Preference Distillation via Value based Reinforcement Learning
作者: Minchan Kwon, Junwon Ko, Kangil Kim, Junmo Kim
分类: cs.CL
发布日期: 2025-09-21
备注: 20 page
期刊: NIPS 2025 Poster
💡 一句话要点
提出基于价值强化学习的偏好蒸馏方法TVKD,提升小模型DPO训练效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 偏好学习 知识蒸馏 强化学习 价值函数 直接偏好优化
📋 核心要点
- DPO方法在训练小模型时,二元胜负监督信号不足,导致训练效果不佳。
- TVKD方法利用教师模型的价值函数提供辅助奖励,作为软指导,提升学生模型的学习效率。
- 实验结果表明,TVKD在多个基准测试和不同模型规模下,均能稳定提升模型性能。
📝 摘要(中文)
直接偏好优化(DPO)是一种强大的范式,它使用成对比较来使语言模型与人类偏好对齐。然而,其二元的胜负监督通常不足以训练容量有限的小模型。先前的工作试图使用行为克隆或KL散度从大型教师模型中提取信息。这些方法通常侧重于模仿当前行为,而忽略了奖励建模的提炼。为了解决这个问题,我们提出了“基于教师价值的知识蒸馏”(TVKD),它引入了来自教师模型价值函数的辅助奖励,以提供软指导。该辅助奖励被设计为满足基于势的奖励塑造,确保DPO的全局奖励结构和最优策略得以保留。TVKD可以集成到标准的DPO训练框架中,并且不需要额外的rollout。我们的实验结果表明,TVKD在各种基准和模型尺寸上都能持续提高性能。
🔬 方法详解
问题定义:论文旨在解决直接偏好优化(DPO)在训练小规模语言模型时,由于二元胜负监督信号的稀疏性,导致模型难以有效学习人类偏好的问题。现有方法如行为克隆或KL散度蒸馏,侧重于模仿教师模型的行为,忽略了奖励建模的知识迁移,限制了学生模型的性能提升。
核心思路:论文的核心思路是通过引入教师模型的价值函数作为辅助奖励,为学生模型提供更丰富的学习信号。这种辅助奖励可以看作是对学生模型行为的软性指导,帮助其更好地理解人类偏好。同时,通过势函数奖励塑造,保证了辅助奖励不会改变DPO的全局奖励结构和最优策略。
技术框架:TVKD方法可以无缝集成到标准的DPO训练框架中。具体流程如下:首先,使用DPO训练一个大型教师模型。然后,在训练学生模型时,除了DPO损失外,还引入一个基于教师模型价值函数的辅助奖励。该辅助奖励被添加到DPO的奖励函数中,共同指导学生模型的训练。整个过程不需要额外的rollout,降低了计算成本。
关键创新:TVKD的关键创新在于利用教师模型的价值函数进行知识蒸馏,而不是简单地模仿其行为。价值函数蕴含了对未来奖励的预测,能够为学生模型提供更全面的偏好信息。此外,通过势函数奖励塑造,保证了辅助奖励的有效性和稳定性。
关键设计:TVKD的关键设计在于辅助奖励的构建方式。辅助奖励基于教师模型的价值函数,并经过势函数奖励塑造,以确保其与DPO的全局奖励结构兼容。具体而言,辅助奖励可以表示为教师模型在当前状态下的价值函数与下一个状态的价值函数之差。此外,论文还可能涉及一些超参数的调整,例如辅助奖励的权重,以平衡DPO损失和辅助奖励的影响。
🖼️ 关键图片

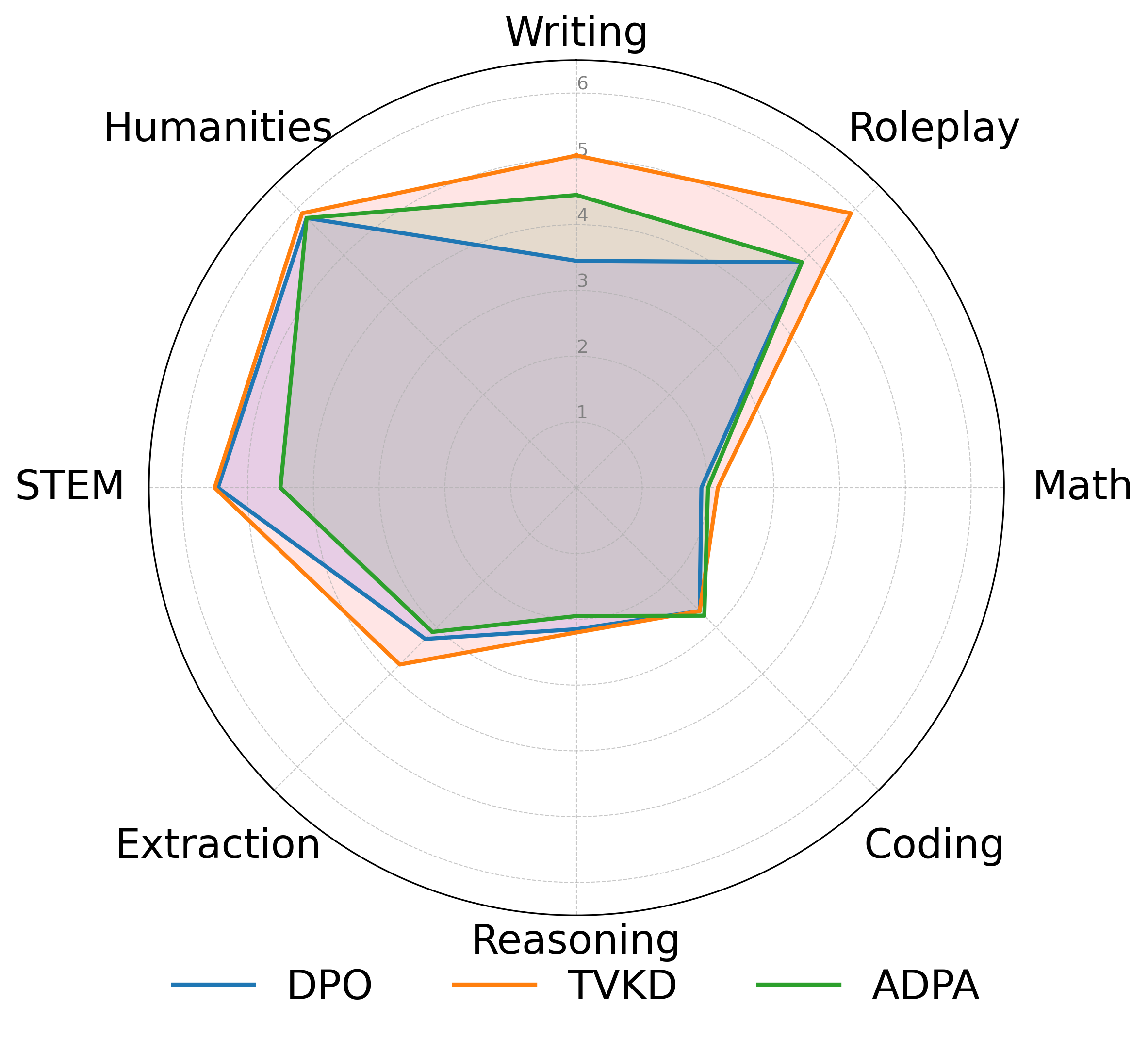
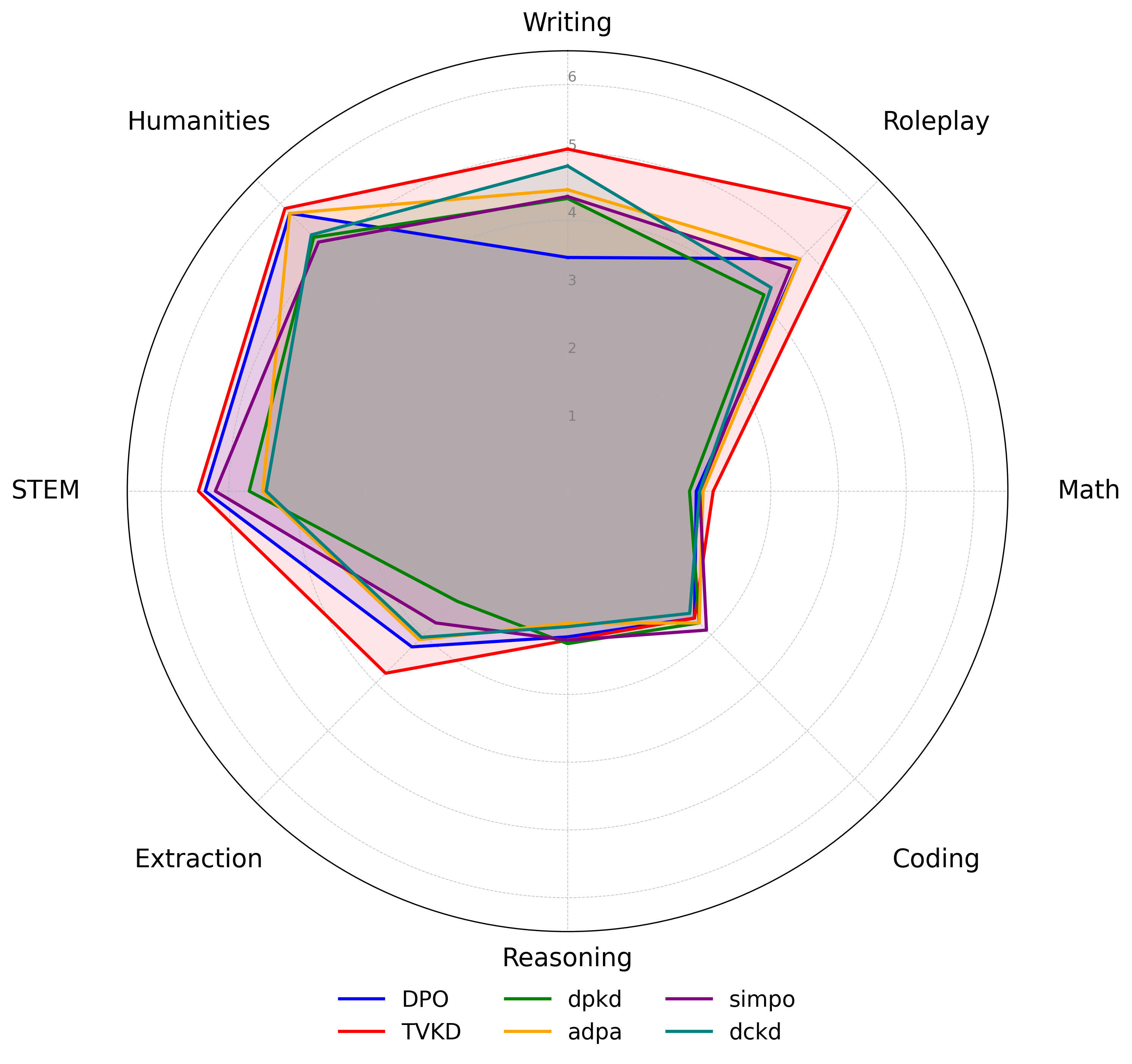
📊 实验亮点
实验结果表明,TVKD方法在各种基准测试和模型尺寸上都能持续提高性能。与基线方法相比,TVKD能够显著提升小规模语言模型的偏好对齐能力,使其在人类评估中获得更高的分数。具体的性能提升幅度取决于具体的任务和模型设置,但总体趋势是TVKD能够有效提升模型的性能。
🎯 应用场景
该研究成果可应用于各种需要对齐语言模型与人类偏好的场景,例如对话系统、文本生成、内容推荐等。通过TVKD方法,可以更有效地训练小规模语言模型,使其更好地理解和满足用户的需求,降低部署成本,并提升用户体验。未来,该方法有望扩展到其他强化学习任务中,提升模型的学习效率和泛化能力。
📄 摘要(原文)
Direct Preference Optimization (DPO) is a powerful paradigm to align language models with human preferences using pairwise comparisons. However, its binary win-or-loss supervision often proves insufficient for training small models with limited capacity. Prior works attempt to distill information from large teacher models using behavior cloning or KL divergence. These methods often focus on mimicking current behavior and overlook distilling reward modeling. To address this issue, we propose \textit{Teacher Value-based Knowledge Distillation} (TVKD), which introduces an auxiliary reward from the value function of the teacher model to provide a soft guide. This auxiliary reward is formulated to satisfy potential-based reward shaping, ensuring that the global reward structure and optimal policy of DPO are preserved. TVKD can be integrated into the standard DPO training framework and does not require additional rollouts. Our experimental results show that TVKD consistently improves performance across various benchmarks and model sizes.