Think Right, Not More: Test-Time Scaling for Numerical Claim Verification
作者: Primakov Chungkham, V Venktesh, Vinay Setty, Avishek Anand
分类: cs.CL
发布日期: 2025-09-26
备注: Accepted to EMNLP 2025, 19 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出VERIFIERFC,通过测试时缩放提升LLM在数值声明验证中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数值声明验证 事实核查 大型语言模型 测试时缩放 推理漂移
📋 核心要点
- 现有LLM在数值声明验证中面临推理漂移问题,无法有效整合信息,导致事实核查准确率低。
- 论文提出VERIFIERFC模型,通过测试时缩放(TTS)生成多条推理路径,并学习选择最佳路径。
- 实验表明,TTS能有效缓解推理漂移,自适应TTS在提升效率的同时,性能超越单次验证方法。
📝 摘要(中文)
本文针对现实世界中数值声明的事实核查问题,该问题需要多步骤推理和数值推理来验证声明的各个方面。尽管包括推理模型在内的大型语言模型(LLM)取得了巨大进展,但在需要组合和数值推理的事实核查方面仍然存在不足。它们无法理解数值方面的细微差别,并且容易出现推理漂移问题,即模型无法将各种信息置于上下文中,导致误解和推理过程的回溯。本文系统地探索了在测试时缩放计算(TTS)对LLM在复杂数值声明的事实核查任务中的影响,这需要从LLM中引出多个推理路径。我们训练了一个验证器模型(VERIFIERFC)来导航这个可能的推理路径空间,并选择一个可能导致正确判决的路径。我们观察到TTS有助于缓解推理漂移问题,从而显著提高数值声明的事实核查性能。为了提高TTS的计算效率,我们引入了一种自适应机制,该机制根据声明的感知复杂性选择性地执行TTS。这种方法比标准TTS的效率高1.8倍,同时比单次声明验证方法提高了18.8%的性能。
🔬 方法详解
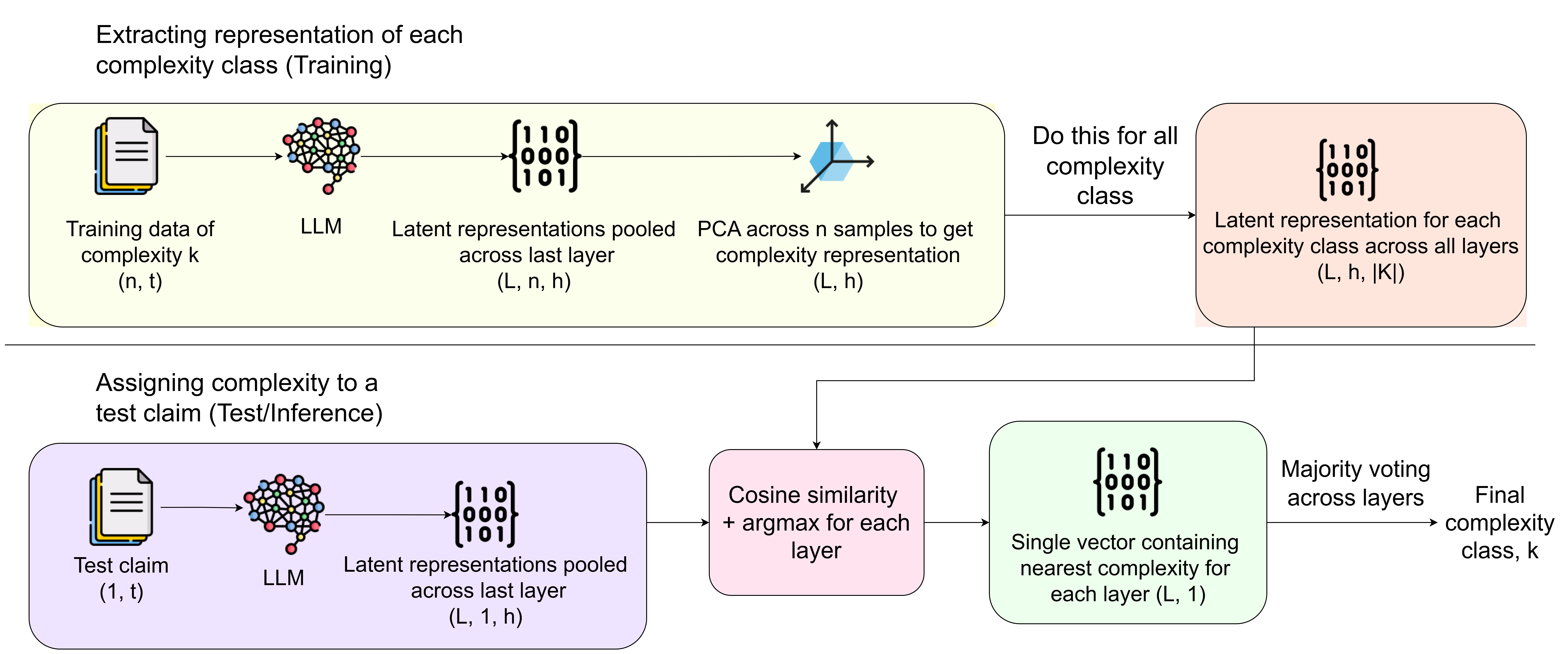
问题定义:论文旨在解决复杂数值声明的事实核查问题。现有方法,特别是大型语言模型,在处理需要多步骤推理和数值计算的声明时,容易出现“推理漂移”现象,即模型在推理过程中偏离正确方向,导致错误结论。现有方法难以有效整合上下文信息,对数值的细微差别理解不足。
核心思路:论文的核心思路是利用测试时缩放(Test-Time Scaling, TTS)技术,让LLM生成多条不同的推理路径,然后训练一个验证器模型(VERIFIERFC)来评估这些路径,并选择最有可能得出正确结论的路径。通过探索多个推理路径,缓解推理漂移问题,提高事实核查的准确性。
技术框架:整体框架包含两个主要部分:1) 使用LLM生成多个推理路径。对于给定的数值声明,LLM被多次调用,每次生成一条不同的推理路径。2) 训练VERIFIERFC模型。该模型接收LLM生成的多个推理路径作为输入,评估每条路径的质量,并选择一条最佳路径。VERIFIERFC模型基于Transformer架构,并针对事实核查任务进行了优化。
关键创新:论文的关键创新在于将测试时缩放技术应用于数值声明的事实核查,并提出了自适应TTS机制。自适应TTS根据声明的复杂性动态调整推理路径的数量,从而在保证性能的同时,提高了计算效率。此外,VERIFIERFC模型的训练方式也针对事实核查任务进行了优化,使其能够更准确地评估推理路径的质量。
关键设计:VERIFIERFC模型使用交叉熵损失函数进行训练,目标是最大化正确推理路径的概率。自适应TTS机制通过一个复杂度预测器来估计声明的复杂性,并根据复杂度动态调整推理路径的数量。复杂度预测器可以是一个简单的分类器,也可以是一个更复杂的模型。论文中具体使用的LLM和VERIFIERFC模型的参数设置在实验部分有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,VERIFIERFC模型在数值声明验证任务上取得了显著的性能提升。自适应TTS方法在计算效率上比标准TTS提高了1.8倍,同时比单次声明验证方法提高了18.8%的性能。这些结果验证了TTS和VERIFIERFC模型在缓解推理漂移问题和提高事实核查准确性方面的有效性。
🎯 应用场景
该研究成果可应用于新闻媒体的事实核查、金融领域的风险评估、科学研究的验证等领域。通过提高数值声明验证的准确性,有助于减少虚假信息的传播,提升决策的可靠性,并促进更客观、准确的信息生态系统的建立。未来可进一步探索如何将该方法应用于更广泛的知识领域。
📄 摘要(原文)
Fact-checking real-world claims, particularly numerical claims, is inherently complex that require multistep reasoning and numerical reasoning for verifying diverse aspects of the claim. Although large language models (LLMs) including reasoning models have made tremendous advances, they still fall short on fact-checking real-world claims that require a combination of compositional and numerical reasoning. They are unable to understand nuance of numerical aspects, and are also susceptible to the reasoning drift issue, where the model is unable to contextualize diverse information resulting in misinterpretation and backtracking of reasoning process. In this work, we systematically explore scaling test-time compute (TTS) for LLMs on the task of fact-checking complex numerical claims, which entails eliciting multiple reasoning paths from an LLM. We train a verifier model (VERIFIERFC) to navigate this space of possible reasoning paths and select one that could lead to the correct verdict. We observe that TTS helps mitigate the reasoning drift issue, leading to significant performance gains for fact-checking numerical claims. To improve compute efficiency in TTS, we introduce an adaptive mechanism that performs TTS selectively based on the perceived complexity of the claim. This approach achieves 1.8x higher efficiency than standard TTS, while delivering a notable 18.8% performance improvement over single-shot claim verification methods. Our code and data can be found at https://github.com/VenkteshV/VerifierFC