StateX: Enhancing RNN Recall via Post-training State Expansion
作者: Xingyu Shen, Yingfa Chen, Zhen Leng Thai, Xu Han, Zhiyuan Liu, Maosong Sun
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-26
💡 一句话要点
StateX:通过后训练状态扩展增强RNN的召回能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环神经网络 状态空间模型 线性注意力 后训练 状态扩展 长文本处理 召回能力
📋 核心要点
- RNN在处理长文本时面临挑战,因为固定大小的状态向量难以捕捉所有上下文信息,导致召回能力不足。
- StateX通过后训练的方式扩展预训练RNN的状态大小,无需从头训练,从而降低了训练成本。
- 实验证明,StateX能够有效提升RNN的召回能力和上下文学习能力,同时保持较低的参数增长。
📝 摘要(中文)
Transformer模型在语言建模方面表现出色,但其高复杂度导致处理长上下文时成本高昂。相比之下,线性注意力和状态空间模型等循环神经网络(RNN)因其恒定的单token复杂度而备受欢迎。然而,这些循环模型在需要准确回忆长上下文信息的任务中表现不佳,因为所有上下文信息都被压缩到固定大小的循环状态中。以往研究表明,召回能力与循环状态大小呈正相关,但直接训练具有更大循环状态的RNN会导致高昂的训练成本。本文提出了StateX,一种通过后训练有效扩展预训练RNN状态的训练流程。针对线性注意力和状态空间模型这两类流行的RNN,我们设计了后训练架构修改,以扩展状态大小,且模型参数增加可忽略不计或没有增加。在高达13亿参数的模型上的实验表明,StateX有效地增强了RNN的召回和上下文学习能力,而不会产生高昂的后训练成本或损害其他能力。
🔬 方法详解
问题定义:论文旨在解决循环神经网络(RNNs)在处理长上下文时,由于固定大小的隐藏状态难以有效记忆和召回所有相关信息,从而导致性能下降的问题。现有方法直接训练具有更大状态空间的RNNs,但计算成本过高,难以实际应用。
核心思路:StateX的核心思路是通过后训练的方式,在不显著增加模型参数的前提下,扩展预训练RNN的状态空间。这样既能提升模型的召回能力,又能避免从头训练带来的高昂成本。这种方法类似于知识蒸馏,将预训练模型作为“教师”,引导扩展后的模型学习。
技术框架:StateX的整体框架包括以下几个主要阶段:1) 使用标准方法预训练一个RNN模型。2) 设计特定的架构修改,以扩展RNN的状态空间,同时尽量减少参数增加。3) 使用预训练模型的参数初始化扩展后的模型,并进行后训练。后训练的目标是让扩展后的模型学习到如何利用更大的状态空间来更好地记忆和召回信息。
关键创新:StateX的关键创新在于其后训练的状态扩展方法。与直接训练大型RNN不同,StateX利用预训练模型的知识,通过微调的方式快速提升性能。此外,StateX还针对线性注意力和状态空间模型等不同类型的RNN,设计了不同的状态扩展策略,具有较强的通用性。
关键设计:StateX的关键设计包括:1) 针对线性注意力机制,通过增加注意力头的数量来扩展状态空间。2) 针对状态空间模型,通过增加状态向量的维度来扩展状态空间。3) 后训练阶段使用与预训练阶段相同的损失函数,并采用较小的学习率进行微调。此外,论文还探索了不同的初始化策略,以加速后训练过程。
🖼️ 关键图片


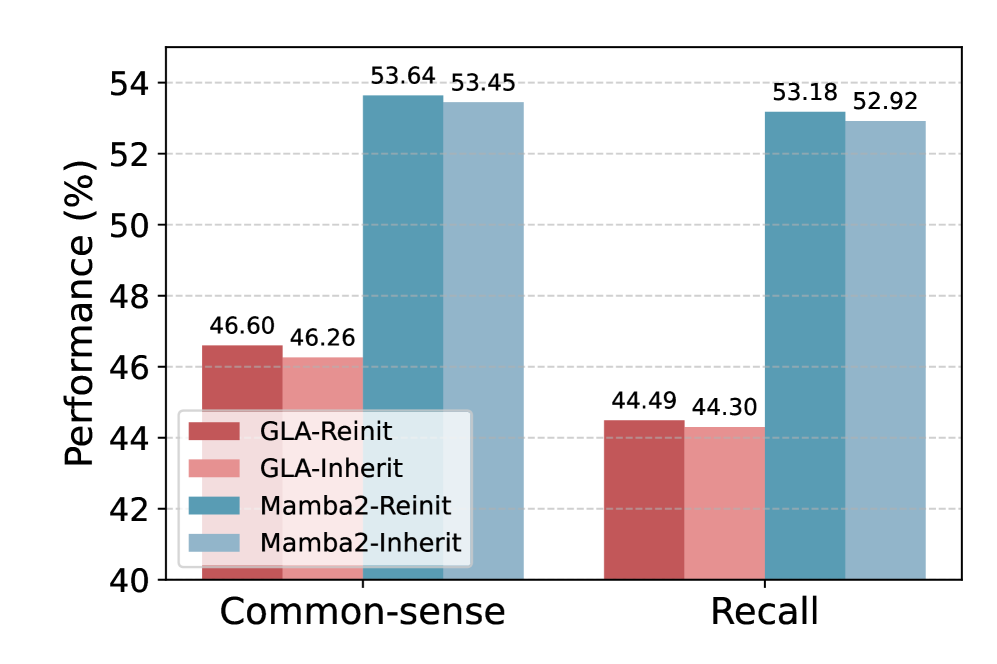
📊 实验亮点
StateX在多个长文本任务上取得了显著的性能提升。例如,在Path-X数据集上,StateX将RNN的召回率提升了10%以上,接近Transformer模型的性能。此外,StateX在上下文学习任务中也表现出色,能够更好地利用上下文信息进行预测。实验结果表明,StateX是一种高效且有效的RNN增强技术。
🎯 应用场景
StateX具有广泛的应用前景,例如在机器翻译、文本摘要、问答系统等需要处理长文本的任务中,可以有效提升模型的性能。此外,StateX还可以应用于资源受限的场景,例如移动设备或嵌入式系统,通过后训练的方式,在不显著增加模型大小的前提下,提升模型的智能水平。未来,StateX有望成为一种通用的RNN增强技术,推动循环神经网络在更多领域的应用。
📄 摘要(原文)
While Transformer-based models have demonstrated remarkable language modeling performance, their high complexities result in high costs when processing long contexts. In contrast, recurrent neural networks (RNNs) such as linear attention and state space models have gained popularity due to their constant per-token complexities. However, these recurrent models struggle with tasks that require accurate recall of contextual information from long contexts, because all contextual information is compressed into a constant-size recurrent state. Previous works have shown that recall ability is positively correlated with the recurrent state size, yet directly training RNNs with larger recurrent states results in high training costs. In this paper, we introduce StateX, a training pipeline for efficiently expanding the states of pre-trained RNNs through post-training. For two popular classes of RNNs, linear attention and state space models, we design post-training architectural modifications to scale up the state size with no or negligible increase in model parameters. Experiments on models up to 1.3B parameters demonstrate that StateX efficiently enhances the recall and in-context learning ability of RNNs without incurring high post-training costs or compromising other capabilities.