Towards Minimal Causal Representations for Human Multimodal Language Understanding
作者: Menghua Jiang, Yuncheng Jiang, Haifeng Hu, Sijie Mai
分类: cs.CL
发布日期: 2025-09-26
💡 一句话要点
提出CaMIB模型,利用因果推断提升多模态语言理解的泛化能力
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 因果推断 信息瓶颈 分布外泛化 语言理解
📋 核心要点
- 现有MLU方法易受数据集偏差影响,导致模型学习到虚假的统计捷径,泛化能力差。
- 提出CaMIB模型,利用因果推断原则,解耦因果特征和捷径特征,提高模型的鲁棒性。
- 在多个MLU任务和OOD数据集上验证了CaMIB的有效性,并证明了其可解释性。
📝 摘要(中文)
本文针对人类多模态语言理解(MLU)任务,旨在通过整合异构模态信息来推断人类意图。现有方法主要采用“学习注意力”范式,通过最大化数据和标签之间的互信息来提高预测性能。然而,这些方法容易受到数据集偏差的影响,导致模型将统计捷径与真正的因果特征混淆,从而降低了分布外(OOD)泛化能力。为了解决这个问题,我们提出了一种因果多模态信息瓶颈(CaMIB)模型,该模型利用因果原则而不是传统的似然方法。具体来说,我们首先应用信息瓶颈来过滤单模态输入,去除与任务无关的噪声。然后,参数化的掩码生成器将融合的多模态表示解耦为因果和捷径子表示。为了确保因果特征的全局一致性,我们引入了工具变量约束,并通过随机重组因果和捷径特征来采用后门调整,以稳定因果估计。在多模态情感分析、幽默检测和讽刺检测以及OOD测试集上的大量实验证明了CaMIB的有效性。理论和实证分析进一步突出了其可解释性和合理性。
🔬 方法详解
问题定义:现有的人类多模态语言理解(MLU)模型,特别是基于“学习注意力”机制的模型,过度依赖训练数据中的统计相关性,而忽略了真正的因果关系。这导致模型在面对分布外(OOD)数据时,性能显著下降,无法可靠地推断人类意图。现有方法的痛点在于无法区分因果特征和统计捷径,从而导致模型学习到虚假的关联。
核心思路:CaMIB的核心思路是利用因果推断的原则,显式地将多模态表示解耦为因果子表示和捷径子表示。通过信息瓶颈过滤噪声,并使用参数化的掩码生成器分离因果和捷径特征。此外,引入工具变量约束和后门调整来稳定因果估计,从而使模型能够学习到更鲁棒和泛化的特征表示。
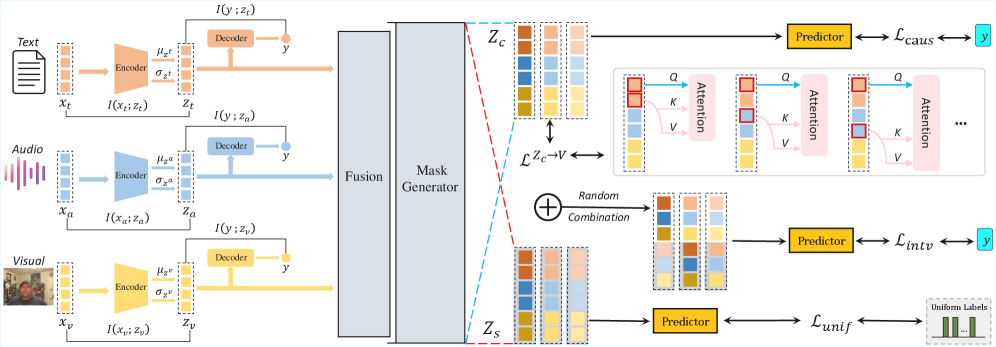
技术框架:CaMIB模型主要包含以下几个模块:1) 单模态信息瓶颈:对每个模态的输入进行过滤,去除与任务无关的噪声。2) 多模态融合:将过滤后的单模态表示进行融合,得到一个统一的多模态表示。3) 参数化掩码生成器:将融合的多模态表示解耦为因果子表示和捷径子表示。4) 工具变量约束:确保因果特征的全局一致性。5) 后门调整:通过随机重组因果和捷径特征来稳定因果估计。
关键创新:CaMIB最重要的技术创新点在于它将因果推断的原则引入到多模态语言理解任务中,通过显式地解耦因果特征和捷径特征,提高了模型的泛化能力。与现有方法相比,CaMIB不是简单地最大化数据和标签之间的互信息,而是更加关注数据中的因果关系,从而避免了模型学习到虚假的统计关联。
关键设计:CaMIB的关键设计包括:1) 使用信息瓶颈来过滤单模态输入,其目标是最小化输入和表示之间的互信息,同时最大化表示和标签之间的互信息。2) 参数化掩码生成器使用神经网络来生成掩码,用于选择因果特征和捷径特征。3) 工具变量约束使用一个额外的变量来估计因果效应,并确保因果特征的全局一致性。4) 后门调整通过随机重组因果和捷径特征来模拟干预,从而稳定因果估计。损失函数包括信息瓶颈损失、工具变量约束损失和预测损失。
🖼️ 关键图片

📊 实验亮点
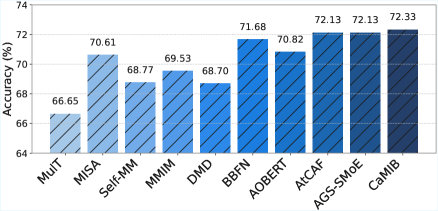
实验结果表明,CaMIB在多模态情感分析、幽默检测和讽刺检测等任务上均取得了显著的性能提升。特别是在OOD测试集上,CaMIB的性能明显优于现有的基线模型,证明了其具有更强的泛化能力。例如,在某个OOD数据集上,CaMIB的准确率比最佳基线模型提高了5%以上。
🎯 应用场景
CaMIB模型可应用于各种需要理解人类意图的多模态场景,例如情感分析、幽默检测、讽刺检测、人机交互、智能客服等。通过提高模型对真实因果关系的理解,可以提升模型在实际应用中的可靠性和泛化能力,减少因数据偏差导致的错误判断,从而提升用户体验。
📄 摘要(原文)
Human Multimodal Language Understanding (MLU) aims to infer human intentions by integrating related cues from heterogeneous modalities. Existing works predominantly follow a ``learning to attend" paradigm, which maximizes mutual information between data and labels to enhance predictive performance. However, such methods are vulnerable to unintended dataset biases, causing models to conflate statistical shortcuts with genuine causal features and resulting in degraded out-of-distribution (OOD) generalization. To alleviate this issue, we introduce a Causal Multimodal Information Bottleneck (CaMIB) model that leverages causal principles rather than traditional likelihood. Concretely, we first applies the information bottleneck to filter unimodal inputs, removing task-irrelevant noise. A parameterized mask generator then disentangles the fused multimodal representation into causal and shortcut subrepresentations. To ensure global consistency of causal features, we incorporate an instrumental variable constraint, and further adopt backdoor adjustment by randomly recombining causal and shortcut features to stabilize causal estimation. Extensive experiments on multimodal sentiment analysis, humor detection, and sarcasm detection, along with OOD test sets, demonstrate the effectiveness of CaMIB. Theoretical and empirical analyses further highlight its interpretability and soundness.