Exploring Solution Divergence and Its Effect on Large Language Model Problem Solving
作者: Hang Li, Kaiqi Yang, Yucheng Chu, Hui Liu, Jiliang Tang
分类: cs.CL, cs.AI
发布日期: 2025-09-26
备注: 17 pages, 11 figures
💡 一句话要点
提出基于解空间差异性的LLM训练与评估方法,提升问题解决能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 解空间差异性 问题解决能力 有监督微调 强化学习
📋 核心要点
- 现有LLM训练方法主要依赖标注数据或任务反馈,忽略了解空间多样性对问题解决能力的影响。
- 论文提出利用解空间差异性作为新的指标,指导LLM的监督微调和强化学习,提升模型性能。
- 实验结果表明,在多个问题领域,使用解空间差异性能够显著提高LLM的问题解决成功率。
📝 摘要(中文)
大型语言模型(LLMs)已被广泛应用于解决各类问题。目前的研究主要集中于通过有监督微调(SFT)或强化学习(RL)来提升LLM的性能。本文提出了一种新的视角:研究LLM为单个问题生成的解空间差异性。研究表明,更高的解空间差异性与模型更好的问题解决能力呈正相关。基于此,本文提出将解空间差异性作为一个新的指标,用于支持SFT和RL策略。在三个代表性的问题领域进行的实验表明,使用解空间差异性能够持续提高成功率。这些结果表明,解空间差异性是推进LLM训练和评估的一种简单而有效的工具。
🔬 方法详解
问题定义:论文旨在解决如何更有效地训练和评估大型语言模型(LLMs),以提高其问题解决能力。现有方法主要依赖于有监督微调(SFT)和强化学习(RL),但忽略了解空间多样性对模型性能的潜在影响。现有方法的痛点在于,它们没有充分利用LLM生成多个解的能力,以及这些解之间的差异性所蕴含的信息。
核心思路:论文的核心思路是,LLM为同一问题生成多个不同的解,这些解之间的差异性(即解空间差异性)与模型的问题解决能力之间存在正相关关系。因此,可以通过最大化解空间差异性来提升LLM的性能。这种思路的合理性在于,更广泛的解空间可能包含更优的解,并且能够帮助模型更好地理解问题的本质。
技术框架:论文提出的方法可以应用于SFT和RL两种训练框架。对于SFT,可以将解空间差异性作为额外的奖励信号,引导模型生成更多样化的解。对于RL,可以使用解空间差异性来评估不同策略的优劣,并选择能够产生更高差异性的策略。整体流程包括:1) LLM为同一问题生成多个解;2) 计算这些解之间的差异性;3) 将差异性作为奖励信号或评估指标,用于指导模型训练。
关键创新:论文最重要的技术创新点在于,首次将解空间差异性与LLM的问题解决能力联系起来,并将其作为一个新的指标用于指导模型训练。与现有方法相比,该方法不需要额外的标注数据或任务反馈,而是直接利用LLM自身生成的信息。
关键设计:论文中,解空间差异性的具体计算方法未知,需要进一步查阅论文细节。但可以推测,可能使用了诸如文本相似度、语义距离等指标来衡量不同解之间的差异。此外,如何将解空间差异性有效地融入到SFT和RL的训练过程中,也是一个关键的设计问题。例如,可以设计一个损失函数,鼓励模型生成具有更高差异性的解。
🖼️ 关键图片

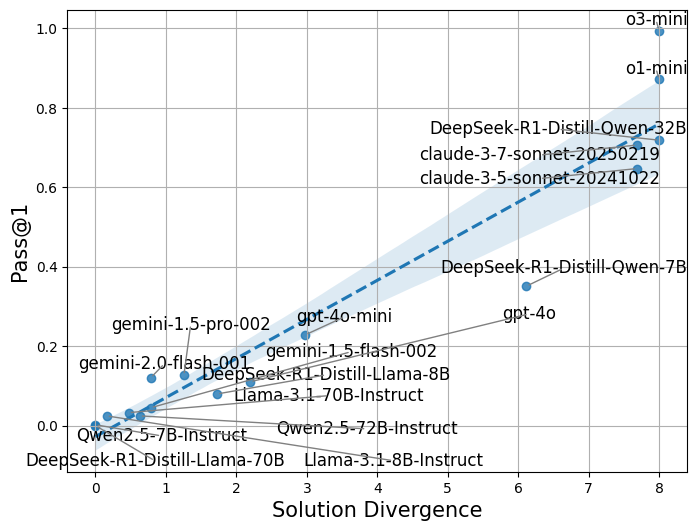
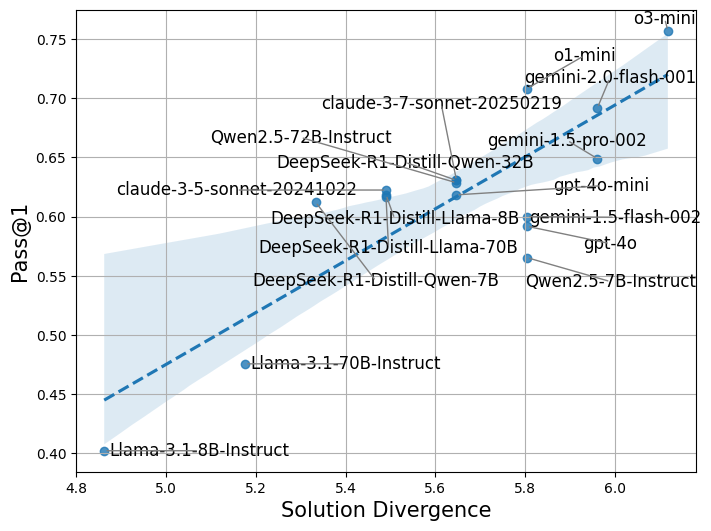
📊 实验亮点
实验结果表明,使用解空间差异性能够持续提高LLM在三个代表性问题领域(具体领域未知)的成功率。具体的性能提升幅度未知,但论文强调了该方法的一致性和有效性,表明解空间差异性是一个有价值的指标。
🎯 应用场景
该研究成果可广泛应用于各种需要LLM解决问题的领域,如智能客服、自动编程、文本生成等。通过优化LLM的解空间差异性,可以提高模型生成高质量、多样化解决方案的能力,从而提升用户体验和工作效率。未来,该方法有望成为LLM训练和评估的标准流程之一。
📄 摘要(原文)
Large language models (LLMs) have been widely used for problem-solving tasks. Most recent work improves their performance through supervised fine-tuning (SFT) with labeled data or reinforcement learning (RL) from task feedback. In this paper, we study a new perspective: the divergence in solutions generated by LLMs for a single problem. We show that higher solution divergence is positively related to better problem-solving abilities across various models. Based on this finding, we propose solution divergence as a novel metric that can support both SFT and RL strategies. We test this idea on three representative problem domains and find that using solution divergence consistently improves success rates. These results suggest that solution divergence is a simple but effective tool for advancing LLM training and evaluation.