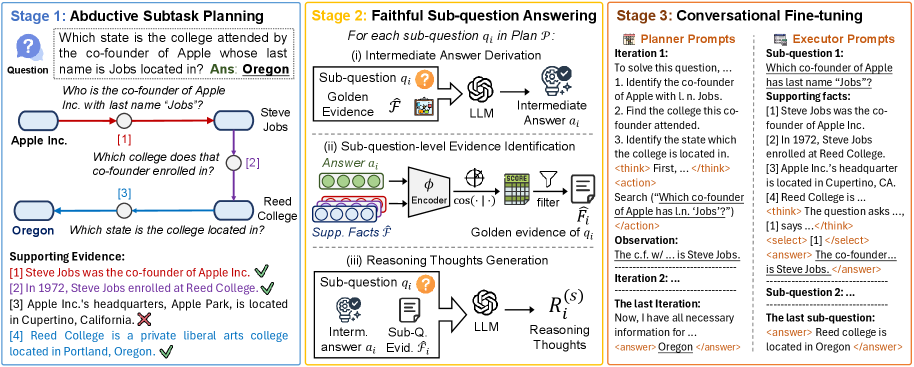
技术框架:EviPath包含三个主要阶段:(1)演绎式子任务规划:将复杂问题分解为一系列相互依赖的子问题,并规划最优的解决方案路径。(2)忠实的子问题回答:利用检索到的证据构建代理环境,为每个子问题生成推理思路和答案。(3)对话式微调:将Agent与环境的交互轨迹转换为对话格式,用于监督微调LLM。
关键创新:EviPath的关键创新在于其基于证据的推理路径合成范式。与传统的思维链方法不同,EviPath强调Agent与环境的交互,并利用证据来约束推理过程,从而生成更真实、更可靠的训练数据。此外,演绎式子任务规划能够有效地分解复杂问题,提高Agent的解决问题的能力。
关键设计:在演绎式子任务规划阶段,论文可能使用了某种图搜索算法来寻找最优的子问题依赖关系。在忠实的子问题回答阶段,可能使用了某种prompt工程技术来引导LLM生成高质量的推理思路和答案。在对话式微调阶段,可能使用了某种损失函数来优化LLM的对话生成能力。具体的技术细节未知,需要查阅论文全文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用EviPath合成数据训练的80亿参数模型在开放域问答任务上取得了显著的性能提升,绝对EM增益高达14.7%,超过了现有的SOTA基线。这表明EviPath能够有效地提升RAG Agent的推理和工具使用能力,并为Agent的开发提供了一种新的有效方法。
🎯 应用场景
EviPath方法可应用于各种需要复杂推理和工具使用的RAG Agent开发场景,例如智能客服、知识图谱问答、科学研究助手等。通过合成高质量的训练数据,可以显著提升Agent的性能和可靠性,从而实现更智能、更高效的自动化解决方案。该方法还有潜力应用于其他类型的Agent训练,例如机器人控制和游戏AI。
📄 摘要(原文)
Retrieval-augmented generation agents development is hindered by the lack of process-level supervision to effectively guide agentic capabilities like task decomposition, retriever invocation, and stepwise decision-making. While reinforcement learning offers a potential solution, it suffers from sparse rewards and the limited reasoning capabilities of large language models (LLMs). Meanwhile, existing data synthesis methods only produce chain-of-thought rationales and fail to model environmental interactions. In this paper, we propose EviPath, an evidence-anchored reasoning path synthesis paradigm for RAG agent development. EviPath comprises: (i) Abductive Subtask Planning, which decomposes the problem into sub-questions and iteratively plans an optimal solution path based on the dependencies between them; (ii) Faithful Sub-question Answering, which uses supporting evidence to construct a proxy environment to generate reasoning thoughts and answers for each sub-question; and (iii) Conversational Fine-Tuning, which formats the complete agent-environment interaction trajectory into a dialogue format suitable for Supervised Fine-Tuning. EviPath allows LLMs to learn complex reasoning and tool-use capabilities directly from synthesized data. Extensive experiments on widely-used question-answering benchmarks show that an 8B parameter model trained with EviPath-synthesized data significantly and consistently outperforms state-of-the-art baselines with a double-digit absolute EM gain of 14.7% in open-domain question answering.