AgentPack: A Dataset of Code Changes, Co-Authored by Agents and Humans
作者: Yangtian Zi, Zixuan Wu, Aleksander Boruch-Gruszecki, Jonathan Bell, Arjun Guha
分类: cs.SE, cs.CL
发布日期: 2025-09-26
💡 一句话要点
AgentPack:一个由智能体与人类共同编写的代码变更数据集,用于提升代码编辑模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码编辑 大型语言模型 数据集 软件工程智能体 代码生成
📋 核心要点
- 现有代码编辑模型依赖于从提交记录和拉取请求中挖掘数据,但这些数据通常包含噪声,例如提交信息简短、提交内容混杂等。
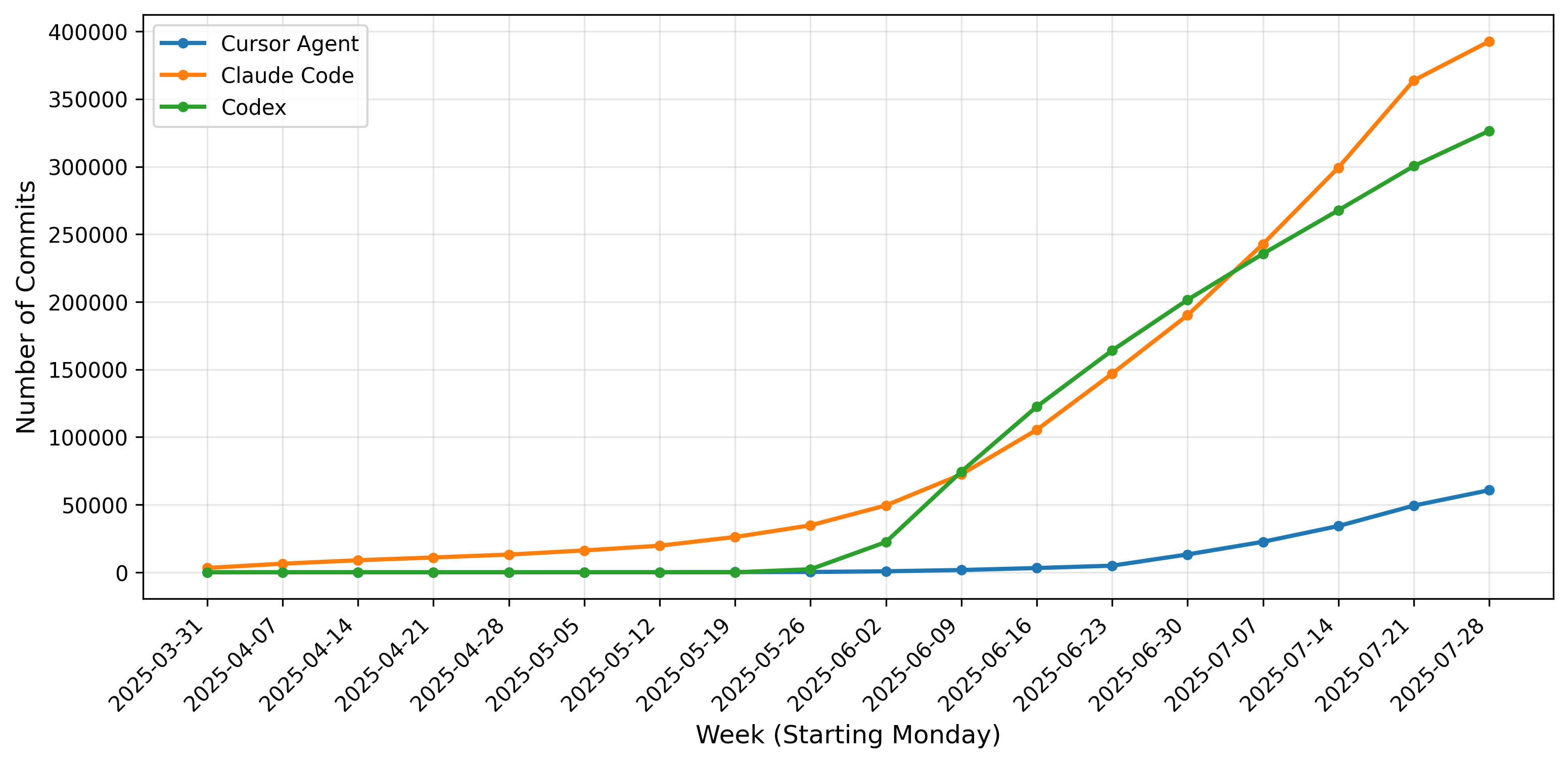
- AgentPack数据集包含由人类和智能体共同编写的代码变更,这些变更范围更窄、目标更明确,且提交信息由LLM生成,详细阐述了意图和原理。
- 实验表明,在AgentPack上微调的模型性能优于在传统人类提交数据集上训练的模型,验证了该数据集的有效性。
📝 摘要(中文)
本文提出了AgentPack,一个包含130万个代码编辑的数据集,这些编辑由Claude Code、OpenAI Codex和Cursor Agent等智能体与人类共同完成,来源于2025年8月中旬之前的公共GitHub项目。论文描述了数据集的识别和整理流程,量化了这些智能体的采用趋势,并分析了编辑的结构属性。实验结果表明,在AgentPack上微调的模型优于在先前仅包含人类提交的数据集上训练的模型,突显了利用软件工程智能体的公共数据来训练未来代码编辑模型的潜力。
🔬 方法详解
问题定义:现有代码编辑模型的训练依赖于挖掘commit和pull request,但这些数据存在噪声问题,例如commit message过于简短,人工编写的commit混杂了多个不相关的修改,以及大量commit来自简单的、基于规则的机器人。这些问题导致模型难以准确学习人类的编辑意图。
核心思路:论文的核心思路是利用由人类和软件工程智能体共同编写的代码变更数据来训练代码编辑模型。这些代码变更通常范围更窄、目标更明确,并且commit message由LLM生成,能够更清晰地表达意图和原理。此外,这些变更经过人类维护者的隐式过滤,质量更高。
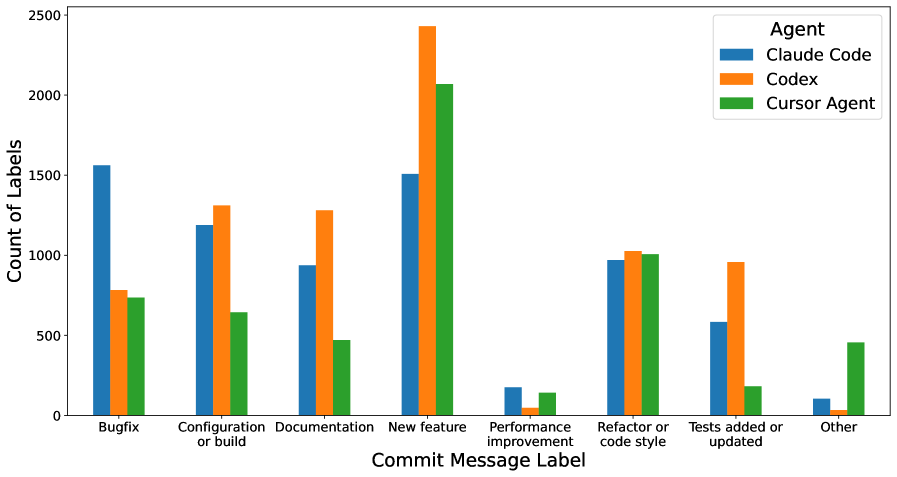
技术框架:AgentPack的构建流程主要包括以下几个步骤:1) 从公共GitHub项目中识别由Claude Code、OpenAI Codex和Cursor Agent等智能体参与的代码变更;2) 对识别出的代码变更进行清洗和整理,去除低质量的数据;3) 对数据集进行统计分析,包括智能体的采用趋势和编辑的结构属性;4) 使用AgentPack训练代码编辑模型,并与在传统数据集上训练的模型进行比较。
关键创新:AgentPack的关键创新在于其数据来源。与以往依赖于人工编写的commit不同,AgentPack包含由人类和软件工程智能体共同编写的代码变更。这种数据具有更高的质量和更清晰的意图表达,能够更好地用于训练代码编辑模型。
关键设计:论文没有详细描述具体的模型结构、损失函数或参数设置。重点在于数据集的构建和验证。实验部分使用了在AgentPack上微调的模型,并与在传统人类提交数据集上训练的模型进行了比较,以验证AgentPack的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在AgentPack数据集上微调的代码编辑模型,其性能优于在传统的人工提交数据集上训练的模型。这表明AgentPack数据集能够提供更有效的信息,从而提升代码编辑模型的性能。具体的性能提升幅度未知,论文中未给出明确的数值。
🎯 应用场景
AgentPack数据集可用于训练和评估各种代码编辑模型,例如代码补全、代码修复和代码生成模型。该数据集能够提升这些模型在实际软件开发场景中的性能,提高开发效率,并降低代码错误率。此外,该数据集还可以用于研究人类与智能体在软件开发中的协作模式。
📄 摘要(原文)
Fine-tuning large language models for code editing has typically relied on mining commits and pull requests. The working hypothesis has been that commit messages describe human intent in natural language, and patches to code describe the changes that implement that intent. However, much of the previously collected data is noisy: commit messages are terse, human-written commits commingle several unrelated edits, and many commits come from simple, rule-based bots. The recent adoption of software engineering agents changes this landscape. Code changes co-authored by humans and agents tend to be more narrowly scoped and focused on clearer goals. Their commit messages, generated by LLMs, articulate intent and rationale in much greater detail. Moreover, when these changes land in public repositories, they are implicitly filtered by humans: maintainers discard low-quality commits to their projects. We present AgentPack, a corpus of 1.3M code edits co-authored by Claude Code, OpenAI Codex, and Cursor Agent across public GitHub projects up to mid-August 2025. We describe the identification and curation pipeline, quantify adoption trends of these agents, and analyze the structural properties of the edits. Finally, we show that models fine-tuned on AgentPack can outperform models trained on prior human-only commit corpora, highlighting the potential of using public data from software engineering agents to train future code-editing models.