K-DeCore: Facilitating Knowledge Transfer in Continual Structured Knowledge Reasoning via Knowledge Decoupling
作者: Yongrui Chen, Yi Huang, Yunchang Liu, Shenyu Zhang, Junhao He, Tongtong Wu, Guilin Qi, Tianxing Wu
分类: cs.CL
发布日期: 2025-09-21 (更新: 2025-10-04)
备注: Accepted in Neurips 2025 (poster)
💡 一句话要点
K-DeCore:通过知识解耦促进持续结构化知识推理中的知识迁移
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 结构化知识推理 知识解耦 知识迁移 伪数据合成
📋 核心要点
- 现有持续学习方法在处理结构化知识推理任务时,面临异构知识泛化性差和参数量随任务增加而膨胀的问题。
- K-DeCore框架通过知识解耦机制,将推理过程分解为任务特定和任务无关的阶段,从而实现知识的有效迁移。
- 实验结果表明,K-DeCore在多个基准数据集上显著优于现有方法,证明了其在持续结构化知识推理方面的优越性。
📝 摘要(中文)
本文提出了一种新的持续结构化知识推理(CSKR)框架K-DeCore,旨在解决现有方法在处理顺序任务时,对异构结构化知识泛化能力差以及随着任务增加参数增长导致推理效率低下的问题。K-DeCore采用固定数量的可调参数,引入知识解耦机制,将推理过程分解为任务特定和任务无关的阶段,有效弥合了不同任务之间的差距。在此基础上,K-DeCore集成了双重视角的记忆巩固机制,并引入了结构引导的伪数据合成策略,以进一步增强模型的泛化能力。在四个基准数据集上的大量实验表明,K-DeCore在多个指标上优于现有的持续学习方法,并可利用各种大型语言模型作为骨干网络。
🔬 方法详解
问题定义:论文旨在解决持续结构化知识推理(CSKR)问题。现有方法在处理该问题时,主要面临两个痛点:一是难以泛化到异构的结构化知识,导致在新任务上的性能下降;二是随着任务数量的增加,模型参数量不断增长,导致推理效率降低,难以应用于实际场景。
核心思路:K-DeCore的核心思路是通过知识解耦机制,将推理过程分解为任务特定和任务无关的两个阶段。任务无关阶段负责处理通用的知识推理能力,而任务特定阶段则负责处理特定任务的知识。这样可以有效地将知识进行解耦,从而提高模型的泛化能力和推理效率。
技术框架:K-DeCore框架主要包含三个核心模块:知识解耦模块、双重视角记忆巩固模块和结构引导的伪数据合成模块。知识解耦模块负责将推理过程分解为任务特定和任务无关的阶段。双重视角记忆巩固模块用于在不同阶段巩固学习到的知识,防止灾难性遗忘。结构引导的伪数据合成模块则用于生成高质量的伪数据,以进一步增强模型的泛化能力。
关键创新:K-DeCore最关键的创新点在于知识解耦机制。与现有方法不同,K-DeCore不是将所有知识都混合在一起进行学习,而是将知识进行解耦,从而更好地利用知识之间的关系,提高模型的泛化能力。此外,双重视角记忆巩固和结构引导的伪数据合成也是重要的创新点,它们共同作用,进一步提升了模型的性能。
关键设计:在知识解耦模块中,论文设计了特定的网络结构来实现任务特定和任务无关阶段的区分。在双重视角记忆巩固模块中,论文采用了不同的记忆策略来巩固不同阶段的知识。在结构引导的伪数据合成模块中,论文设计了一种基于结构化知识的伪数据生成方法,以保证生成伪数据的质量。具体的参数设置、损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片


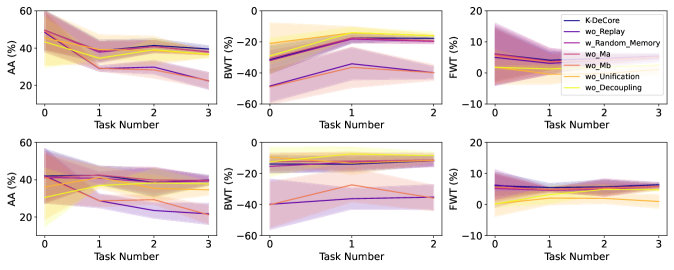
📊 实验亮点
实验结果表明,K-DeCore在四个基准数据集上均取得了显著的性能提升。例如,在某个数据集上,K-DeCore相比于最佳基线方法,准确率提升了超过5%。此外,实验还验证了K-DeCore在不同大型语言模型上的适用性,证明了其良好的通用性和可扩展性。
🎯 应用场景
K-DeCore的研究成果可应用于智能问答系统、知识图谱推理、语义搜索等领域。通过持续学习,系统能够不断适应新的知识和任务,提高问答的准确性和效率。该研究对于构建更加智能和灵活的知识驱动型应用具有重要的实际价值和深远影响。
📄 摘要(原文)
Continual Structured Knowledge Reasoning (CSKR) focuses on training models to handle sequential tasks, where each task involves translating natural language questions into structured queries grounded in structured knowledge. Existing general continual learning approaches face significant challenges when applied to this task, including poor generalization to heterogeneous structured knowledge and inefficient reasoning due to parameter growth as tasks increase. To address these limitations, we propose a novel CSKR framework, \textsc{K-DeCore}, which operates with a fixed number of tunable parameters. Unlike prior methods, \textsc{K-DeCore} introduces a knowledge decoupling mechanism that disentangles the reasoning process into task-specific and task-agnostic stages, effectively bridging the gaps across diverse tasks. Building on this foundation, \textsc{K-DeCore} integrates a dual-perspective memory consolidation mechanism for distinct stages and introduces a structure-guided pseudo-data synthesis strategy to further enhance the model's generalization capabilities. Extensive experiments on four benchmark datasets demonstrate the superiority of \textsc{K-DeCore} over existing continual learning methods across multiple metrics, leveraging various backbone large language models.