AutoSCORE: Enhancing Automated Scoring with Multi-Agent Large Language Models via Structured Component Recognition
作者: Yun Wang, Zhaojun Ding, Xuansheng Wu, Siyue Sun, Ninghao Liu, Xiaoming Zhai
分类: cs.CL, cs.AI
发布日期: 2025-09-26
备注: 9 pages, 2 figures
💡 一句话要点
AutoSCORE:利用结构化组件识别和多Agent LLM增强自动评分
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动评分 大型语言模型 多Agent系统 结构化组件识别 教育评估
📋 核心要点
- 现有基于LLM的自动评分方法存在准确率低、提示敏感、可解释性差以及与评分标准不一致等问题。
- AutoSCORE通过多Agent架构,首先提取并结构化表示评分标准相关的组件,再进行评分,模拟人类评分过程。
- 实验表明,AutoSCORE在多个数据集上显著提升了评分准确率和人机一致性,尤其在复杂评分标准和小型LLM上。
📝 摘要(中文)
自动评分在教育中发挥着关键作用,它减少了对人工评分员的依赖,并为学生作业提供可扩展且即时的评估。虽然大型语言模型(LLMs)在该任务中显示出强大的潜力,但将其用作端到端评分员面临着准确率低、提示敏感、可解释性有限以及评分标准不一致等挑战。这些问题阻碍了基于LLM的自动评分在评估实践中的实施。为了解决这些局限性,我们提出了AutoSCORE,一个多Agent LLM框架,通过与评分标准对齐的结构化组件识别来增强自动评分。AutoSCORE使用两个Agent,首先从学生回答中提取与评分标准相关的组件,并将它们编码成结构化表示(即,评分标准组件提取Agent),然后使用该结构化表示来分配最终分数(即,评分Agent)。这种设计确保了模型推理遵循类似人类的评分过程,从而提高了可解释性和鲁棒性。我们使用专有和开源LLM(GPT-4o、LLaMA-3.1-8B和LLaMA-3.1-70B)在来自ASAP基准测试的四个基准数据集上评估AutoSCORE。在不同的任务和评分标准中,与单Agent基线相比,AutoSCORE始终提高了评分准确率、人机一致性(QWK、相关性)和误差指标(MAE、RMSE),尤其是在复杂的多维度评分标准上,并且在较小的LLM上获得了特别大的相对收益。这些结果表明,结构化组件识别与多Agent设计相结合,为自动评分提供了一种可扩展、可靠且可解释的解决方案。
🔬 方法详解
问题定义:论文旨在解决现有LLM在自动评分任务中存在的准确率低、可解释性差、对提示敏感以及与评分标准不一致等问题。现有方法通常直接使用LLM进行端到端评分,忽略了评分标准中的结构化信息,导致评分结果不稳定且难以解释。
核心思路:论文的核心思路是将自动评分过程分解为两个阶段:首先,提取学生答案中与评分标准相关的组件,并将其结构化表示;然后,基于这些结构化组件进行评分。这种分解模拟了人类评分员的评分过程,提高了评分的可解释性和鲁棒性。
技术框架:AutoSCORE采用多Agent架构,包含两个主要模块:评分标准组件提取Agent和评分Agent。评分标准组件提取Agent负责从学生答案中提取与评分标准相关的关键信息,并将其编码为结构化表示。评分Agent则利用这些结构化信息,结合评分标准,给出最终评分。整个流程模拟了人类专家阅读答案、识别关键点、对照评分标准进行评分的过程。
关键创新:AutoSCORE的关键创新在于引入了结构化组件识别的概念,并将自动评分过程分解为两个独立的Agent。这种设计使得模型能够更好地理解评分标准,并关注学生答案中的关键信息,从而提高了评分的准确性和可解释性。与传统的端到端方法相比,AutoSCORE能够更好地利用评分标准中的结构化信息,并减少了对提示的依赖。
关键设计:论文中没有明确提及关键的参数设置、损失函数或网络结构等技术细节。但是,结构化组件的表示方式以及两个Agent之间的交互方式是关键的设计选择。具体实现可能涉及使用特定的自然语言处理技术来提取和表示组件,并设计合适的机制来确保两个Agent之间的信息传递和协同工作。这些具体细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
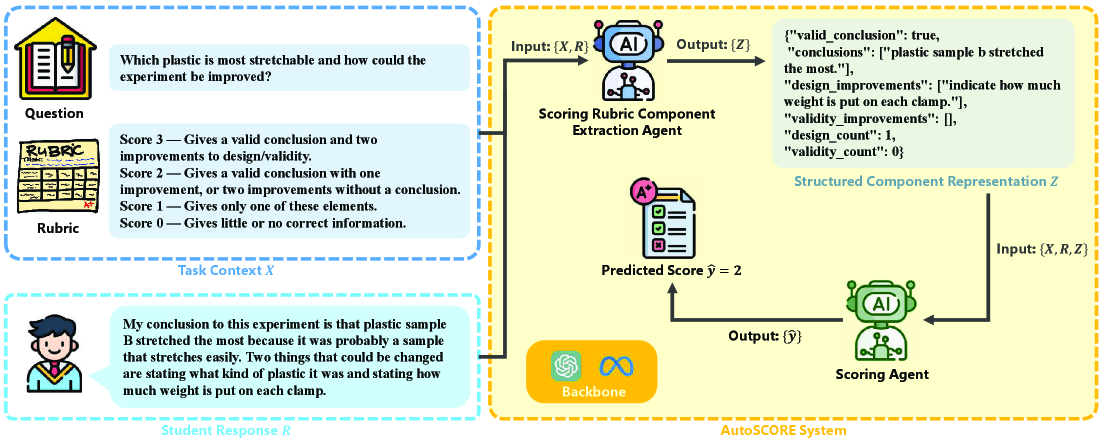

📊 实验亮点
AutoSCORE在ASAP基准测试的四个数据集上进行了评估,结果表明,与单Agent基线相比,AutoSCORE在评分准确率、人机一致性(QWK、相关性)和误差指标(MAE、RMSE)方面均有显著提升。尤其是在复杂的多维度评分标准上,以及在较小的LLM(如LLaMA-3.1-8B)上,AutoSCORE获得了更大的相对收益。例如,在某些任务上,AutoSCORE的QWK指标提升了超过10%。
🎯 应用场景
AutoSCORE具有广泛的应用前景,可用于大规模在线教育、标准化考试自动评分、论文评审等领域。该方法能够提高评分效率,降低人工成本,并提供更客观、一致的评分结果。未来,AutoSCORE可以进一步扩展到其他需要自动化评估的领域,例如代码评审、产品质量评估等。
📄 摘要(原文)
Automated scoring plays a crucial role in education by reducing the reliance on human raters, offering scalable and immediate evaluation of student work. While large language models (LLMs) have shown strong potential in this task, their use as end-to-end raters faces challenges such as low accuracy, prompt sensitivity, limited interpretability, and rubric misalignment. These issues hinder the implementation of LLM-based automated scoring in assessment practice. To address the limitations, we propose AutoSCORE, a multi-agent LLM framework enhancing automated scoring via rubric-aligned Structured COmponent REcognition. With two agents, AutoSCORE first extracts rubric-relevant components from student responses and encodes them into a structured representation (i.e., Scoring Rubric Component Extraction Agent), which is then used to assign final scores (i.e., Scoring Agent). This design ensures that model reasoning follows a human-like grading process, enhancing interpretability and robustness. We evaluate AutoSCORE on four benchmark datasets from the ASAP benchmark, using both proprietary and open-source LLMs (GPT-4o, LLaMA-3.1-8B, and LLaMA-3.1-70B). Across diverse tasks and rubrics, AutoSCORE consistently improves scoring accuracy, human-machine agreement (QWK, correlations), and error metrics (MAE, RMSE) compared to single-agent baselines, with particularly strong benefits on complex, multi-dimensional rubrics, and especially large relative gains on smaller LLMs. These results demonstrate that structured component recognition combined with multi-agent design offers a scalable, reliable, and interpretable solution for automated scoring.