Transformers Can Learn Connectivity in Some Graphs but Not Others
作者: Amit Roy, Abulhair Saparov
分类: cs.CL, cs.AI, cs.LG, cs.LO
发布日期: 2025-09-26
备注: Under Review
💡 一句话要点
研究表明Transformer在网格状图上学习连通性,但在复杂图上存在困难
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 图神经网络 连通性 传递关系 知识图谱 因果推理 模型泛化
📋 核心要点
- 现有研究缺乏对Transformer模型从训练数据中学习传递关系(图连通性)能力的深入探索,特别是模型规模的影响。
- 该研究通过生成不同类型的有向图,训练不同规模的Transformer模型,评估其学习图连通性的能力。
- 实验表明,Transformer擅长学习低维网格图的连通性,但难以处理高维或包含大量不连通组件的复杂图。
📝 摘要(中文)
本研究探讨了Transformer模型学习有向图连通性的能力,这对于确保基于Transformer的大型语言模型(LLM)推理的正确性至关重要。以往研究主要关注Transformer通过上下文学习进行传递关系推理的能力,而忽略了从训练样本中学习传递关系以及模型规模的影响。本文通过生成不同大小的有向图来训练不同规模的Transformer模型,并评估其在不同图大小下推断传递关系的能力。研究发现,Transformer能够学习“网格状”有向图的连通性,其中每个节点可以嵌入到低维子空间中,并且连通性可以容易地从节点的嵌入中推断出来。网格图的维度是Transformer学习连通性任务能力的一个强预测指标,高维网格图比低维网格图更具挑战性。此外,增加模型规模可以提高模型在网格图上推断连通性的泛化能力。然而,如果图不是网格图,并且包含许多不连通的组件,Transformer很难学习连通性任务,尤其是在组件数量很大时。
🔬 方法详解
问题定义:论文旨在研究Transformer模型能否从训练数据中学习有向图的连通性。现有方法主要关注Transformer的上下文学习能力,忽略了其从训练样本中学习传递关系的能力,以及模型规模对学习效果的影响。此外,现有研究缺乏对不同类型图结构对Transformer学习能力影响的系统性分析。
核心思路:论文的核心思路是通过控制图的结构,特别是图的维度和连通性,来研究Transformer模型学习图连通性的能力。作者假设,如果图的节点可以嵌入到低维空间,并且连通性可以容易地从节点的嵌入中推断出来,那么Transformer更容易学习。反之,如果图的维度较高,或者包含大量不连通的组件,那么Transformer的学习难度会增加。
技术框架:论文的技术框架主要包括以下几个步骤:1) 生成不同类型的有向图,包括网格图和随机图;2) 使用生成的图数据训练不同规模的Transformer模型;3) 评估训练好的模型在测试集上的连通性预测准确率;4) 分析模型规模、图结构和连通性预测准确率之间的关系。
关键创新:论文的关键创新在于:1) 系统性地研究了Transformer模型从训练数据中学习图连通性的能力;2) 揭示了图的结构对Transformer学习能力的影响,特别是图的维度和连通性;3) 发现模型规模对学习效果的影响,即更大的模型在网格图上具有更好的泛化能力。
关键设计:论文的关键设计包括:1) 使用不同维度的网格图来控制图的复杂度;2) 使用随机图来模拟更复杂的图结构;3) 使用不同规模的Transformer模型来研究模型规模的影响;4) 使用准确率作为评估指标来衡量模型的连通性预测能力。
🖼️ 关键图片


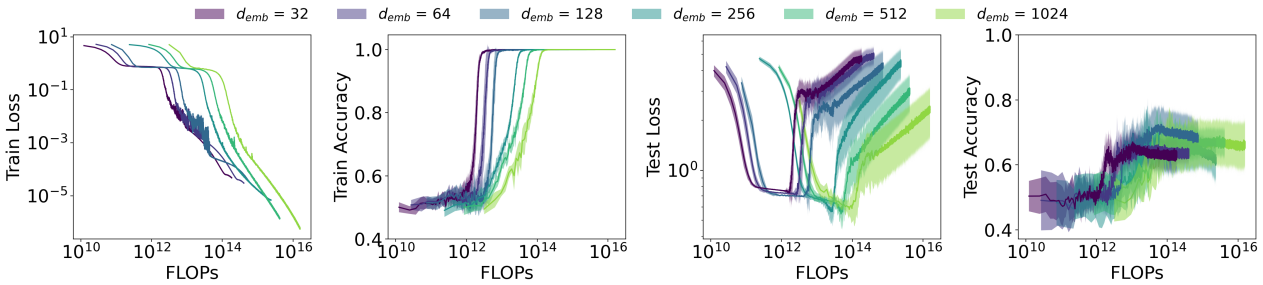
📊 实验亮点
实验结果表明,Transformer模型能够有效学习低维网格图的连通性,并且随着模型规模的增加,泛化能力也随之提升。然而,在高维网格图和包含大量不连通组件的随机图上,Transformer的学习效果显著下降。这些发现揭示了Transformer在图推理方面的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于提升大型语言模型在知识图谱推理、因果关系推断等任务中的能力。通过理解Transformer模型在不同图结构下的学习特性,可以设计更有效的训练策略和模型结构,从而提高模型在复杂推理任务中的性能。此外,该研究对于开发更鲁棒和可信赖的人工智能系统具有重要意义。
📄 摘要(原文)
Reasoning capability is essential to ensure the factual correctness of the responses of transformer-based Large Language Models (LLMs), and robust reasoning about transitive relations is instrumental in many settings, such as causal inference. Hence, it is essential to investigate the capability of transformers in the task of inferring transitive relations (e.g., knowing A causes B and B causes C, then A causes C). The task of inferring transitive relations is equivalent to the task of connectivity in directed graphs (e.g., knowing there is a path from A to B, and there is a path from B to C, then there is a path from A to C). Past research focused on whether transformers can learn to infer transitivity from in-context examples provided in the input prompt. However, transformers' capability to infer transitive relations from training examples and how scaling affects the ability is unexplored. In this study, we seek to answer this question by generating directed graphs to train transformer models of varying sizes and evaluate their ability to infer transitive relations for various graph sizes. Our findings suggest that transformers are capable of learning connectivity on "grid-like'' directed graphs where each node can be embedded in a low-dimensional subspace, and connectivity is easily inferable from the embeddings of the nodes. We find that the dimensionality of the underlying grid graph is a strong predictor of transformers' ability to learn the connectivity task, where higher-dimensional grid graphs pose a greater challenge than low-dimensional grid graphs. In addition, we observe that increasing the model scale leads to increasingly better generalization to infer connectivity over grid graphs. However, if the graph is not a grid graph and contains many disconnected components, transformers struggle to learn the connectivity task, especially when the number of components is large.