Automated Knowledge Graph Construction using Large Language Models and Sentence Complexity Modelling
作者: Sydney Anuyah, Mehedi Mahmud Kaushik, Krishna Dwarampudi, Rakesh Shiradkar, Arjan Durresi, Sunandan Chakraborty
分类: cs.CL
发布日期: 2025-09-22
DOI: 10.18653/v1/2025.emnlp-main.783
🔗 代码/项目: GITHUB
💡 一句话要点
提出CoDe-KG以实现自动化知识图谱构建
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 共指解析 句法分解 关系提取 自然语言处理 机器学习 数据集
📋 核心要点
- 现有的知识图谱构建方法在处理复杂句子和共指解析时存在准确性不足的问题。
- 论文提出了一种结合共指解析与句法分解的自动化知识图谱构建管道CoDe-KG,旨在提高句子级知识提取的准确性。
- 实验结果表明,CoDe-KG在关系提取任务上显著提升了性能,宏F1和微F1分别提高了8个百分点和超过75%。
📝 摘要(中文)
我们介绍了CoDe-KG,一个开源的端到端管道,通过结合强大的共指解析与句法句子分解来提取句子级知识图谱。利用我们的模型,我们贡献了超过150,000个知识三元组的数据集,并提供了7248行的句子复杂度训练语料、190行的共指解析金标注、900行的句子转换策略金标注以及398个金标注的三元组。我们系统地选择了五个复杂度类别的最佳提示-模型对,显示混合的思维链和少量示例提示在句子简化上达到了99.8%的准确率。在关系提取方面,我们的管道在REBEL上达到了65.8%的宏F1,相较于之前的最先进技术提升了8个百分点,并在WebNLG2上达到了75.7%的微F1,同时在Wiki-NRE和CaRB上表现相当或更优。消融研究表明,整合共指解析和分解在稀有关系上的召回率提高了20%以上。代码和数据集可在https://github.com/KaushikMahmud/CoDe-KG_EMNLP_2025获取。
🔬 方法详解
问题定义:本论文旨在解决现有知识图谱构建方法在句子复杂性和共指解析方面的不足,尤其是在处理复杂句子时的准确性问题。
核心思路:论文提出的CoDe-KG通过结合共指解析和句法句子分解,构建一个端到端的知识图谱提取管道,旨在提高句子级知识提取的准确性和效率。
技术框架:CoDe-KG的整体架构包括数据预处理、共指解析、句法分解和知识三元组提取四个主要模块。首先对输入文本进行预处理,然后进行共指解析,接着进行句法分解,最后提取知识三元组。
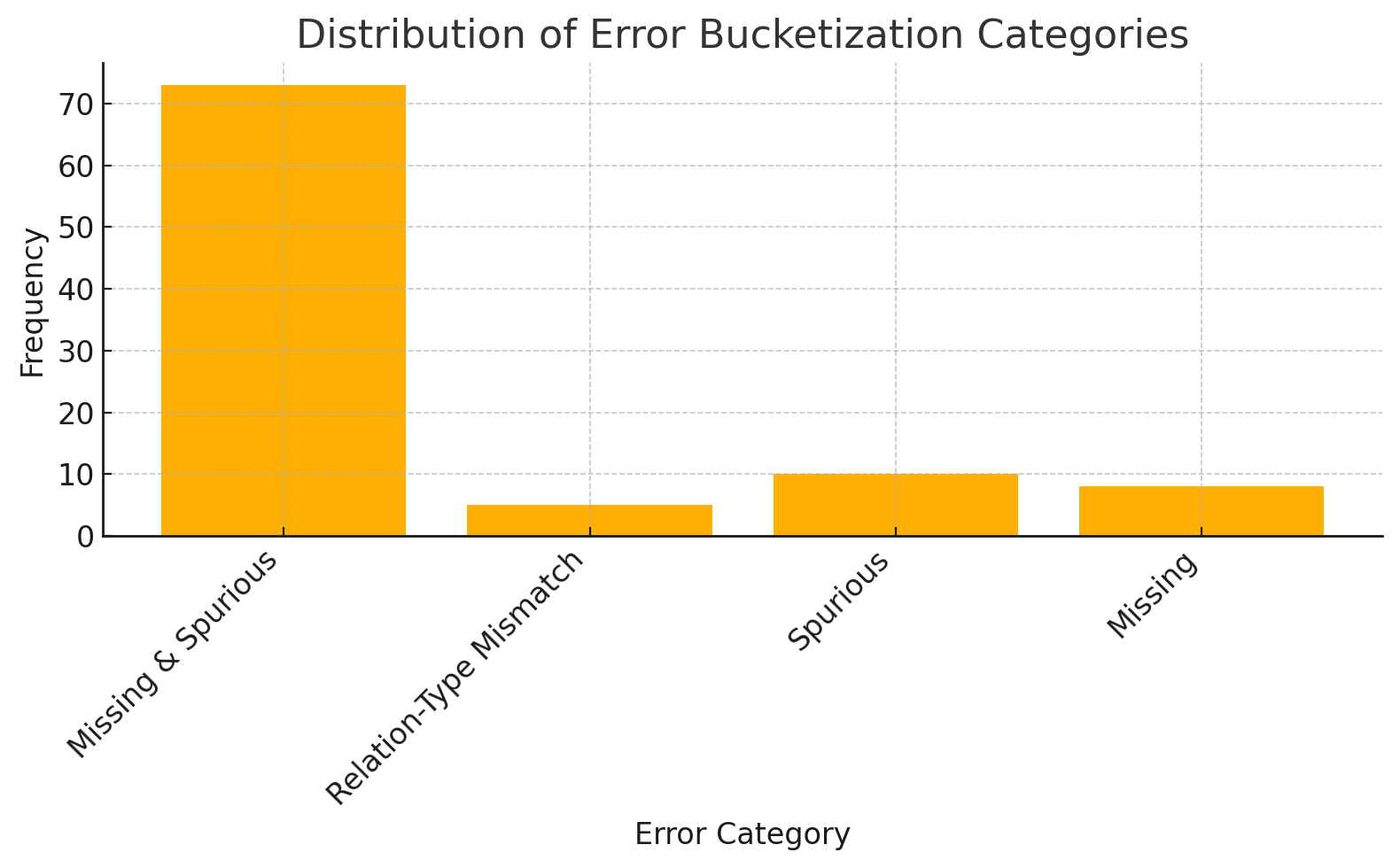
关键创新:本研究的关键创新在于将共指解析与句法分解相结合,显著提高了对复杂句子的处理能力,尤其是在稀有关系的召回率上提升超过20%。
关键设计:在模型训练中,采用了优化的提示-模型对,并通过消融研究验证了不同模块的贡献,确保了系统在多种复杂度类别下的最佳表现。
🖼️ 关键图片

📊 实验亮点
实验结果显示,CoDe-KG在句子简化任务上达到了99.8%的准确率,在关系提取任务上,宏F1达到了65.8%,相比于之前的最先进技术提升了8个百分点,微F1在WebNLG2上达到了75.7%。
🎯 应用场景
该研究的潜在应用领域包括医学文献分析、法律文书处理和社交媒体内容理解等。通过自动化知识图谱构建,能够帮助研究人员和企业快速提取和组织信息,提高数据处理效率,推动智能化应用的发展。
📄 摘要(原文)
We introduce CoDe-KG, an open-source, end-to-end pipeline for extracting sentence-level knowledge graphs by combining robust coreference resolution with syntactic sentence decomposition. Using our model, we contribute a dataset of over 150,000 knowledge triples, which is open source. We also contribute a training corpus of 7248 rows for sentence complexity, 190 rows of gold human annotations for co-reference resolution using open source lung-cancer abstracts from PubMed, 900 rows of gold human annotations for sentence conversion policies, and 398 triples of gold human annotations. We systematically select optimal prompt-model pairs across five complexity categories, showing that hybrid chain-of-thought and few-shot prompting yields up to 99.8% exact-match accuracy on sentence simplification. On relation extraction (RE), our pipeline achieves 65.8% macro-F1 on REBEL, an 8-point gain over the prior state of the art, and 75.7% micro-F1 on WebNLG2, while matching or exceeding performance on Wiki-NRE and CaRB. Ablation studies demonstrate that integrating coreference and decomposition increases recall on rare relations by over 20%. Code and dataset are available at https://github.com/KaushikMahmud/CoDe-KG_EMNLP_2025