LUMINA: Detecting Hallucinations in RAG System with Context-Knowledge Signals
作者: Samuel Yeh, Sharon Li, Tanwi Mallick
分类: cs.CL
发布日期: 2025-09-26 (更新: 2026-02-03)
备注: ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
LUMINA:利用上下文-知识信号检测RAG系统中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 幻觉检测 上下文利用率 知识利用率 大型语言模型
📋 核心要点
- 现有RAG系统仍存在幻觉问题,其根源在于模型对外部上下文和内部知识的利用不平衡,现有检测方法依赖大量超参数调整。
- LUMINA通过量化外部上下文利用率(分布距离)和内部知识利用率(token在transformer层中的演变)来检测幻觉。
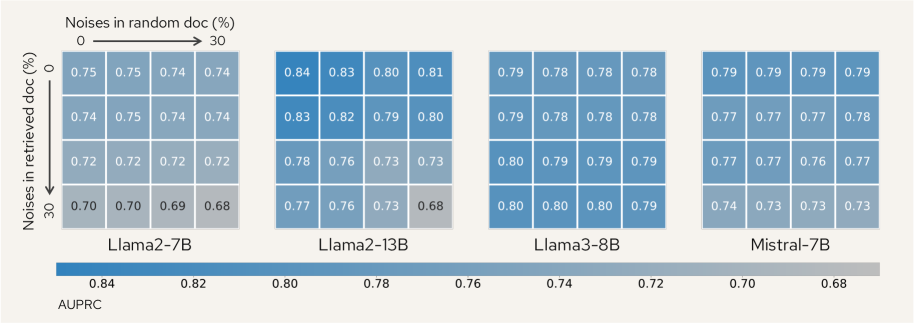
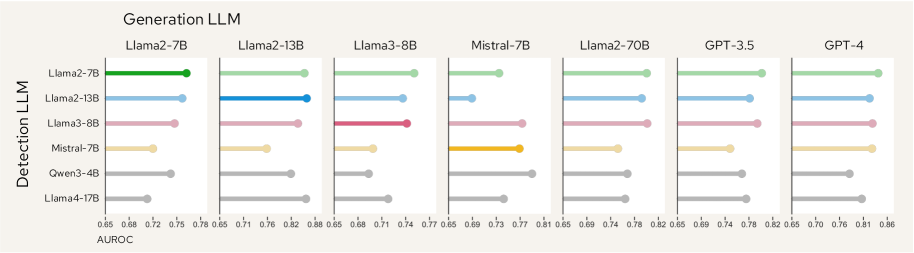
- 实验表明,LUMINA在多个基准测试中优于现有方法,且在检索质量和模型匹配的宽松假设下依然表现稳健。
📝 摘要(中文)
检索增强生成(RAG)旨在通过将响应建立在检索到的文档上来缓解大型语言模型(LLM)中的幻觉问题。然而,即使提供了正确且充分的上下文,基于RAG的LLM仍然会产生幻觉。越来越多的研究表明,这源于模型对外部上下文和内部知识的使用不平衡。一些方法试图量化这些信号以进行幻觉检测,但现有方法需要大量的超参数调整,限制了其泛化能力。我们提出了LUMINA,这是一个新颖的框架,通过上下文-知识信号检测RAG系统中的幻觉:外部上下文利用率通过分布距离量化,而内部知识利用率通过跟踪预测的token在transformer层中的演变来衡量。我们进一步引入了一个框架来统计验证这些测量结果。在常见的RAG幻觉基准和四个开源LLM上的实验表明,LUMINA实现了始终如一的高AUROC和AUPRC分数,在HalluRAG上优于先前的基于利用率的方法高达+13% AUROC。此外,LUMINA在检索质量和模型匹配的宽松假设下仍然保持稳健性,兼具有效性和实用性。
🔬 方法详解
问题定义:论文旨在解决RAG系统中LLM产生的幻觉问题,即使在提供正确和充分的上下文后,模型仍然可能生成不真实或与上下文不一致的内容。现有基于上下文和知识利用率的幻觉检测方法通常需要大量的超参数调整,导致泛化能力受限。
核心思路:LUMINA的核心思路是通过量化模型对外部上下文和内部知识的利用程度来判断是否存在幻觉。如果模型过度依赖内部知识而忽略外部上下文,或者反之,则可能存在幻觉。通过分析模型在生成过程中的行为,可以推断其对不同信息来源的依赖程度。
技术框架:LUMINA框架主要包含两个核心模块:上下文利用率评估和知识利用率评估。上下文利用率通过计算生成文本的token分布与检索到的文档的token分布之间的距离来衡量,距离越大表示对上下文的利用越少。知识利用率通过跟踪预测的token在transformer层中的演变来衡量,如果token在早期层就已经确定,则表明模型更多地依赖于内部知识。此外,论文还提出了一个统计验证框架,用于验证这些测量结果的显著性。
关键创新:LUMINA的关键创新在于提出了一种无需大量超参数调整即可有效量化上下文和知识利用率的方法。通过分布距离和token演变分析,LUMINA能够更准确地检测RAG系统中的幻觉。此外,统计验证框架增强了结果的可靠性。与现有方法相比,LUMINA在泛化能力和鲁棒性方面具有优势。
关键设计:上下文利用率的计算使用了KL散度或JS散度等分布距离度量。知识利用率的计算涉及跟踪每个token在不同transformer层中的预测概率变化,并使用熵或方差等指标来量化其稳定性。统计验证框架使用bootstrap等方法来评估测量结果的显著性,并设定阈值来判断是否存在幻觉。
🖼️ 关键图片

📊 实验亮点
LUMINA在HalluRAG等常见RAG幻觉基准测试中取得了显著的性能提升,AUROC指标最高提升了13%。实验结果表明,LUMINA优于现有的基于利用率的方法,并且在检索质量和模型匹配的宽松假设下依然保持稳健性。这些结果验证了LUMINA的有效性和实用性。
🎯 应用场景
LUMINA可应用于各种基于RAG的LLM应用中,例如问答系统、对话机器人和内容生成工具。通过检测和减少幻觉,LUMINA可以提高这些应用的可靠性和可信度,从而增强用户体验。该研究还有助于推动对LLM内部工作机制的理解,并为开发更安全、更可控的LLM提供指导。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) aims to mitigate hallucinations in large language models (LLMs) by grounding responses in retrieved documents. Yet, RAG-based LLMs still hallucinate even when provided with correct and sufficient context. A growing line of work suggests that this stems from an imbalance between how models use external context and their internal knowledge, and several approaches have attempted to quantify these signals for hallucination detection. However, existing methods require extensive hyperparameter tuning, limiting their generalizability. We propose LUMINA, a novel framework that detects hallucinations in RAG systems through context--knowledge signals: external context utilization is quantified via distributional distance, while internal knowledge utilization is measured by tracking how predicted tokens evolve across transformer layers. We further introduce a framework for statistically validating these measurements. Experiments on common RAG hallucination benchmarks and four open-source LLMs show that LUMINA achieves consistently high AUROC and AUPRC scores, outperforming prior utilization-based methods by up to +13% AUROC on HalluRAG. Moreover, LUMINA remains robust under relaxed assumptions about retrieval quality and model matching, offering both effectiveness and practicality. LUMINA: https://github.com/deeplearning-wisc/LUMINA