FeatBench: Evaluating Coding Agents on Feature Implementation for Vibe Coding
作者: Haorui Chen, Chengze Li, Jia Li
分类: cs.CL, cs.AI, cs.SE
发布日期: 2025-09-26
💡 一句话要点
FeatBench:用于评估Vibe Coding中特征实现的编码智能体性能的基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vibe Coding 特征实现 代码生成 自然语言提示 基准测试
📋 核心要点
- 现有代码生成评估基准难以评估编码智能体在“vibe coding”模式下的特征实现能力,缺乏针对性。
- FeatBench基准测试专注于纯自然语言描述的特征实现任务,通过多级过滤和自动化流程保证数据质量。
- 实验结果表明,现有智能体在FeatBench上的特征实现任务中表现不佳,最高成功率仅为29.94%,揭示了该领域的挑战。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展催生了一种名为“vibe coding”的新型软件开发模式,用户通过高级自然语言与编码智能体交互。然而,现有的代码生成评估基准不足以评估智能体的vibe coding能力。现有基准存在错位,要么需要代码级规范,要么狭隘地关注问题解决,忽略了vibe coding范式中特征实现的关键场景。为了解决这一差距,我们提出了FeatBench,这是一个专注于特征实现的vibe coding新基准。我们的基准具有以下几个关键特征:1.纯自然语言提示。任务输入仅包含抽象的自然语言描述,没有任何代码或结构提示。2.严格且不断发展的数据收集过程。FeatBench建立在多级过滤管道上,以确保质量,并建立在全自动管道上以发展基准,从而减轻数据污染。3.全面的测试用例。每个任务都包括Fail-to-Pass (F2P)和Pass-to-Pass (P2P)测试,以验证正确性并防止回归。4.多样化的应用领域。该基准包括来自不同领域的存储库,以确保它反映真实世界的场景。我们在FeatBench上评估了两个最先进的智能体框架和四个领先的LLM。我们的评估表明,vibe coding范式中的特征实现是一个重大挑战,最高成功率仅为29.94%。我们的分析还揭示了一种“激进实现”的趋势,这种策略自相矛盾地导致了关键失败和卓越的软件设计。我们发布FeatBench、我们的自动化收集管道以及所有实验结果,以促进进一步的社区研究。
🔬 方法详解
问题定义:论文旨在解决现有代码生成评估基准在评估“vibe coding”模式下特征实现能力方面的不足。现有基准要么需要代码级规范,要么侧重于问题解决,忽略了用户通过自然语言描述需求,由智能体自动实现功能的场景。现有方法无法有效衡量智能体理解和实现抽象自然语言需求的能力。
核心思路:论文的核心思路是构建一个专门用于评估vibe coding中特征实现的基准测试集FeatBench。该基准测试集使用纯自然语言描述作为输入,要求智能体根据这些描述实现相应的功能。通过这种方式,可以更真实地模拟用户与编码智能体交互的场景,并更准确地评估智能体的能力。
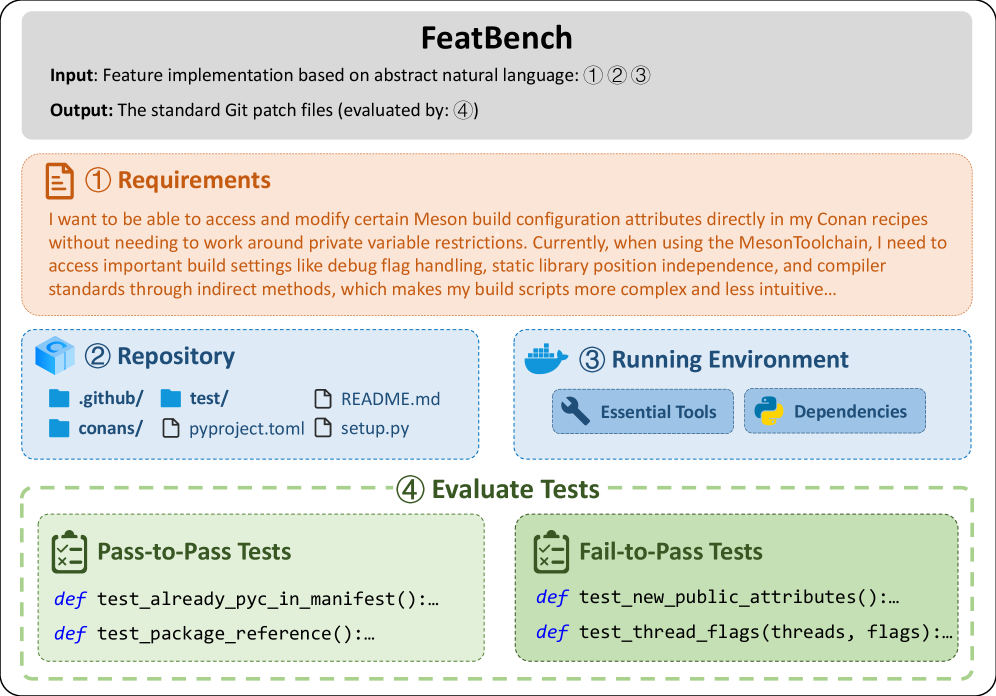
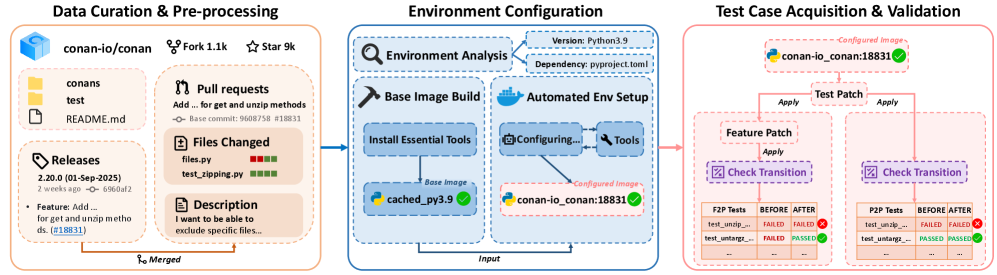
技术框架:FeatBench的构建包含以下几个主要阶段:1. 数据收集:从多个开源代码仓库中选取合适的项目。2. 任务生成:人工编写纯自然语言描述的特征实现需求。3. 数据过滤:通过多级过滤管道,包括人工审核和自动化测试,确保数据的质量和一致性。4. 测试用例生成:为每个任务生成Fail-to-Pass (F2P)和Pass-to-Pass (P2P)测试用例,用于验证智能体生成的代码的正确性和防止回归。
关键创新:FeatBench的关键创新在于其专注于评估vibe coding中的特征实现能力,并使用纯自然语言描述作为输入。与现有基准测试相比,FeatBench更贴近实际应用场景,能够更准确地评估智能体理解和实现抽象自然语言需求的能力。此外,FeatBench还采用了多级过滤和自动化流程,保证了数据的质量和一致性。
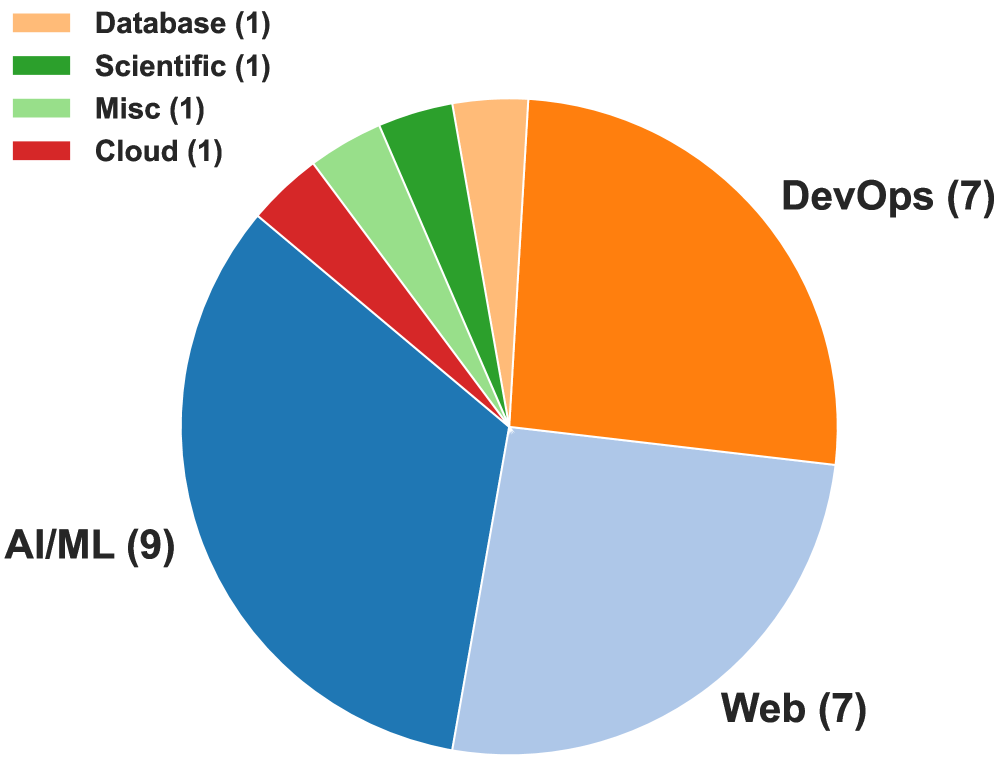
关键设计:FeatBench的关键设计包括:1. 纯自然语言描述:任务输入仅包含抽象的自然语言描述,没有任何代码或结构提示。2. 多级过滤管道:通过人工审核和自动化测试,确保数据的质量和一致性。3. F2P和P2P测试用例:用于验证智能体生成的代码的正确性和防止回归。4. 多样化的应用领域:基准测试集包含来自不同领域的代码仓库,以确保其能够反映真实世界的场景。
🖼️ 关键图片
📊 实验亮点
在FeatBench上的实验结果表明,现有智能体在特征实现任务中表现不佳,最高成功率仅为29.94%。研究还发现了一种“激进实现”的趋势,即智能体倾向于过度实现需求,这既可能导致关键错误,也可能带来更好的软件设计。这些结果揭示了vibe coding中特征实现任务的挑战,并为未来的研究提供了方向。
🎯 应用场景
FeatBench可用于评估和改进编码智能体在软件开发中的应用,尤其是在需求理解和特征实现方面。该基准测试集能够推动智能体更好地理解自然语言需求,并自动生成高质量的代码,从而提高软件开发的效率和质量。未来,FeatBench可以扩展到更多领域,并与其他基准测试集结合,形成更全面的评估体系。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has given rise to a novel software development paradigm known as "vibe coding," where users interact with coding agents through high-level natural language. However, existing evaluation benchmarks for code generation inadequately assess an agent's vibe coding capabilities. Existing benchmarks are misaligned, as they either require code-level specifications or focus narrowly on issue-solving, neglecting the critical scenario of feature implementation within the vibe coding paradiam. To address this gap, we propose FeatBench, a novel benchmark for vibe coding that focuses on feature implementation. Our benchmark is distinguished by several key features: 1. Pure Natural Language Prompts. Task inputs consist solely of abstract natural language descriptions, devoid of any code or structural hints. 2. A Rigorous & Evolving Data Collection Process. FeatBench is built on a multi-level filtering pipeline to ensure quality and a fully automated pipeline to evolve the benchmark, mitigating data contamination. 3. Comprehensive Test Cases. Each task includes Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests to verify correctness and prevent regressions. 4. Diverse Application Domains. The benchmark includes repositories from diverse domains to ensure it reflects real-world scenarios. We evaluate two state-of-the-art agent frameworks with four leading LLMs on FeatBench. Our evaluation reveals that feature implementation within the vibe coding paradigm is a significant challenge, with the highest success rate of only 29.94%. Our analysis also reveals a tendency for "aggressive implementation," a strategy that paradoxically leads to both critical failures and superior software design. We release FeatBench, our automated collection pipeline, and all experimental results to facilitate further community research.