FormalML: A Benchmark for Evaluating Formal Subgoal Completion in Machine Learning Theory
作者: Xiao-Wen Yang, Zihao Zhang, Jianuo Cao, Zhi Zhou, Zenan Li, Lan-Zhe Guo, Yuan Yao, Taolue Chen, Yu-Feng Li, Xiaoxing Ma
分类: cs.CL, cs.AI
发布日期: 2025-09-26
💡 一句话要点
提出FormalML基准,评估LLM在机器学习理论中形式化子目标补全能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化定理证明 子目标补全 机器学习理论 大型语言模型 Lean 4 基准测试 前提检索
📋 核心要点
- 现有大型语言模型在形式化定理证明中表现出潜力,但缺乏在复杂证明中辅助填补步骤的有效评估。
- 提出FormalML基准,专注于子目标补全任务,利用Lean 4构建,涵盖机器学习基础理论。
- 实验评估表明,现有证明器在准确性和效率方面存在局限性,亟需更强大的LLM定理证明器。
📝 摘要(中文)
大型语言模型(LLM)最近在形式化定理证明方面取得了显著进展。然而,它们作为数学家的实用助手,在复杂证明中填补缺失步骤的能力仍未得到充分探索。我们将这一挑战定义为子目标补全任务,即LLM必须完成人类提供的草图中未解决的简短但重要的证明义务。为了研究这个问题,我们引入了FormalML,这是一个基于机器学习基础理论构建的Lean 4基准。通过使用将程序性证明转换为声明性形式的翻译策略,我们提取了跨越优化和概率不等式的4937个问题,难度各异。FormalML是第一个结合前提检索和复杂研究级别上下文的子目标补全基准。对最先进的证明器的评估突出了准确性和效率方面的持续局限性,强调了需要更强大的基于LLM的定理证明器来实现有效的子目标补全。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在形式化定理证明中,无法有效完成人类提供的证明草图中缺失的子目标的问题。现有方法缺乏在复杂研究级别上下文中的评估,并且难以处理需要前提检索的子目标补全任务。
核心思路:论文的核心思路是构建一个专门针对机器学习理论的形式化证明基准FormalML,用于评估LLM在子目标补全任务中的能力。通过将程序性证明转换为声明性形式,提取出大量具有挑战性的子目标补全问题,从而为LLM提供一个更具针对性的训练和评估环境。
技术框架:FormalML基准构建于Lean 4形式化证明系统之上,包含以下主要模块:1) 机器学习基础理论库,涵盖优化和概率不等式等领域;2) 翻译策略,用于将程序性证明转换为声明性形式;3) 问题提取模块,用于从理论库中提取子目标补全问题;4) 评估模块,用于评估LLM在FormalML上的性能。整体流程是从现有的机器学习理论证明中提取子目标,然后利用这些子目标来评估LLM的证明能力。
关键创新:FormalML的关键创新在于它是第一个结合前提检索和复杂研究级别上下文的子目标补全基准。与以往的基准相比,FormalML的问题更具挑战性,更贴近实际的数学研究场景。此外,FormalML还提供了一个标准化的评估平台,方便研究人员比较不同LLM的性能。
关键设计:FormalML的关键设计包括:1) 使用Lean 4作为形式化证明系统,保证了证明的严格性和可靠性;2) 采用翻译策略将程序性证明转换为声明性形式,使得问题更易于理解和处理;3) 提取了4937个难度各异的子目标补全问题,覆盖了机器学习的多个重要领域;4) 提供了统一的评估指标,方便研究人员进行比较。
🖼️ 关键图片

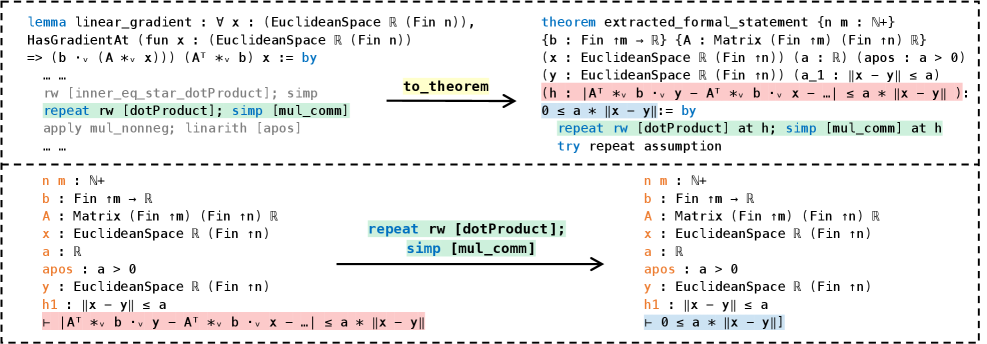

📊 实验亮点
实验结果表明,现有最先进的证明器在FormalML基准上的准确性和效率方面存在明显局限性,这突显了开发更强大的基于LLM的定理证明器以实现有效子目标补全的必要性。具体性能数据未在摘要中给出,但强调了现有方法的不足。
🎯 应用场景
该研究成果可应用于开发更智能的数学辅助工具,帮助数学家自动完成证明过程中的一些繁琐步骤,提高研究效率。此外,该基准还可以促进LLM在形式化推理和定理证明领域的发展,推动人工智能在科学发现中的应用。未来,或可扩展到其他科学领域,例如物理学和化学。
📄 摘要(原文)
Large language models (LLMs) have recently demonstrated remarkable progress in formal theorem proving. Yet their ability to serve as practical assistants for mathematicians, filling in missing steps within complex proofs, remains underexplored. We identify this challenge as the task of subgoal completion, where an LLM must discharge short but nontrivial proof obligations left unresolved in a human-provided sketch. To study this problem, we introduce FormalML, a Lean 4 benchmark built from foundational theories of machine learning. Using a translation tactic that converts procedural proofs into declarative form, we extract 4937 problems spanning optimization and probability inequalities, with varying levels of difficulty. FormalML is the first subgoal completion benchmark to combine premise retrieval and complex research-level contexts. Evaluation of state-of-the-art provers highlights persistent limitations in accuracy and efficiency, underscoring the need for more capable LLM-based theorem provers for effective subgoal completion,