Quantifying the Impact of Structured Output Format on Large Language Models through Causal Inference
作者: Han Yuan, Yue Zhao, Li Zhang, Wuqiong Luo, Zheng Ma
分类: cs.CL, cs.LG
发布日期: 2025-09-26 (更新: 2025-12-19)
💡 一句话要点
利用因果推断量化结构化输出格式对大语言模型的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化输出 因果推断 生成质量 推理能力
📋 核心要点
- 现有研究对结构化输出对LLM的影响存在争议,结果不一致,且评估方法存在局限性,如测试场景受限。
- 该论文采用因果推断方法,构建了五种潜在的因果结构,以更严谨地分析结构化输出对LLM生成的影响。
- 实验结果表明,粗略指标可能产生误导,因果推断揭示了结构化输出在多数情况下没有因果影响,且OpenAI-o3对输出格式更具鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)的结构化输出提高了处理生成信息的效率,并越来越多地应用于工业领域。先前的研究调查了结构化输出对LLM生成质量的影响,但往往只呈现单方面的结果。一些研究表明,结构化格式增强了完整性和事实准确性,而另一些研究则认为它限制了LLM的推理能力,并导致标准评估指标的下降。这些评估的潜在局限性包括受限的测试场景、弱控制的比较设置以及对粗略指标的依赖。本文提出了一种使用因果推断的精细分析。基于一个假设的和两个保证的约束,我们推导了五个潜在的因果结构,这些结构描述了结构化输出对LLM生成的影响:(1)无m-偏倚的碰撞器,(2)有m-偏倚的碰撞器,(3)来自指令的单一原因,(4)来自输出格式的单一原因,以及(5)独立性。在七个公共推理任务和一个开发的推理任务中,我们发现粗略指标报告了结构化输出对GPT-4o生成的积极、消极或中性影响。然而,因果推断显示在48个场景中的43个场景中没有因果影响。在剩下的5个场景中,有3个涉及受具体指令影响的多方面因果结构。进一步的实验表明,OpenAI-o3比通用GPT-4o和GPT-4.1更能抵抗输出格式的影响,突出了推理模型未被意识到的优势。
🔬 方法详解
问题定义:现有研究对结构化输出格式对大型语言模型(LLM)生成质量的影响存在争议,一些研究认为结构化输出可以提高完整性和准确性,而另一些研究则认为会限制推理能力。现有的评估方法通常依赖于粗略的指标,并且缺乏严格的控制变量,导致结论不一致,无法准确量化结构化输出的真实影响。
核心思路:该论文的核心思路是利用因果推断来更严谨地分析结构化输出对LLM生成的影响。通过构建不同的因果结构,可以区分结构化输出本身的影响,以及其他潜在混淆因素(如指令)的影响,从而更准确地评估结构化输出的价值。
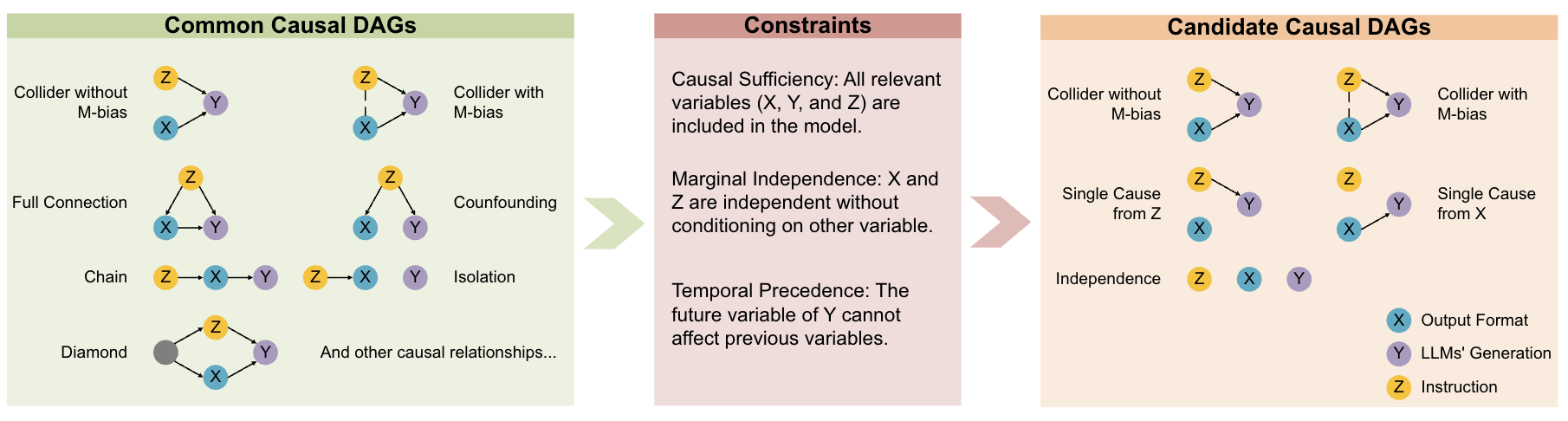
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 因果结构建模:基于一个假设和两个保证的约束,推导了五种潜在的因果结构,这些结构描述了结构化输出对LLM生成的影响,包括碰撞器、单一原因和独立性等。 2. 因果推断分析:使用因果推断方法,例如do-calculus,来估计结构化输出对LLM生成质量的因果效应。 3. 实验验证:在多个推理任务上进行实验,比较不同输出格式下LLM的生成质量,并使用因果推断的结果来解释观察到的差异。
关键创新:该论文最重要的技术创新点在于将因果推断引入到LLM输出格式影响的分析中。与传统的统计分析方法相比,因果推断可以更有效地控制混淆变量,从而更准确地估计结构化输出的因果效应。此外,该论文还提出了五种潜在的因果结构,为理解结构化输出的影响提供了新的视角。
关键设计:论文的关键设计包括: 1. 约束条件:论文基于一个假设(instruction是output format的原因)和两个保证的约束(instruction和output format不是common cause,output format不是instruction的原因)来推导因果结构。 2. 推理任务选择:选择了七个公共推理任务和一个开发的推理任务,以覆盖不同的推理场景。 3. LLM选择:主要使用了GPT-4o,并与GPT-4.1和OpenAI-o3进行了对比。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用粗略指标评估结构化输出的影响可能产生误导。因果推断分析显示,在大多数情况下(43/48),结构化输出对LLM的生成质量没有显著的因果影响。此外,OpenAI-o3比GPT-4o和GPT-4.1更能抵抗输出格式的影响,表明其具有更强的推理能力。
🎯 应用场景
该研究成果可应用于指导LLM应用开发,帮助开发者选择合适的输出格式,以优化LLM的生成质量和效率。此外,该研究提出的因果推断方法也可用于分析其他因素对LLM的影响,例如prompt工程、训练数据等,从而更全面地理解LLM的行为。
📄 摘要(原文)
Structured output from large language models (LLMs) has enhanced efficiency in processing generated information and is increasingly adopted in industrial applications. Prior studies have investigated the impact of structured output on LLMs' generation quality, often presenting one-way findings. Some suggest that structured format enhances completeness and factual accuracy, while others argue that it restricts the reasoning capacity of LLMs and leads to reductions in standard evaluation metrics. Potential limitations of these assessments include restricted testing scenarios, weakly controlled comparative settings, and reliance on coarse metrics. In this work, we present a refined analysis using causal inference. Based on one assumed and two guaranteed constraints, we derive five potential causal structures characterizing the influence of structured output on LLMs' generation: (1) collider without m-bias, (2) collider with m-bias, (3) single cause from instruction, (4) single cause from output format, and (5) independence. Across seven public and one developed reasoning tasks, we find that coarse metrics report positive, negative, or neutral effects of structured output on GPT-4o's generation. However, causal inference reveals no causal impact in 43 out of 48 scenarios. In the remaining 5, 3 involve multifaceted causal structures influenced by concrete instructions. Further experiments show that OpenAI-o3 are more resilient to output formats than general-purpose GPT-4o and GPT-4.1, highlighting an unaware advantage of reasoning models.