Can Prompts Rewind Time for LLMs? Evaluating the Effectiveness of Prompted Knowledge Cutoffs
作者: Xin Gao, Ruiyi Zhang, Daniel Du, Saurabh Mahindre, Sai Ashish Somayajula, Pengtao Xie
分类: cs.CL, cs.LG
发布日期: 2025-09-26 (更新: 2025-10-15)
备注: Published at EMNLP 2025; Code and data available at https://github.com/gxx27/time_unlearn
🔗 代码/项目: GITHUB
💡 一句话要点
提示工程能否使LLM回溯时间?评估提示知识截断的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时间预测 知识截断 提示工程 遗忘学习
📋 核心要点
- LLM在时间预测中表现出色,但过度依赖预训练数据导致评估泛化能力时存在偏差,难以区分记忆与推理。
- 该论文探索通过提示工程,使LLM模拟更早的知识截断,从而评估其在时间维度上的泛化能力。
- 实验表明,提示在直接事实遗忘上有效,但在因果相关知识遗忘上表现不佳,揭示了现有方法的局限性。
📝 摘要(中文)
大型语言模型(LLM)被广泛应用于时间预测,但它们对预训练数据的依赖引发了污染问题,因为对截断前测试数据的准确预测可能反映的是记忆而非推理,从而导致对其泛化能力的过度估计。随着最近基于提示的遗忘技术的出现,一个自然的问题产生了:是否可以通过提示来模拟LLM更早的知识截断?在这项工作中,我们研究了提示在LLM中模拟更早知识截断的能力。我们构建了三个评估数据集,以评估LLM在多大程度上可以忘记(1)直接的事实知识,(2)语义转变,以及(3)因果相关的知识。结果表明,当直接查询该日期之后的信息时,基于提示的模拟知识截断显示出有效性,但当忘记的内容不是直接询问而是与查询因果相关时,它们难以诱导遗忘。这些发现强调了在将LLM应用于时间预测任务时,需要更严格的评估设置。完整的数据集和评估代码可在https://github.com/gxx27/time_unlearn 获取。
🔬 方法详解
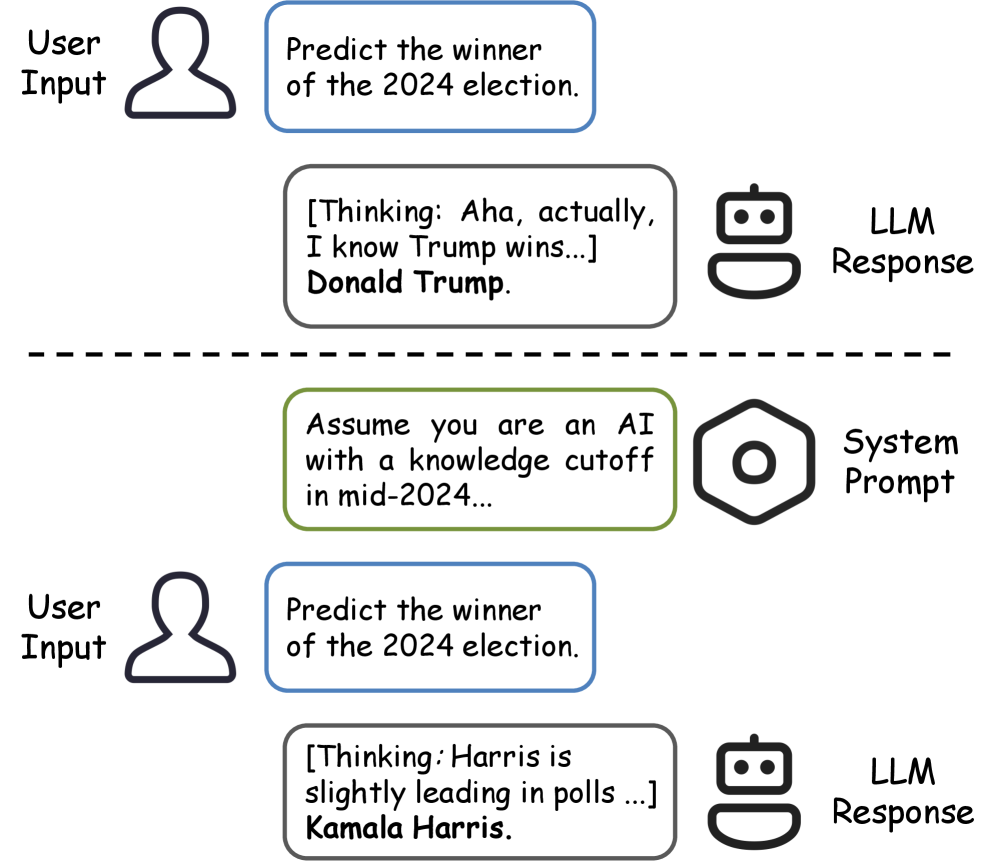
问题定义:现有的大型语言模型在进行时间预测时,由于其训练数据包含了大量时间信息,因此在评估其泛化能力时,很难区分模型是真正理解了时间演变规律,还是仅仅记住了训练数据中的时间信息。这导致对模型泛化能力的评估存在偏差,高估了模型在时间维度上的推理能力。现有方法缺乏有效手段来控制模型的时间知识范围,从而进行更严格的评估。
核心思路:该论文的核心思路是利用提示工程(Prompt Engineering)来模拟大型语言模型在某个时间点之前的知识状态,即让模型“忘记”某个时间点之后的信息。通过设计特定的提示,引导模型只使用该时间点之前的知识来回答问题,从而评估模型在时间维度上的泛化能力。这种方法可以有效地控制模型的时间知识范围,避免模型过度依赖记忆。
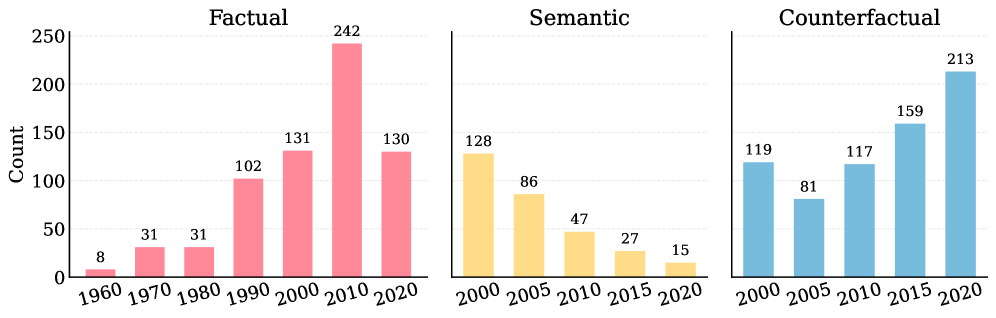
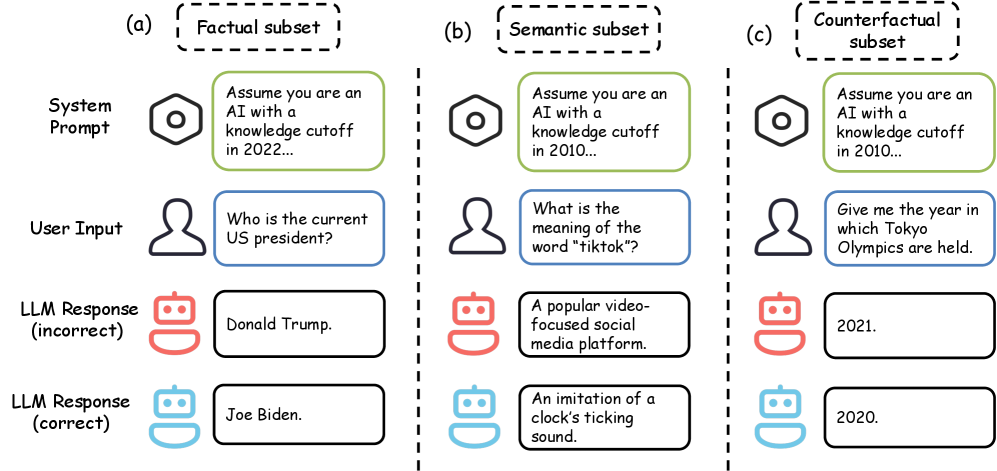
技术框架:该研究的技术框架主要包括以下几个部分:1) 构建评估数据集:构建三个数据集,分别评估模型在直接事实知识、语义转变和因果相关知识上的遗忘能力。2) 设计提示模板:设计不同的提示模板,引导模型模拟更早的知识截断。3) 评估指标:使用准确率等指标来评估模型在不同提示下的表现。4) 对比实验:将不同提示方法的效果进行对比,分析其优缺点。
关键创新:该论文的关键创新在于提出了利用提示工程来模拟大型语言模型知识截断的方法。这种方法提供了一种新的思路,可以更有效地评估模型在时间维度上的泛化能力,并为未来的研究提供了新的方向。与传统的知识编辑方法相比,提示工程更加灵活,无需修改模型的内部参数。
关键设计:论文的关键设计包括:1) 三种不同类型的评估数据集,分别针对直接事实、语义转变和因果关系进行评估。2) 多种提示模板的设计,例如使用“在[时间]之前”等提示语来引导模型只使用该时间点之前的知识。3) 使用准确率作为评估指标,衡量模型在不同提示下的表现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于提示的模拟知识截断在直接查询截断日期之后的信息时有效,但在查询与已遗忘内容因果相关的信息时效果不佳。这表明当前基于提示的遗忘方法存在局限性,需要更深入的研究和改进。例如,在直接事实知识的遗忘任务上,提示能够显著降低模型的准确率,但在因果相关知识的遗忘任务上,模型的准确率下降幅度有限。
🎯 应用场景
该研究成果可应用于对LLM进行更可靠的时间敏感性评估,例如在金融预测、新闻分析、历史事件推理等领域。通过模拟知识截断,可以更好地评估模型在特定时间范围内的预测能力,从而提高模型在实际应用中的可靠性和准确性。此外,该研究也为开发更有效的知识遗忘技术提供了思路。
📄 摘要(原文)
Large Language Models (LLMs) are widely used for temporal prediction, but their reliance on pretraining data raises contamination concerns, as accurate predictions on pre-cutoff test data may reflect memorization rather than reasoning, leading to an overestimation of their generalization capability. With the recent emergence of prompting-based unlearning techniques, a natural question arises: Can LLMs be prompted to simulate an earlier knowledge cutoff? In this work, we investigate the capability of prompting to simulate earlier knowledge cutoff in LLMs. We construct three evaluation datasets to assess the extent to which LLMs can forget (1) direct factual knowledge, (2) semantic shifts, and (3) causally related knowledge. Results demonstrate that while prompt-based simulated knowledge cutoffs show effectiveness when directly queried with the information after that date, they struggle to induce forgetting when the forgotten content is not directly asked but causally related to the query. These findings highlight the need for more rigorous evaluation settings when applying LLMs for temporal prediction tasks. The full dataset and evaluation code are available at https://github.com/gxx27/time_unlearn.