We Think, Therefore We Align LLMs to Helpful, Harmless and Honest Before They Go Wrong
作者: Gautam Siddharth Kashyap, Mark Dras, Usman Naseem
分类: cs.CL
发布日期: 2025-09-26 (更新: 2026-01-19)
💡 一句话要点
提出自适应多分支引导(AMBS)框架,提升LLM在HHH目标上的对齐效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 多目标优化 引导向量 Transformer解码器 灾难性遗忘 推理碎片化 自适应多分支引导
📋 核心要点
- 现有LLM对齐方法在优化单一目标时易发生灾难性遗忘,且多目标独立优化易导致推理碎片化。
- AMBS框架通过共享表示和策略-参考引导,实现多目标对齐,同时保持跨目标一致性。
- 实验表明,AMBS在多个7B LLM上显著提升HHH对齐效果,并减少不安全输出。
📝 摘要(中文)
大型语言模型(LLM)在多个目标(有用性、无害性和诚实性,简称HHH)上的对齐对于安全可靠的部署至关重要。先前的工作使用引导向量(注入到隐藏状态中的小控制信号)来引导LLM的输出,通常通过一对一(1-to-1)Transformer解码器。在这种设置下,优化单个对齐目标可能会无意中覆盖为其他目标学习的表示,导致灾难性遗忘。最近的方法通过一对多(1-to-N)Transformer解码器扩展了引导向量。虽然这减轻了灾难性遗忘,但简单的多分支设计独立地优化每个目标,这可能导致推理碎片化——跨HHH目标的输出可能变得不一致。我们提出了自适应多分支引导(AMBS),这是一个两阶段的1-to-N框架,用于统一和高效的多目标对齐。在第一阶段,Transformer层的注意力后隐藏状态被计算一次,以形成共享表示。在第二阶段,该表示被克隆到并行分支中,并通过策略-参考机制进行引导,从而实现特定于目标的控制,同时保持跨目标的一致性。在Alpaca、BeaverTails和TruthfulQA上的实证评估表明,AMBS始终如一地提高了多个7B LLM骨干网络上的HHH对齐。例如,在DeepSeek-7B上,与简单的1-to-N基线相比,AMBS将平均对齐分数提高了+32.4%,并将不安全输出减少了11.0%,同时保持了与最先进方法相当的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在同时对齐多个目标(有用性、无害性和诚实性,即HHH)时面临的挑战。现有方法,如基于一对一Transformer解码器的引导向量方法,容易发生灾难性遗忘,即优化一个目标会损害其他目标的性能。而简单的一对多Transformer解码器虽然缓解了遗忘问题,但独立优化每个目标会导致推理碎片化,使得LLM在不同目标上的输出不一致。
核心思路:论文的核心思路是提出一种自适应多分支引导(AMBS)框架,该框架通过共享表示和策略-参考引导机制,实现多目标对齐,同时保持跨目标的一致性。AMBS的关键在于将Transformer层的隐藏状态进行共享,并在后续分支中进行目标特定的引导,从而避免了独立优化带来的问题。
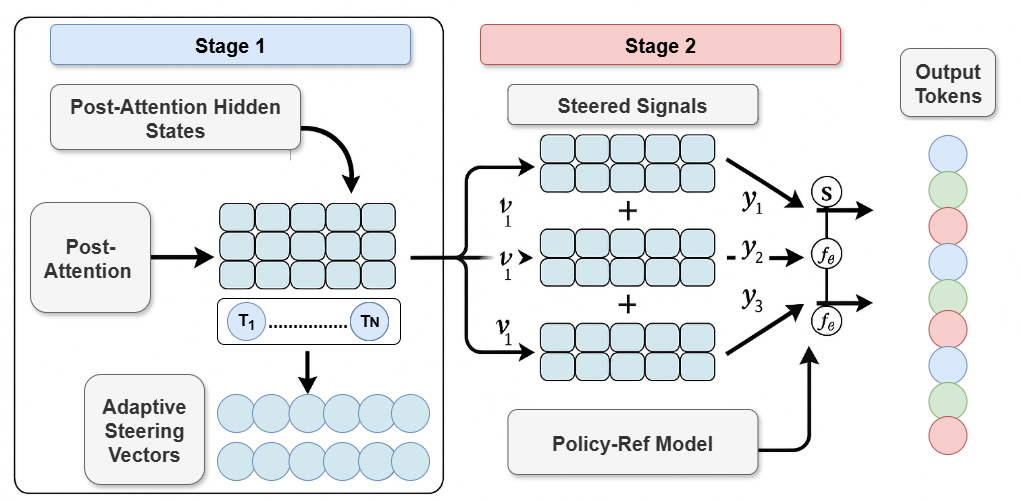
技术框架:AMBS框架包含两个主要阶段:第一阶段是共享表示计算阶段,Transformer层的注意力后隐藏状态被计算一次,形成一个共享的表示。第二阶段是多分支引导阶段,该共享表示被克隆到多个并行分支中,每个分支对应一个HHH目标。每个分支通过策略-参考机制进行引导,实现目标特定的控制。
关键创新:AMBS最重要的技术创新点在于其共享表示和策略-参考引导机制。共享表示避免了灾难性遗忘,策略-参考引导则保证了跨目标的一致性。与现有方法相比,AMBS不再是独立地优化每个目标,而是通过共享信息和引导策略,实现协同优化。
关键设计:AMBS的关键设计包括:1) 使用Transformer层的注意力后隐藏状态作为共享表示,因为它包含了丰富的上下文信息。2) 采用策略-参考机制进行引导,该机制允许每个分支根据其特定目标调整引导策略,同时参考其他分支的信息,以保持一致性。3) AMBS是一个两阶段框架,可以灵活地应用于不同的LLM骨干网络。
🖼️ 关键图片
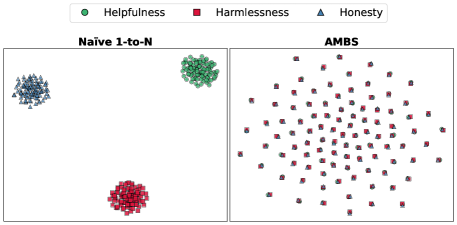
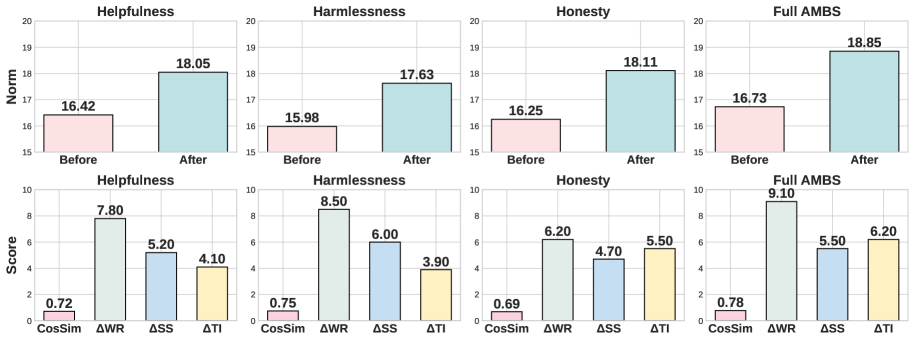
📊 实验亮点
实验结果表明,AMBS在Alpaca、BeaverTails和TruthfulQA等数据集上,对多个7B LLM骨干网络(如DeepSeek-7B)的HHH对齐效果均有显著提升。例如,在DeepSeek-7B上,与简单的1-to-N基线相比,AMBS将平均对齐分数提高了+32.4%,并将不安全输出减少了11.0%,同时保持了与最先进方法相当的性能。
🎯 应用场景
该研究成果可应用于各种需要安全可靠LLM输出的场景,例如智能客服、内容生成、教育辅导等。通过提升LLM在有用性、无害性和诚实性上的对齐,可以减少LLM产生有害或不准确信息的风险,提高用户信任度,并促进LLM在更广泛领域的应用。
📄 摘要(原文)
Alignment of Large Language Models (LLMs) along multiple objectives-helpfulness, harmlessness, and honesty (HHH)-is critical for safe and reliable deployment. Prior work has used steering vector-small control signals injected into hidden states-to guide LLM outputs, typically via one-to-one (1-to-1) Transformer decoders. In this setting, optimizing a single alignment objective can inadvertently overwrite representations learned for other objectives, leading to catastrophic forgetting. More recent approaches extend steering vectors via one-to-many (1-to-N) Transformer decoders. While this alleviates catastrophic forgetting, naive multi-branch designs optimize each objective independently, which can cause inference fragmentation-outputs across HHH objectives may become inconsistent. We propose Adaptive Multi-Branch Steering (AMBS), a two-stage 1-to-N framework for unified and efficient multi-objective alignment. In Stage I, post-attention hidden states of the Transformer layer are computed once to form a shared representation. In Stage II, this representation is cloned into parallel branches and steered via a policy-reference mechanism, enabling objective-specific control while maintaining cross-objective consistency. Empirical evaluations on Alpaca, BeaverTails, and TruthfulQA show that AMBS consistently improves HHH alignment across multiple 7B LLM backbones. For example, on DeepSeek-7B, AMBS improves average alignment scores by +32.4% and reduces unsafe outputs by 11.0% compared to a naive 1-to-N baseline, while remaining competitive with state-of-the-art methods.