Bridging Draft Policy Misalignment: Group Tree Optimization for Speculative Decoding
作者: Shijing Hu, Jingyang Li, Zhihui Lu, Pan Zhou
分类: cs.CL, cs.AI
发布日期: 2025-09-26
💡 一句话要点
提出Group Tree Optimization,解决推测解码中草稿策略不对齐问题,提升LLM推理速度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大型语言模型 模型加速 策略对齐 树搜索
📋 核心要点
- 现有推测解码方法训练目标与解码策略不一致,导致草稿模型性能受限,无法充分加速LLM推理。
- 提出Group Tree Optimization (GTO),通过Draft Tree Reward和Group-based Draft Policy Training,对齐训练和解码时的树策略。
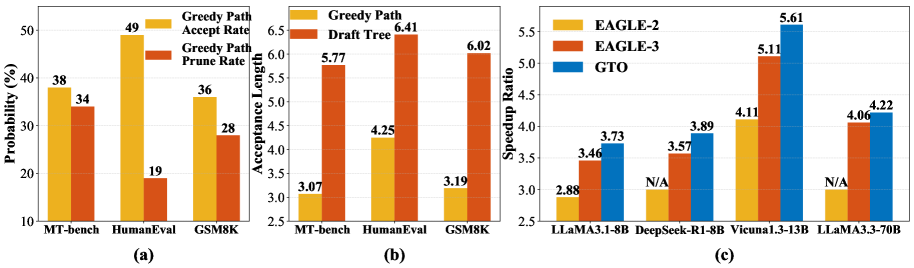
- 实验表明,GTO在多个LLM和任务上显著提升了接受长度和推理速度,优于现有SOTA方法EAGLE-3。
📝 摘要(中文)
推测解码通过轻量级草稿模型生成多个token,供目标模型并行验证,从而加速大型语言模型(LLM)的推理。然而,现有的训练目标仅优化单一贪婪草稿路径,而解码过程遵循树策略,对多个分支进行重排序和验证。这种草稿策略的不对齐限制了可实现的速度提升。我们引入了Group Tree Optimization (GTO),通过两个组成部分使训练与解码时的树策略对齐:(i)Draft Tree Reward,一种无采样的目标函数,等于目标模型下草稿树的预期接受长度,直接衡量解码性能;(ii)Group-based Draft Policy Training,一种稳定的优化方案,对比当前和冻结的参考草稿模型的树,形成去偏的、组标准化的优势,并沿着最长接受序列应用PPO风格的替代目标,以实现稳健的更新。我们进一步证明,增加我们的Draft Tree Reward可以显著提高接受长度和加速。在对话(MT-Bench)、代码(HumanEval)和数学(GSM8K)以及多个LLM(例如LLaMA-3.1-8B、LLaMA-3.3-70B、Vicuna-1.3-13B、DeepSeek-R1-Distill-LLaMA-8B)上,GTO将接受长度提高了7.4%,并在现有最先进的EAGLE-3之上额外实现了7.7%的加速。通过弥合草稿策略的不对齐,GTO为高效的LLM推理提供了一种实用、通用的解决方案。
🔬 方法详解
问题定义:推测解码旨在加速大型语言模型的推理过程。现有的推测解码方法主要优化单一的贪婪草稿路径,而实际解码过程中采用树搜索策略,对多个分支进行验证和重排序。这种训练目标与解码策略的不一致(草稿策略不对齐)限制了草稿模型的性能,导致无法充分利用推测解码的加速潜力。
核心思路:论文的核心思路是通过优化草稿模型的训练目标,使其与解码时的树搜索策略对齐。具体来说,论文提出了Group Tree Optimization (GTO),它直接优化草稿树的预期接受长度,并采用一种稳定的训练方案来更新草稿模型的策略。这样可以使草稿模型更好地适应解码时的树搜索过程,从而提高接受长度和推理速度。
技术框架:GTO主要包含两个核心模块:Draft Tree Reward和Group-based Draft Policy Training。Draft Tree Reward是一个无采样的目标函数,用于衡量草稿树的预期接受长度。Group-based Draft Policy Training是一种稳定的优化方案,它对比当前和冻结的参考草稿模型的树,形成去偏的、组标准化的优势,并沿着最长接受序列应用PPO风格的替代目标,以实现稳健的更新。整体流程是,首先使用Draft Tree Reward评估草稿树的质量,然后使用Group-based Draft Policy Training更新草稿模型的策略,从而使草稿模型更好地适应解码时的树搜索过程。
关键创新:GTO的关键创新在于它直接优化草稿树的预期接受长度,并采用一种稳定的训练方案来更新草稿模型的策略。与现有方法不同,GTO考虑了解码时的树搜索策略,从而解决了草稿策略不对齐的问题。此外,GTO还提出了一种新的优势函数计算方法,即Group-based Draft Policy Training,它可以有效地减少训练过程中的方差,提高训练的稳定性。
关键设计:Draft Tree Reward的设计基于目标模型对草稿树的验证结果,直接计算预期接受长度。Group-based Draft Policy Training的关键在于使用组标准化的优势函数,它可以有效地减少训练过程中的方差。具体来说,论文将草稿树分成多个组,然后对每个组内的优势函数进行标准化。此外,论文还采用了PPO风格的替代目标,以实现稳健的更新。具体的参数设置和网络结构等技术细节在论文中有详细描述,这里不再赘述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GTO在多个LLM(例如LLaMA-3.1-8B、LLaMA-3.3-70B、Vicuna-1.3-13B、DeepSeek-R1-Distill-LLaMA-8B)和任务(对话MT-Bench、代码HumanEval、数学GSM8K)上都取得了显著的性能提升。GTO将接受长度提高了7.4%,并在现有最先进的EAGLE-3之上额外实现了7.7%的加速。这些结果表明,GTO是一种有效且通用的推测解码优化方法。
🎯 应用场景
该研究成果可广泛应用于各种需要加速LLM推理的场景,例如在线对话系统、代码生成、机器翻译等。通过提高LLM的推理速度,可以降低计算成本,提高用户体验,并促进LLM在更多实际应用中的部署。未来,该方法可以进一步扩展到其他推测解码方法和模型架构,并与其他优化技术相结合,以实现更高的推理效率。
📄 摘要(原文)
Speculative decoding accelerates large language model (LLM) inference by letting a lightweight draft model propose multiple tokens that the target model verifies in parallel. Yet existing training objectives optimize only a single greedy draft path, while decoding follows a tree policy that re-ranks and verifies multiple branches. This draft policy misalignment limits achievable speedups. We introduce Group Tree Optimization (GTO), which aligns training with the decoding-time tree policy through two components: (i) Draft Tree Reward, a sampling-free objective equal to the expected acceptance length of the draft tree under the target model, directly measuring decoding performance; (ii) Group-based Draft Policy Training, a stable optimization scheme that contrasts trees from the current and a frozen reference draft model, forming debiased group-standardized advantages and applying a PPO-style surrogate along the longest accepted sequence for robust updates. We further prove that increasing our Draft Tree Reward provably improves acceptance length and speedup. Across dialogue (MT-Bench), code (HumanEval), and math (GSM8K), and multiple LLMs (e.g., LLaMA-3.1-8B, LLaMA-3.3-70B, Vicuna-1.3-13B, DeepSeek-R1-Distill-LLaMA-8B), GTO increases acceptance length by 7.4% and yields an additional 7.7% speedup over prior state-of-the-art EAGLE-3. By bridging draft policy misalignment, GTO offers a practical, general solution for efficient LLM inference.