The Bias is in the Details: An Assessment of Cognitive Bias in LLMs
作者: R. Alexander Knipper, Charles S. Knipper, Kaiqi Zhang, Valerie Sims, Clint Bowers, Santu Karmaker
分类: cs.CL
发布日期: 2025-09-26
💡 一句话要点
评估LLM认知偏差:揭示模型在决策中存在的系统性偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 认知偏差 决策评估 提示工程 模型评估
📋 核心要点
- 现有LLM在决策中被广泛应用,但其潜在的认知偏差可能导致不合理的判断,需要深入评估。
- 论文提出一种基于多项选择题的新型评估框架,并构建包含220个决策场景的数据集,用于评估LLM的认知偏差。
- 实验结果表明,LLM在多种认知偏差上表现出与人类相似的偏差行为,且模型大小和提示细节会影响偏差程度。
📝 摘要(中文)
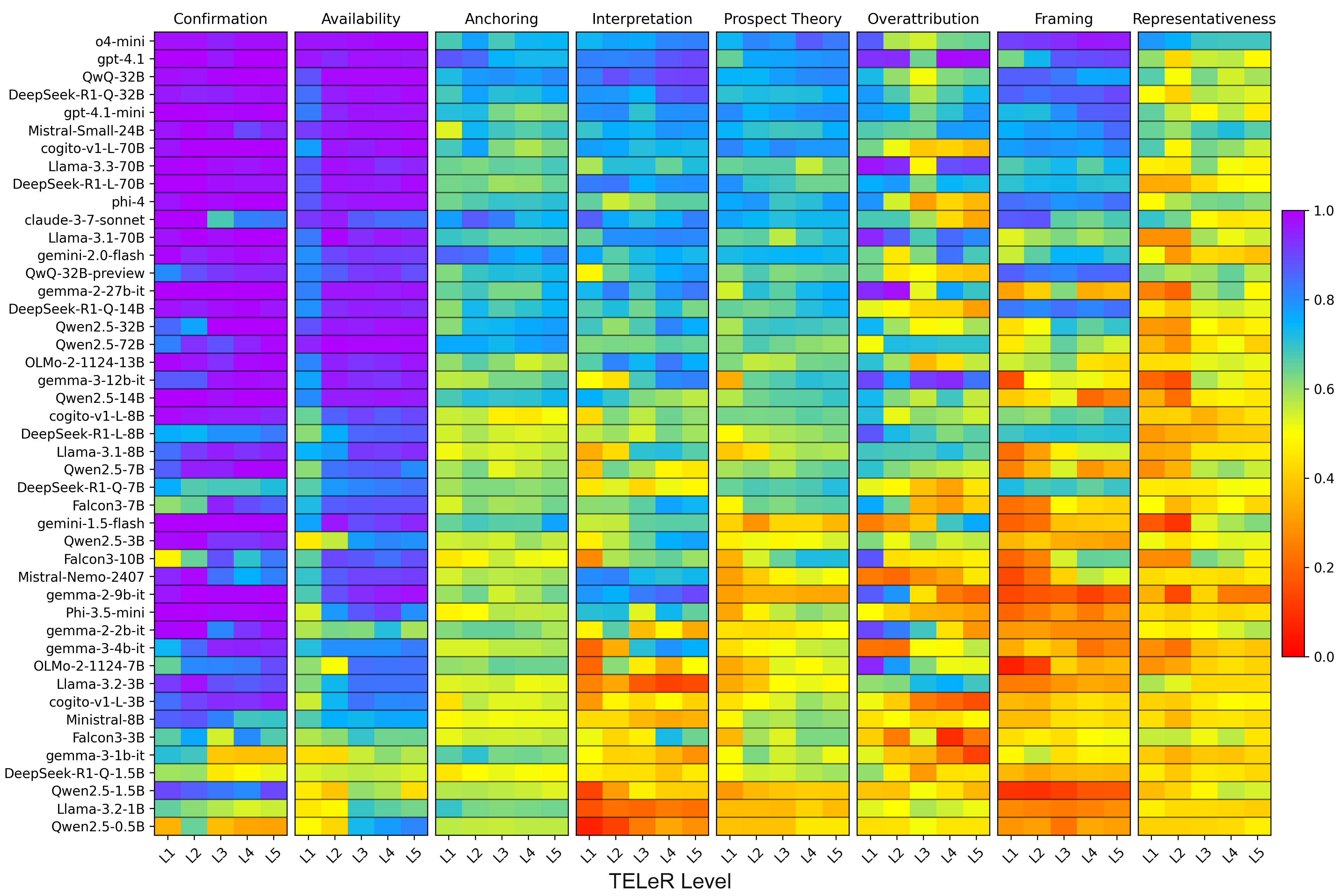
随着大型语言模型(LLM)越来越多地嵌入到现实世界的决策过程中,检验它们在多大程度上表现出认知偏差变得至关重要。认知偏差在心理学领域被广泛研究,表现为人类判断中常见的系统性扭曲。本文对45个LLM的八种已知的认知偏差进行了大规模评估,分析了通过受控提示变化生成的超过280万个LLM响应。为此,我们引入了一个基于多项选择题的新型评估框架,与心理学家合作手工策划了一个包含220个决策场景的数据集,针对基本的认知偏差,并提出了一种可扩展的方法,用于从人工编写的场景模板中生成不同的提示。我们的分析表明,LLM在17.8-57.3%的实例中表现出与偏差一致的行为,涵盖了一系列针对锚定效应、可得性启发、确认偏差、框架效应、解释偏差、过度归因、前景理论和代表性启发的判断和决策情境。我们发现模型大小和提示特异性对偏差敏感性有显著影响:较大的模型(>32B参数)可以在39.5%的情况下减少偏差,而更高的提示细节可以将大多数偏差降低高达14.9%,但在一种情况下(过度归因)偏差会加剧高达8.8%。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在决策过程中表现出的认知偏差。现有方法缺乏系统性的评估框架和针对LLM特点的数据集,难以全面了解LLM的偏差情况。这些偏差可能导致LLM在实际应用中做出不合理的决策。
核心思路:论文的核心思路是构建一个可控的实验环境,通过精心设计的场景和提示,诱导LLM进行决策,并分析其决策结果是否符合认知偏差的模式。通过大规模的实验,量化LLM在不同认知偏差上的表现,并探究模型大小和提示细节对偏差的影响。
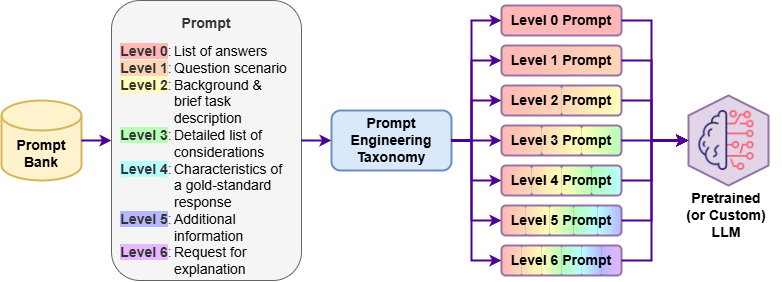
技术框架:论文的技术框架主要包含以下几个部分:1) 数据集构建:与心理学家合作,手工策划包含220个决策场景的数据集,每个场景针对一种或多种认知偏差。2) 提示生成:提出一种可扩展的方法,从人工编写的场景模板中生成不同的提示,以增加实验的多样性。3) 模型评估:使用多项选择题的形式,让LLM对每个场景进行决策,并分析其选择结果是否符合预期的偏差模式。4) 偏差分析:统计LLM在不同认知偏差上的表现,并分析模型大小和提示细节对偏差的影响。
关键创新:论文的关键创新在于:1) 新型评估框架:提出了一种基于多项选择题的评估框架,可以有效地量化LLM的认知偏差。2) 高质量数据集:构建了一个包含220个决策场景的数据集,专门用于评估LLM的认知偏差。3) 可扩展的提示生成方法:提出了一种可扩展的提示生成方法,可以从人工编写的场景模板中生成不同的提示,以增加实验的多样性。
关键设计:论文的关键设计包括:1) 场景设计:每个场景都经过精心设计,以诱导LLM产生特定的认知偏差。2) 提示设计:提示的设计考虑了不同的细节程度,以探究提示细节对偏差的影响。3) 模型选择:选择了45个不同大小和架构的LLM,以探究模型大小对偏差的影响。4) 统计分析:使用统计方法分析LLM的决策结果,以量化其认知偏差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在17.8-57.3%的实例中表现出与偏差一致的行为。较大的模型(>32B参数)可以在39.5%的情况下减少偏差,而更高的提示细节可以将大多数偏差降低高达14.9%,但在过度归因偏差上会加剧高达8.8%。这些发现揭示了模型大小和提示细节对LLM认知偏差的重要影响。
🎯 应用场景
该研究成果可应用于评估和改进LLM的决策能力,降低其在金融、医疗、法律等高风险领域的应用风险。通过识别和缓解LLM的认知偏差,可以提高其决策的公平性、客观性和可靠性,促进LLM在更广泛领域的安全应用,并为开发更值得信赖的人工智能系统提供指导。
📄 摘要(原文)
As Large Language Models (LLMs) are increasingly embedded in real-world decision-making processes, it becomes crucial to examine the extent to which they exhibit cognitive biases. Extensively studied in the field of psychology, cognitive biases appear as systematic distortions commonly observed in human judgments. This paper presents a large-scale evaluation of eight well-established cognitive biases across 45 LLMs, analyzing over 2.8 million LLM responses generated through controlled prompt variations. To achieve this, we introduce a novel evaluation framework based on multiple-choice tasks, hand-curate a dataset of 220 decision scenarios targeting fundamental cognitive biases in collaboration with psychologists, and propose a scalable approach for generating diverse prompts from human-authored scenario templates. Our analysis shows that LLMs exhibit bias-consistent behavior in 17.8-57.3% of instances across a range of judgment and decision-making contexts targeting anchoring, availability, confirmation, framing, interpretation, overattribution, prospect theory, and representativeness biases. We find that both model size and prompt specificity play a significant role on bias susceptibility as follows: larger size (>32B parameters) can reduce bias in 39.5% of cases, while higher prompt detail reduces most biases by up to 14.9%, except in one case (Overattribution), which is exacerbated by up to 8.8%.