ResT: Reshaping Token-Level Policy Gradients for Tool-Use Large Language Models
作者: Zihan Lin, Xiaohan Wang, Jie Cao, Jiajun Chai, Guojun Yin, Wei Lin, Ran He
分类: cs.CL
发布日期: 2025-09-26
💡 一句话要点
ResT:重塑Token级策略梯度,提升LLM工具使用能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 强化学习 策略梯度 策略熵 Token重加权 智能体
📋 核心要点
- 现有工具使用LLM的强化学习训练依赖稀疏奖励,忽略了任务特性,导致策略梯度方差大,训练效率低。
- ResT通过熵感知的token重加权来重塑策略梯度,逐步提升推理token的权重,从而稳定训练过程。
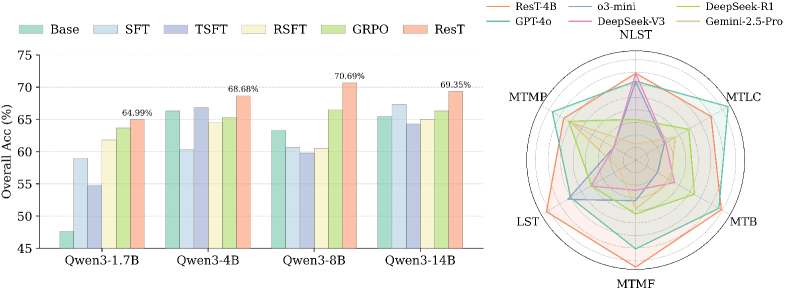
- ResT在BFCL和API-Bank上取得了SOTA结果,并在4B LLM微调后超越了GPT-4o,证明了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)通过调用外部工具,超越了被动生成,成为了目标导向的智能体。强化学习(RL)为优化这些新兴的工具使用策略提供了一个原则性框架,但目前的方法仅依赖于稀疏的结果奖励,并且缺乏对工具使用任务特殊性的考虑,从而增加了策略梯度方差,导致训练效率低下。为了更好地理解和解决这些挑战,我们首先建立了策略熵与工具使用任务训练稳定性之间的理论联系,揭示了结构化的低熵token是奖励的主要决定因素。受此启发,我们提出了用于工具使用任务的重塑Token级策略梯度(ResT)。ResT通过熵感知的token重加权来重塑策略梯度,随着训练的进行,逐步提高推理token的权重。这种熵感知方案能够实现从结构正确性到语义推理的平滑过渡,并稳定多轮工具使用任务中的收敛。在BFCL和API-Bank上的评估表明,ResT取得了最先进的结果,优于现有方法高达8.76%。当在4B基础LLM上进行微调时,ResT在单轮任务上超过GPT-4o 4.11%,在多轮基础任务上超过GPT-4o 1.50%。
🔬 方法详解
问题定义:现有方法在训练能够使用工具的LLM时,主要依赖稀疏奖励信号,这使得策略梯度估计的方差很大,训练过程不稳定且效率低下。此外,现有方法没有充分利用工具使用任务的特性,例如,工具调用通常需要结构化的输入和输出,而这些结构信息在训练中没有得到有效利用。
核心思路:ResT的核心思路是利用策略熵来指导策略梯度的更新。论文发现,在工具使用任务中,低熵的token(例如,结构化的API调用)对最终奖励的贡献更大。因此,ResT通过对不同token的梯度进行重加权,来优先更新那些对奖励贡献更大的token,从而降低策略梯度方差,提高训练效率。
技术框架:ResT的整体框架是在标准的强化学习流程中引入了一个token级别的梯度重加权模块。具体来说,模型首先生成一系列token,然后根据这些token的策略熵计算一个权重向量。这个权重向量用于调整每个token的策略梯度,使得低熵token的梯度得到更大的权重。最后,使用调整后的梯度来更新模型参数。
关键创新:ResT的关键创新在于提出了熵感知的token重加权策略。与传统的强化学习方法不同,ResT不仅仅关注最终的奖励,还关注每个token对奖励的贡献。通过对低熵token的梯度进行放大,ResT能够更有效地利用结构化信息,从而提高训练效率和模型性能。
关键设计:ResT的关键设计包括:1) 使用策略熵作为token重要性的度量;2) 设计了一个平滑的重加权函数,使得权重随着训练的进行逐渐增大;3) 将重加权后的梯度与原始梯度进行加权平均,以保持训练的稳定性。具体的损失函数包括标准的策略梯度损失,以及一个用于鼓励低熵token的正则化项。
🖼️ 关键图片


📊 实验亮点
ResT在BFCL和API-Bank数据集上取得了显著的性能提升,超越了现有的SOTA方法高达8.76%。更重要的是,在4B参数的LLM上进行微调后,ResT在单轮任务上超越了GPT-4o 4.11%,在多轮任务上超越了GPT-4o 1.50%,证明了其在实际应用中的潜力。
🎯 应用场景
ResT可应用于各种需要LLM与外部工具交互的场景,例如智能助手、自动化流程、代码生成等。通过提高LLM工具使用的效率和准确性,ResT可以显著提升这些应用的性能和用户体验,并推动LLM在实际问题中的应用。
📄 摘要(原文)
Large language models (LLMs) transcend passive generation and act as goal-directed agents by invoking external tools. Reinforcement learning (RL) offers a principled framework for optimizing these emergent tool-use policies, yet the prevailing paradigm relies exclusively on sparse outcome rewards and lacks consideration of the particularity of tool-use tasks, inflating policy-gradient variance and resulting in inefficient training. To better understand and address these challenges, we first establish a theoretical link between policy entropy and training stability of tool-use tasks, which reveals that structured, low-entropy tokens are primary determinants of rewards. Motivated by this insight, we propose \textbf{Res}haped \textbf{T}oken-level policy gradients (\textbf{ResT}) for tool-use tasks. ResT reshapes the policy gradient through entropy-informed token reweighting, progressively upweighting reasoning tokens as training proceeds. This entropy-aware scheme enables a smooth shift from structural correctness to semantic reasoning and stabilizes convergence in multi-turn tool-use tasks. Evaluation on BFCL and API-Bank shows that ResT achieves state-of-the-art results, outperforming prior methods by up to $8.76\%$. When fine-tuned on a 4B base LLM, ResT further surpasses GPT-4o by $4.11\%$ on single-turn tasks and $1.50\%$ on multi-turn base tasks.