Critique-Coder: Enhancing Coder Models by Critique Reinforcement Learning
作者: Chi Ruan, Dongfu Jiang, Yubo Wang, Wenhu Chen
分类: cs.CL
发布日期: 2025-09-26
💡 一句话要点
提出Critique-Coder,通过批判强化学习提升代码生成模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 代码生成 强化学习 批判学习 大型语言模型 推理能力
📋 核心要点
- 现有强化学习方法在训练代码生成模型时,缺乏对模型批判和反思能力的培养。
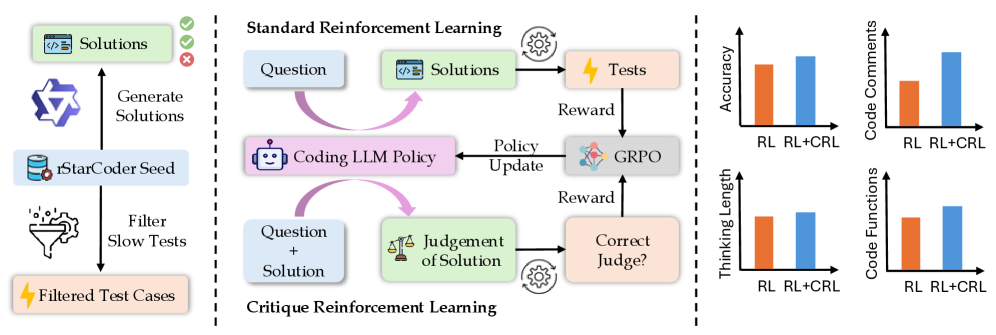
- 提出批判强化学习(CRL),通过让模型生成对代码的批判,并根据批判的正确性进行奖励,来提升模型的批判能力。
- Critique-Coder在代码生成和通用推理任务上均优于仅使用RL的模型,表明CRL能有效提升模型的推理和批判能力。
📝 摘要(中文)
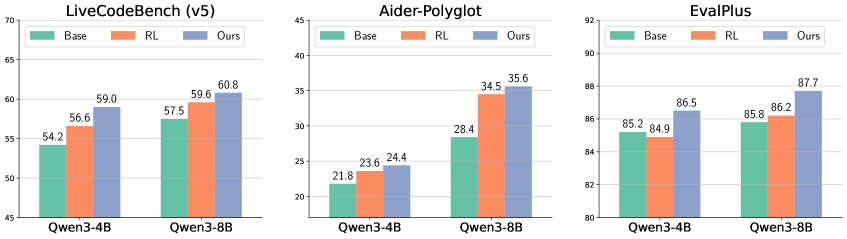
强化学习(RL)已成为一种流行的训练范式,尤其是在与推理模型结合使用时。然而,它主要关注生成响应,缺乏明确培养批判或反思的机制。最近的一些研究表明,明确地教导大型语言模型(LLM)如何进行批判是有益的。受此启发,我们提出了批判强化学习(CRL),其中模型被要求为给定的(问题,解决方案)对生成批判。奖励完全取决于生成的批判的最终判断标签是否与真实判断一致。在此基础上,我们引入了Critique-Coder,它通过将20%的标准RL数据替换为CRL数据,在RL和CRL的混合数据上进行训练。我们在不同的基准上对多个模型(Critique-Coder)进行微调和评估,以展示它们相对于仅使用RL模型的优势。结果表明,Critique-Coder在所有评估的基准上始终优于仅使用RL的基线模型。值得注意的是,我们的Critique-Coder-8B在LiveCodeBench (v5)上可以达到60%以上,优于其他推理模型,如DeepCoder-14B和GPT-o1。除了代码生成,Critique-Coder还表现出更强的通用推理能力,这体现在其在BBEH数据集中的逻辑推理任务上的更好表现。这表明,在编码数据集上应用CRL可以增强通用推理和批判能力,这些能力可以跨广泛的任务转移。因此,我们认为CRL是LLM推理的标准RL的一个很好的补充。
🔬 方法详解
问题定义:现有基于强化学习的代码生成模型训练方法,主要关注生成正确的代码,而忽略了模型对代码质量进行评估和反思的能力。这种缺陷导致模型难以识别和纠正自身生成的错误,限制了其性能的进一步提升。
核心思路:论文的核心思路是通过引入批判环节,让模型学习如何评估代码的质量,并根据评估结果进行改进。具体来说,模型需要对给定的问题和解决方案生成批判,并根据批判的正确性获得奖励。这种方式可以促使模型更加关注代码的细节和潜在问题,从而提高代码生成的质量。
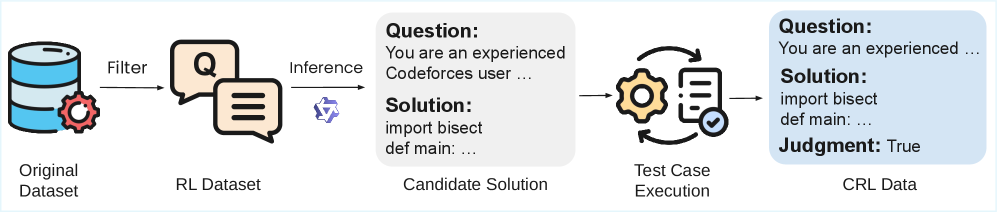
技术框架:Critique-Coder的训练框架是基于强化学习的,但引入了批判强化学习(CRL)作为补充。具体流程如下:首先,模型接收一个问题和对应的解决方案;然后,模型生成对该解决方案的批判;接着,根据生成的批判的正确性,计算奖励;最后,使用强化学习算法更新模型参数。在训练数据方面,作者将20%的标准RL数据替换为CRL数据,以平衡代码生成和批判学习。
关键创新:论文的关键创新在于提出了批判强化学习(CRL)的概念,并将其应用于代码生成模型的训练中。与传统的强化学习方法相比,CRL更加注重培养模型的批判性思维和反思能力。这种方法可以有效地提高代码生成的质量和模型的通用推理能力。
关键设计:在奖励函数的设计上,论文采用二元奖励,即如果模型生成的批判的最终判断标签与真实标签一致,则获得奖励,否则不获得奖励。这种设计简单有效,可以促使模型更加关注批判的正确性。在模型结构方面,作者使用了现有的代码生成模型,并对其进行了微调,以适应CRL的训练方式。具体使用的模型包括CodeGen和StarCoder等。
🖼️ 关键图片
📊 实验亮点
Critique-Coder在LiveCodeBench (v5)上取得了显著的性能提升,Critique-Coder-8B达到了60%以上的准确率,超过了DeepCoder-14B和GPT-o1等模型。此外,在BBEH数据集的逻辑推理任务上,Critique-Coder也表现出更好的性能,表明该方法能够提升模型的通用推理能力。
🎯 应用场景
该研究成果可应用于智能编程助手、自动化代码审查、软件测试等领域。通过提升代码生成模型的批判和推理能力,可以帮助开发者更高效地编写高质量的代码,并减少软件缺陷。此外,该方法还可以推广到其他需要批判性思维的任务中,如文本摘要、机器翻译等。
📄 摘要(原文)
Reinforcement Learning (RL) has emerged as a popular training paradigm, particularly when paired with reasoning models. While effective, it primarily focuses on generating responses and lacks mechanisms to explicitly foster critique or reflection. Several recent studies, like Critique-Fine-Tuning (CFT) and Critique-Guided-Distillation (CGD) have shown the benefits of explicitly teaching LLMs how to critique. Motivated by them, we propose Critique Reinforcement Learning (CRL), where the model is tasked with generating a critique for a given (question, solution) pair. The reward is determined solely by whether the final judgment label $c \in {\texttt{True}, \texttt{False}}$ of the generated critique aligns with the ground-truth judgment $c^*$. Building on this point, we introduce \textsc{Critique-Coder}, which is trained on a hybrid of RL and CRL by substituting 20\% of the standard RL data with CRL data. We fine-tune multiple models (\textsc{Critique-Coder}) and evaluate them on different benchmarks to show their advantages over RL-only models. We show that \textsc{Critique-Coder} consistently outperforms RL-only baselines on all the evaluated benchmarks. Notably, our \textsc{Critique-Coder-8B} can reach over 60\% on LiveCodeBench (v5), outperforming other reasoning models like DeepCoder-14B and GPT-o1. Beyond code generation, \textsc{Critique-Coder} also demonstrates enhanced general reasoning abilities, as evidenced by its better performance on logic reasoning tasks from the BBEH dataset. This indicates that the application of CRL on coding datasets enhances general reasoning and critique abilities, which are transferable across a broad range of tasks. Hence, we believe that CRL works as a great complement to standard RL for LLM reasoning.