ADAM: A Diverse Archive of Mankind for Evaluating and Enhancing LLMs in Biographical Reasoning
作者: Jasin Cekinmez, Omid Ghahroodi, Saad Fowad Chandle, Dhiman Gupta, Ehsaneddin Asgari
分类: cs.CL, cs.AI, cs.CV, cs.IR, cs.LG
发布日期: 2025-09-26
💡 一句话要点
提出ADAM框架,用于评估和提升LLM在人物传记推理中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人物传记推理 大型语言模型 多模态学习 检索增强生成 知识图谱
📋 核心要点
- 现有LLM在人物传记推理方面存在不足,尤其是在处理多语言、多模态信息和避免幻觉方面面临挑战。
- ADAM框架通过构建大规模多模态人物传记数据集和认知结构化评估基准,并结合检索增强生成技术来解决上述问题。
- 实验表明,ADAM框架能够有效提升LLM在人物传记推理方面的准确性和可靠性,尤其是在开源模型上表现突出。
📝 摘要(中文)
本文提出了ADAM(A Diverse Archive of Mankind),一个用于评估和改进多模态大型语言模型(MLLM)在人物传记推理方面的框架。据我们所知,这是第一个系统性地检查LLM在传记方面的能力的工作,传记是事实知识的一个关键但未被充分探索的维度。ADAM的核心是AdamDB,一个多语言和多模态数据集,涵盖了跨越地理、时间和职业的超过400万个人物。AdamBench提供基于Bloom分类法的认知结构化评估,涵盖英语和本地语言的六个推理级别。为了解决幻觉问题,特别是对于不太知名的人物,我们提出了AdamRAG,一个针对传记上下文量身定制的检索增强生成系统。实验表明,AdamRAG显著提高了开源模型,并适度地提升了闭源模型,在较低阶推理上增益最大。人物的知名度强烈影响准确性,而通过面部图像进行多模态输入提供的改进小于检索,且不太稳定。ADAM建立了第一个用于认知、文化和多模态基础上的传记评估的基准和框架,从而推进了多语言、准确和抗幻觉的MLLM的开发。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在人物传记推理方面存在的不足,特别是对于不太知名的人物,LLM容易产生幻觉,且缺乏对多语言和多模态信息的有效利用。现有方法在评估LLM的传记推理能力时,缺乏系统性和认知结构化的基准。
核心思路:论文的核心思路是构建一个大规模、多语言、多模态的人物传记数据集(AdamDB),并基于Bloom分类法设计认知结构化的评估基准(AdamBench)。同时,提出一种针对传记上下文的检索增强生成系统(AdamRAG),通过检索相关信息来减少LLM的幻觉。
技术框架:ADAM框架主要包含三个组成部分:AdamDB、AdamBench和AdamRAG。AdamDB是一个包含超过400万个人物传记的多语言和多模态数据集。AdamBench是一个基于Bloom分类法的认知结构化评估基准,涵盖六个推理级别。AdamRAG是一个检索增强生成系统,首先从AdamDB中检索相关信息,然后利用LLM生成答案。
关键创新:论文的关键创新在于:1) 构建了大规模、多语言、多模态的人物传记数据集AdamDB;2) 设计了基于Bloom分类法的认知结构化评估基准AdamBench;3) 提出了针对传记上下文的检索增强生成系统AdamRAG,有效减少了LLM的幻觉。
关键设计:AdamRAG的关键设计包括:1) 使用高效的检索算法从AdamDB中检索相关信息;2) 将检索到的信息作为LLM的输入,引导LLM生成更准确的答案;3) 针对不同推理级别的问题,设计不同的检索策略和生成策略。具体参数设置和网络结构等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


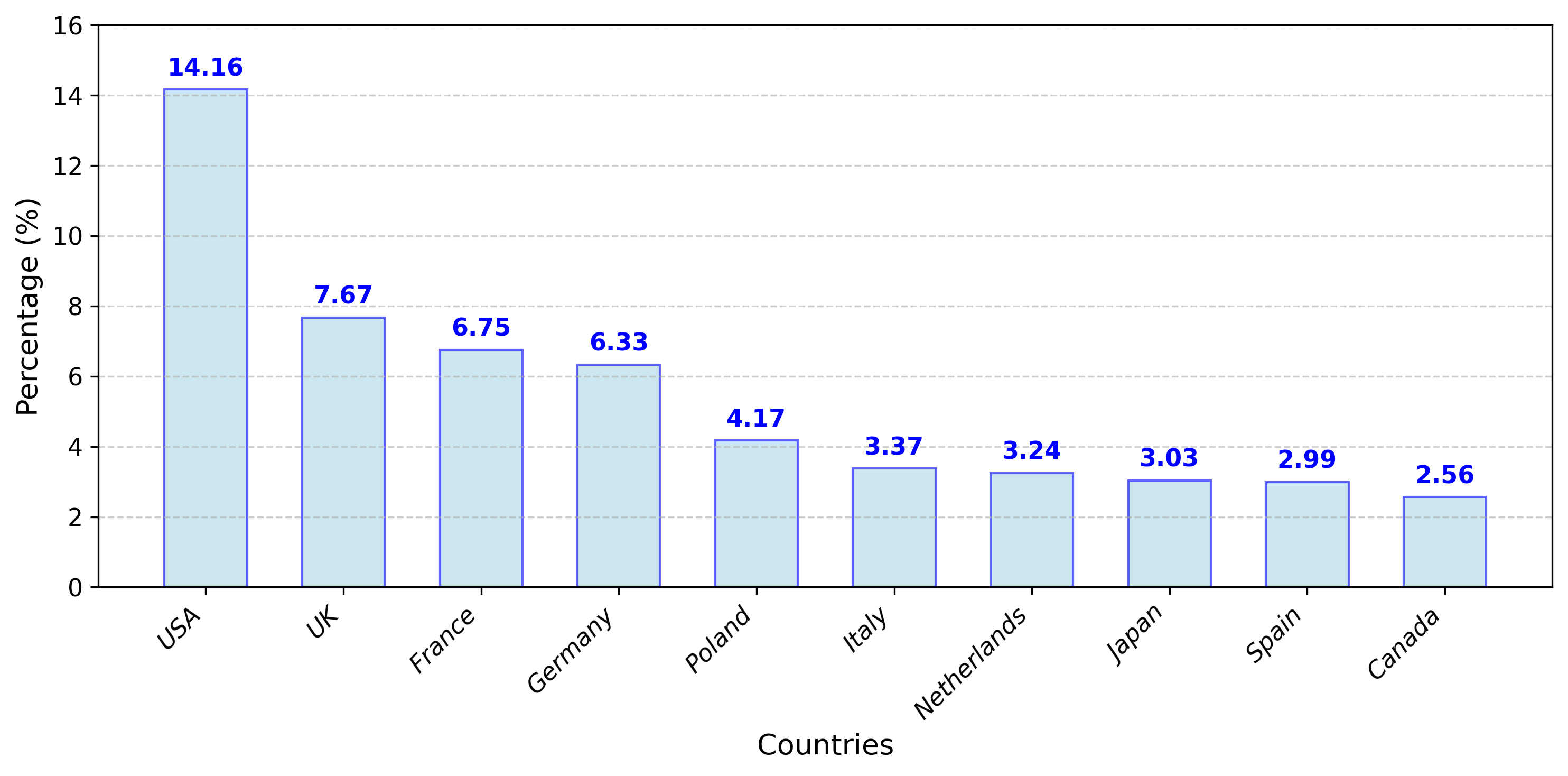
📊 实验亮点
实验结果表明,AdamRAG能够显著提高开源模型在人物传记推理方面的准确性,并适度提升闭源模型。在较低阶推理任务上,提升效果最为明显。此外,实验还发现,人物的知名度对准确性有显著影响,而多模态输入(面部图像)的提升效果小于检索,且不太稳定。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱构建、历史人物研究、教育等领域。通过提升LLM在人物传记推理方面的能力,可以为用户提供更准确、更可靠的人物信息,并促进相关领域的研究和应用。未来,该框架可以扩展到其他类型的知识领域,进一步提升LLM的知识推理能力。
📄 摘要(原文)
We introduce ADAM (A Diverse Archive of Mankind), a framework for evaluating and improving multimodal large language models (MLLMs) in biographical reasoning. To the best of our knowledge, this is the first work to systematically examine LLM capabilities in biography, a critical yet underexplored dimension of factual knowledge. At its core, AdamDB is a multilingual and multimodal dataset covering over 4 million individuals across geography, time, and profession, while AdamBench provides cognitively structured evaluations based on Bloom's taxonomy, spanning six reasoning levels in both English and native languages. To address hallucinations, particularly for lesser-known individuals, we propose AdamRAG, a retrieval-augmented generation system tailored to biographical contexts. Experiments show that AdamRAG substantially improves open-source models and modestly benefits closed-source ones, with the largest gains on lower-order reasoning. Popularity strongly mediates accuracy, and multimodal input via face images offers smaller, less consistent improvements than retrieval. ADAM establishes the first benchmark and framework for cognitively, culturally, and multimodally grounded biographical evaluation, advancing the development of multilingual, accurate, and hallucination-resistant MLLMs.