Look Back to Reason Forward: Revisitable Memory for Long-Context LLM Agents
作者: Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, An Zhang
分类: cs.CL, cs.AI
发布日期: 2025-09-27 (更新: 2026-01-28)
💡 一句话要点
提出ReMemR1,通过可回顾记忆增强长文本LLM Agent的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本问答 记忆检索 大型语言模型 强化学习 非线性推理
📋 核心要点
- 现有长文本LLM Agent采用线性扫描更新记忆,易丢失关键信息,且缺乏有效的训练信号。
- ReMemR1通过在记忆更新时引入检索机制,实现非线性推理,并回调历史记忆。
- 多层次奖励设计结合最终答案与步级信号,指导Agent有效利用记忆,显著提升长文本问答性能。
📝 摘要(中文)
大型语言模型在长文本问答中面临挑战,查询的关键证据可能分散在数百万个token中。现有方法通常采用“边读边记”的线性文档扫描方式动态更新记忆缓冲区,但存在潜在证据修剪、信息覆盖损失和稀疏强化学习信号等问题。为了解决这些挑战,我们提出了ReMemR1,它将记忆检索机制集成到记忆更新过程中,使Agent能够选择性地回调历史记忆进行非线性推理。为了进一步加强训练,我们设计了一种多层次奖励机制,将最终答案奖励与密集的步级信号相结合,以指导Agent有效利用记忆。大量实验表明,ReMemR1在长文本问答方面显著优于最先进的基线方法,且计算开销可忽略不计,验证了其以边际成本换取稳健长文本推理的能力。
🔬 方法详解
问题定义:论文旨在解决长文本问答中,大型语言模型难以有效利用分散在大量文本中的关键证据的问题。现有方法,如“边读边记”的线性扫描方式,存在三个主要痛点:一是容易修剪掉潜在的关键证据;二是信息覆盖导致重要信息丢失;三是强化学习信号稀疏,难以有效训练Agent。
核心思路:ReMemR1的核心思路是在记忆更新过程中引入记忆检索机制,使Agent能够回顾并利用历史记忆进行推理。通过这种非线性推理方式,Agent可以更好地整合分散的信息,避免信息丢失,并进行更复杂的推理。
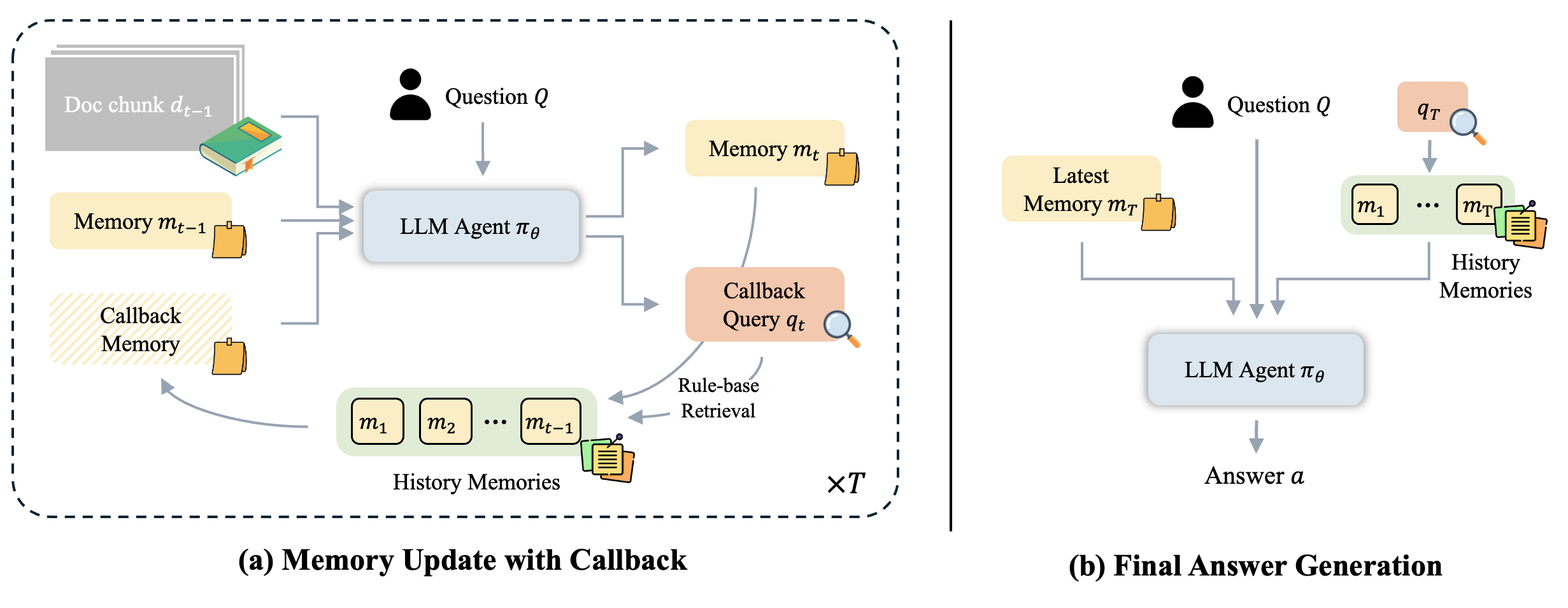
技术框架:ReMemR1的整体框架包含以下几个主要模块:1) 输入长文本序列;2) 动态记忆缓冲区,用于存储历史信息;3) 记忆检索模块,用于从记忆缓冲区中检索相关信息;4) 记忆更新模块,用于根据当前输入和检索到的历史信息更新记忆缓冲区;5) 问答模块,用于根据更新后的记忆缓冲区回答问题。整个流程是循环迭代的,Agent在读取文本的同时不断更新记忆,并利用记忆进行推理。
关键创新:ReMemR1最重要的技术创新点是将记忆检索机制集成到记忆更新过程中。与传统的线性扫描方式不同,ReMemR1允许Agent根据当前输入动态地回顾历史记忆,从而实现非线性推理。这种方式可以更好地整合分散的信息,避免信息丢失,并支持更复杂的推理。
关键设计:ReMemR1的关键设计包括:1) 记忆检索模块的具体实现方式,例如使用相似度搜索或注意力机制;2) 记忆更新模块的更新策略,例如如何融合当前输入和检索到的历史信息;3) 多层次奖励函数的设计,包括最终答案奖励和步级奖励,用于指导Agent有效利用记忆。步级奖励可以根据Agent是否检索到相关信息、是否更新了记忆等进行设计。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ReMemR1在长文本问答任务上显著优于现有方法。具体而言,ReMemR1在多个数据集上取得了state-of-the-art的性能,并且在某些数据集上的提升幅度超过10%。此外,ReMemR1的计算开销可忽略不计,验证了其在实际应用中的可行性。
🎯 应用场景
ReMemR1具有广泛的应用前景,例如在法律文档分析、医学报告解读、金融市场预测等需要处理大量文本信息的领域。通过增强LLM Agent的长文本推理能力,可以提高信息提取的准确性和效率,辅助决策,并发现隐藏的关联。
📄 摘要(原文)
Large language models face challenges in long-context question answering, where key evidence of a query may be dispersed across millions of tokens. Existing works equip large language models with a memory buffer that is dynamically updated via a linear document scan, also known as the "memorize while reading" methods. While this approach scales efficiently, it suffers from pruning of latent evidence, information loss through overwriting, and sparse reinforcement learning signals. To tackle these challenges, we present ReMemR1, which integrates the mechanism of memory retrieval into the memory update process, enabling the agent to selectively callback historical memories for non-linear reasoning. To further strengthen training, we propose a multi-level reward design, which combines final-answer rewards with dense, step-level signals that guide effective memory use. Together, these contributions mitigate information degradation, improve supervision, and support complex multi-hop reasoning. Extensive experiments demonstrate that ReMemR1 significantly outperforms state-of-the-art baselines on long-context question answering while incurring negligible computational overhead, validating its ability to trade marginal cost for robust long-context reasoning.