Representing LLMs in Prompt Semantic Task Space
作者: Idan Kashani, Avi Mendelson, Yaniv Nemcovsky
分类: cs.CL, cs.LG
发布日期: 2025-09-26
备注: Accepted to Findings of the Association for Computational Linguistics: EMNLP 2025
DOI: 10.18653/v1/2025.findings-emnlp.456
💡 一句话要点
提出一种免训练方法,将LLM表示为提示语义任务空间中的线性算子,用于模型选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型表示 提示学习 模型选择 零样本学习
📋 核心要点
- 现有LLM表示学习方法可扩展性差,需昂贵再训练,且表示空间难以解释。
- 将LLM表示为提示语义任务空间中的线性算子,无需训练,高效且可解释。
- 实验表明,该方法在模型选择和成功预测任务上表现出色,尤其是在样本外场景。
📝 摘要(中文)
大型语言模型(LLM)在各种任务上取得了令人瞩目的成果,并且不断扩展的公共存储库包含大量预训练模型。因此,为给定任务确定性能最佳的LLM是一个重大挑战。先前的工作已经提出了学习LLM表示来解决这个问题。然而,这些方法的可扩展性有限,并且需要昂贵的再训练才能涵盖更多的模型和数据集。此外,生成的表示利用了难以解释的不同空间。本研究提出了一种高效、免训练的方法,将LLM表示为提示语义任务空间中的线性算子,从而为模型的应用提供了一种高度可解释的表示。我们的方法利用几何属性的闭式计算,并确保卓越的可扩展性和实时适应动态扩展的存储库。我们在成功预测和模型选择任务上展示了我们的方法,在样本外场景中取得了具有竞争力的或最先进的结果。
🔬 方法详解
问题定义:现有方法在表示大型语言模型(LLM)时,面临可扩展性问题和高昂的再训练成本。为了适应不断增长的模型和数据集,需要一种更高效的表示方法。此外,现有方法产生的LLM表示通常位于难以解释的空间中,限制了其应用。
核心思路:该论文的核心思路是将LLM表示为提示语义任务空间中的线性算子。通过这种方式,每个LLM都可以用一组线性变换来描述其在不同提示上的行为。这种表示方法无需训练,并且可以直接利用提示的语义信息,从而提高了可解释性。
技术框架:该方法主要包含以下几个阶段:1) 定义提示语义任务空间:选择一组具有代表性的提示,构成任务空间的基础。2) 计算LLM在该空间中的表示:对于每个LLM,计算其在每个提示上的输出,并将其表示为该提示语义任务空间中的一个向量。3) 将LLM表示为线性算子:利用闭式解计算LLM在该空间中的线性变换矩阵。4) 应用于下游任务:将LLM的线性算子表示用于模型选择、成功预测等任务。
关键创新:该方法最重要的创新点在于提出了一种免训练的LLM表示方法,该方法将LLM表示为提示语义任务空间中的线性算子。与现有方法相比,该方法具有更高的可扩展性、更强的可解释性,并且无需昂贵的再训练。
关键设计:该方法利用闭式解计算LLM的线性算子表示,避免了迭代优化过程,从而提高了计算效率。此外,该方法可以灵活地选择不同的提示集来定义任务空间,从而适应不同的应用场景。关键参数包括提示集的大小和选择策略。
🖼️ 关键图片
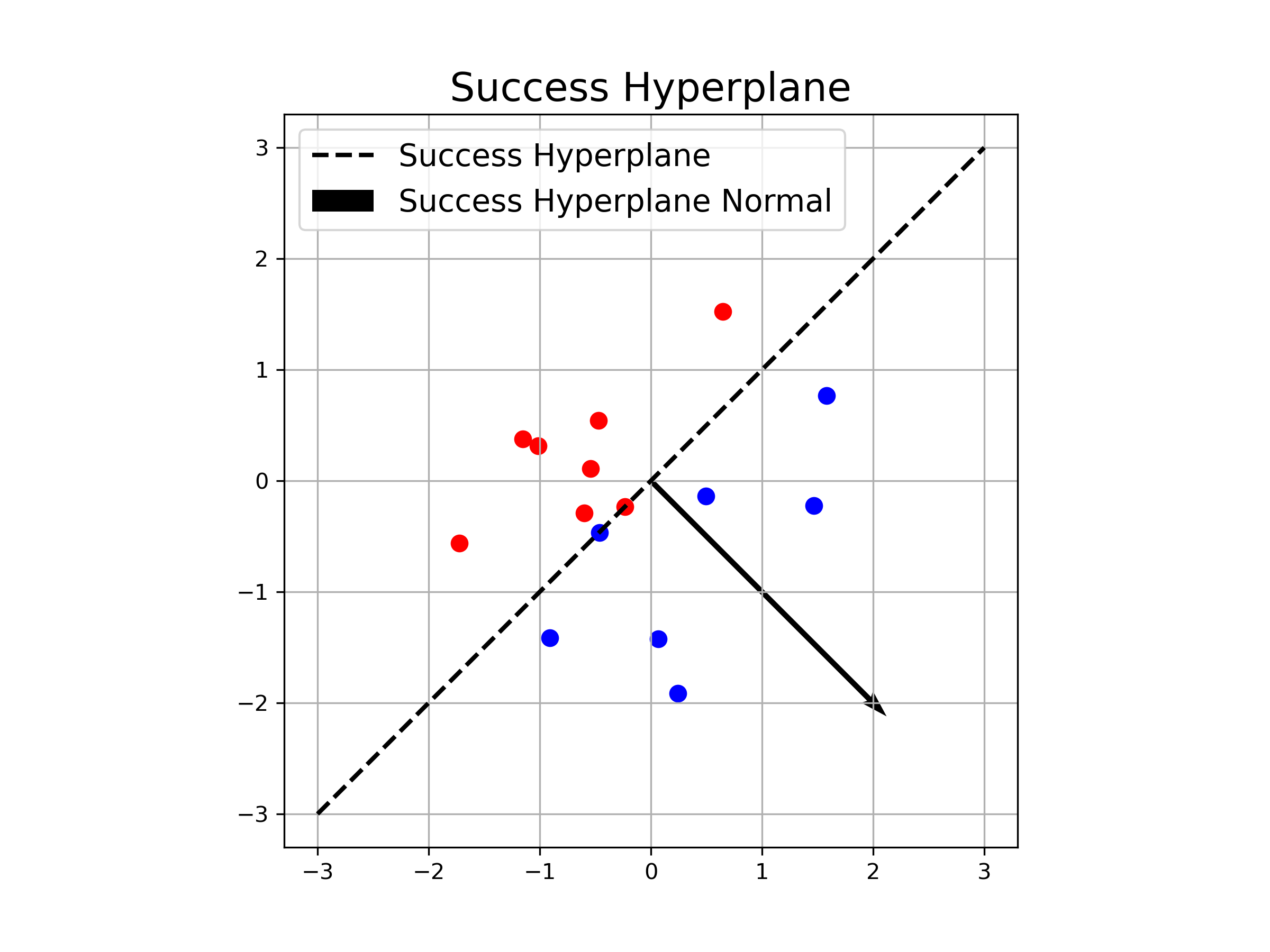


📊 实验亮点
实验结果表明,该方法在模型选择和成功预测任务上取得了具有竞争力的或最先进的结果,尤其是在样本外场景中表现出色。与现有方法相比,该方法在保持或提高性能的同时,显著降低了计算成本和训练开销。具体性能数据在论文中给出。
🎯 应用场景
该研究成果可应用于LLM模型选择、性能预测和模型优化等领域。通过将LLM表示为提示语义任务空间中的线性算子,可以更高效地评估和比较不同LLM的性能,从而为用户选择最适合其任务的模型。此外,该方法还可以用于预测LLM在特定任务上的成功率,并指导模型优化。
📄 摘要(原文)
Large language models (LLMs) achieve impressive results over various tasks, and ever-expanding public repositories contain an abundance of pre-trained models. Therefore, identifying the best-performing LLM for a given task is a significant challenge. Previous works have suggested learning LLM representations to address this. However, these approaches present limited scalability and require costly retraining to encompass additional models and datasets. Moreover, the produced representation utilizes distinct spaces that cannot be easily interpreted. This work presents an efficient, training-free approach to representing LLMs as linear operators within the prompts' semantic task space, thus providing a highly interpretable representation of the models' application. Our method utilizes closed-form computation of geometrical properties and ensures exceptional scalability and real-time adaptability to dynamically expanding repositories. We demonstrate our approach on success prediction and model selection tasks, achieving competitive or state-of-the-art results with notable performance in out-of-sample scenarios.