Why Chain of Thought Fails in Clinical Text Understanding
作者: Jiageng Wu, Kevin Xie, Bowen Gu, Nils Krüger, Kueiyu Joshua Lin, Jie Yang
分类: cs.CL, cs.AI
发布日期: 2025-09-26 (更新: 2025-12-08)
💡 一句话要点
大规模实验揭示思维链(CoT)提示在临床文本理解中失效的现象与原因
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 临床文本理解 思维链(CoT) 大型语言模型 电子健康记录 医学人工智能
📋 核心要点
- 现有研究表明思维链(CoT)提示在通用领域表现良好,但在临床文本理解中其有效性未被充分验证,尤其是在处理复杂的电子健康记录时。
- 该研究通过大规模实验,系统性地评估了CoT在临床文本任务中的表现,并分析了其失效的原因,旨在为临床LLM推理策略提供经验依据。
- 实验结果表明,大多数模型在CoT设置下性能下降,揭示了CoT在临床环境中的局限性,并强调了透明和可信方法在临床应用中的重要性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地应用于临床医疗领域,而准确性和透明的推理对于安全和可信的部署至关重要。思维链(CoT)提示通过引出逐步推理过程,已在各种任务中展示了性能和可解释性的提升。然而,其在临床环境中的有效性仍未得到充分探索,尤其是在电子健康记录(EHRs)的背景下,EHRs是临床文档的主要来源,通常冗长、分散且嘈杂。本文对CoT在临床文本理解中的应用进行了首次大规模系统研究。我们在87个真实临床文本任务上评估了95个先进的LLM,涵盖9种语言和8种任务类型。与先前在其他领域的研究结果相反,我们观察到86.3%的模型在CoT设置中遭受持续的性能下降。能力更强的模型保持相对稳健,而较弱的模型则遭受大幅下降。为了更好地描述这些影响,我们利用LLM-as-a-judge评估和临床专家评估,对推理长度、医学概念对齐和错误概况进行了细粒度分析。我们的结果揭示了CoT在临床环境中失效的系统性模式,突出了一个关键悖论:CoT增强了可解释性,但可能会损害临床文本任务的可靠性。这项工作为LLM的临床推理策略提供了经验基础,强调了对透明和可信方法的需要。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在临床文本理解任务中使用思维链(CoT)提示时性能下降的问题。现有的CoT方法在通用领域表现良好,但在处理电子健康记录(EHRs)等复杂、冗长且噪声大的临床文本时,其有效性受到挑战。现有方法的痛点在于无法保证在临床领域的可靠性,甚至会降低性能。
核心思路:论文的核心思路是通过大规模实验评估CoT在临床文本理解任务中的表现,并分析其失效的原因。通过细粒度分析推理长度、医学概念对齐和错误概况,揭示CoT在临床环境中失效的系统性模式。这样设计的目的是为了更好地理解CoT在临床领域的局限性,并为开发更可靠的临床LLM推理策略提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 任务选择与数据收集:选择87个真实临床文本任务,涵盖9种语言和8种任务类型。 2. 模型评估:在这些任务上评估95个先进的LLM,包括有CoT和无CoT两种设置。 3. 性能分析:比较不同模型在CoT设置下的性能表现,识别性能下降的模型。 4. 细粒度分析:对推理长度、医学概念对齐和错误概况进行细粒度分析,利用LLM-as-a-judge评估和临床专家评估。 5. 结果分析与总结:分析CoT在临床环境中失效的系统性模式,并总结研究结果。
关键创新:该研究最重要的技术创新点在于首次对CoT在临床文本理解中的应用进行了大规模系统研究。与以往研究主要集中在通用领域不同,该研究关注临床领域的特殊性,揭示了CoT在处理复杂临床文本时的局限性。此外,该研究还通过细粒度分析,深入探讨了CoT失效的原因,为改进临床LLM推理策略提供了新的视角。
关键设计:关键设计包括: 1. 大规模实验设计:选择大量真实临床文本任务和多种LLM进行评估,保证了研究结果的可靠性。 2. 细粒度分析方法:通过LLM-as-a-judge评估和临床专家评估,对推理长度、医学概念对齐和错误概况进行细致分析,深入了解CoT失效的原因。 3. 多语言支持:涵盖9种语言,增加了研究结果的普适性。
🖼️ 关键图片

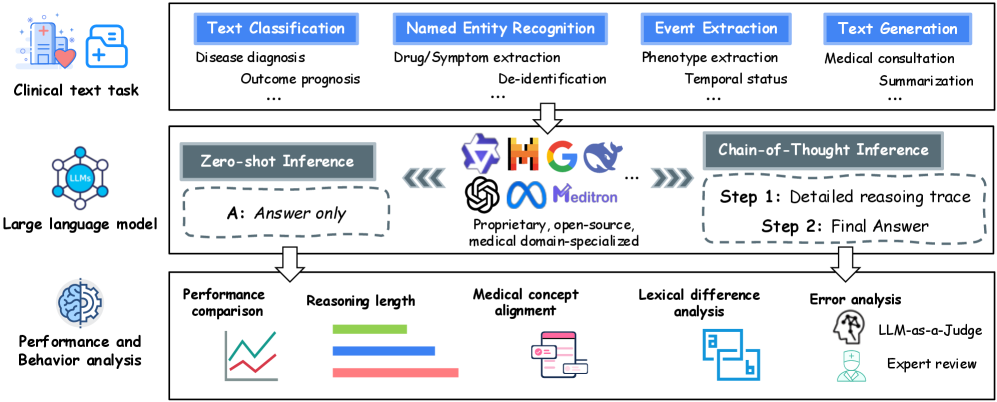

📊 实验亮点
研究发现,在87个真实临床文本任务上评估的95个先进LLM中,86.3%的模型在CoT设置下性能下降。能力较强的模型表现相对稳定,而能力较弱的模型性能显著降低。细粒度分析表明,推理长度、医学概念对齐和错误概况是影响CoT性能的关键因素。这些结果揭示了CoT在临床环境中的局限性,并为改进临床LLM推理策略提供了重要依据。
🎯 应用场景
该研究成果可应用于改进临床决策支持系统,提升电子健康记录的处理效率和准确性。通过理解CoT在临床环境中的局限性,可以开发更可靠、透明的临床LLM推理策略,从而提高医疗服务的质量和安全性。未来的研究可以探索更适合临床文本的推理方法,例如结合领域知识的推理或基于证据的推理。
📄 摘要(原文)
Large language models (LLMs) are increasingly being applied to clinical care, a domain where both accuracy and transparent reasoning are critical for safe and trustworthy deployment. Chain-of-thought (CoT) prompting, which elicits step-by-step reasoning, has demonstrated improvements in performance and interpretability across a wide range of tasks. However, its effectiveness in clinical contexts remains largely unexplored, particularly in the context of electronic health records (EHRs), the primary source of clinical documentation, which are often lengthy, fragmented, and noisy. In this work, we present the first large-scale systematic study of CoT for clinical text understanding. We assess 95 advanced LLMs on 87 real-world clinical text tasks, covering 9 languages and 8 task types. Contrary to prior findings in other domains, we observe that 86.3\% of models suffer consistent performance degradation in the CoT setting. More capable models remain relatively robust, while weaker ones suffer substantial declines. To better characterize these effects, we perform fine-grained analyses of reasoning length, medical concept alignment, and error profiles, leveraging both LLM-as-a-judge evaluation and clinical expert evaluation. Our results uncover systematic patterns in when and why CoT fails in clinical contexts, which highlight a critical paradox: CoT enhances interpretability but may undermine reliability in clinical text tasks. This work provides an empirical basis for clinical reasoning strategies of LLMs, highlighting the need for transparent and trustworthy approaches.