Can GRPO Boost Complex Multimodal Table Understanding?
作者: Xiaoqiang Kang, Shengen Wu, Zimu Wang, Yilin Liu, Xiaobo Jin, Kaizhu Huang, Wei Wang, Yutao Yue, Xiaowei Huang, Qiufeng Wang
分类: cs.CL
发布日期: 2025-09-21 (更新: 2025-09-23)
备注: EMNLP 2025
期刊: EMNLP 2025
💡 一句话要点
Table-R1:通过三阶段强化学习提升复杂多模态表格理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格理解 强化学习 多模态学习 表格问答 奖励函数设计
📋 核心要点
- 现有表格理解方法难以处理复杂结构和逻辑推理,监督微调虽主流但有局限。
- Table-R1通过预热、感知对齐GRPO和提示补全GRPO三个阶段强化学习提升性能。
- 实验表明Table-R1显著提升表格推理能力,甚至超越特定模型,接近GPT-4o。
📝 摘要(中文)
现有的表格理解方法在处理复杂表格结构和逻辑推理时面临挑战。监督微调(SFT)是目前研究的主流方法,而强化学习(RL),如Group Relative Policy Optimization (GRPO),也显示出潜力,但受限于表格上下文中初始策略准确率低和奖励粗糙的问题。本文提出了Table-R1,一个三阶段的RL框架,通过以下方式增强多模态表格理解:(1)预热阶段,激发初始感知和推理能力;(2)感知对齐GRPO (PA-GRPO),采用连续的树编辑距离相似度(TEDS)奖励来识别表格结构和内容;(3)提示补全GRPO (HC-GRPO),利用基于提示引导问题的残差步骤的细粒度奖励。大量实验表明,Table-R1显著提升了模型在同分布和异分布数据集上的表格推理性能,大幅优于SFT和GRPO。值得注意的是,配备Table-R1的Qwen2-VL-7B超越了更大的特定表格理解模型(如Table-LLaVA 13B),甚至在同分布数据集上取得了与闭源模型GPT-4o相当的性能,证明了Table-R1的每个阶段在克服初始化瓶颈和奖励稀疏性方面的有效性,从而推进了鲁棒的多模态表格理解。
🔬 方法详解
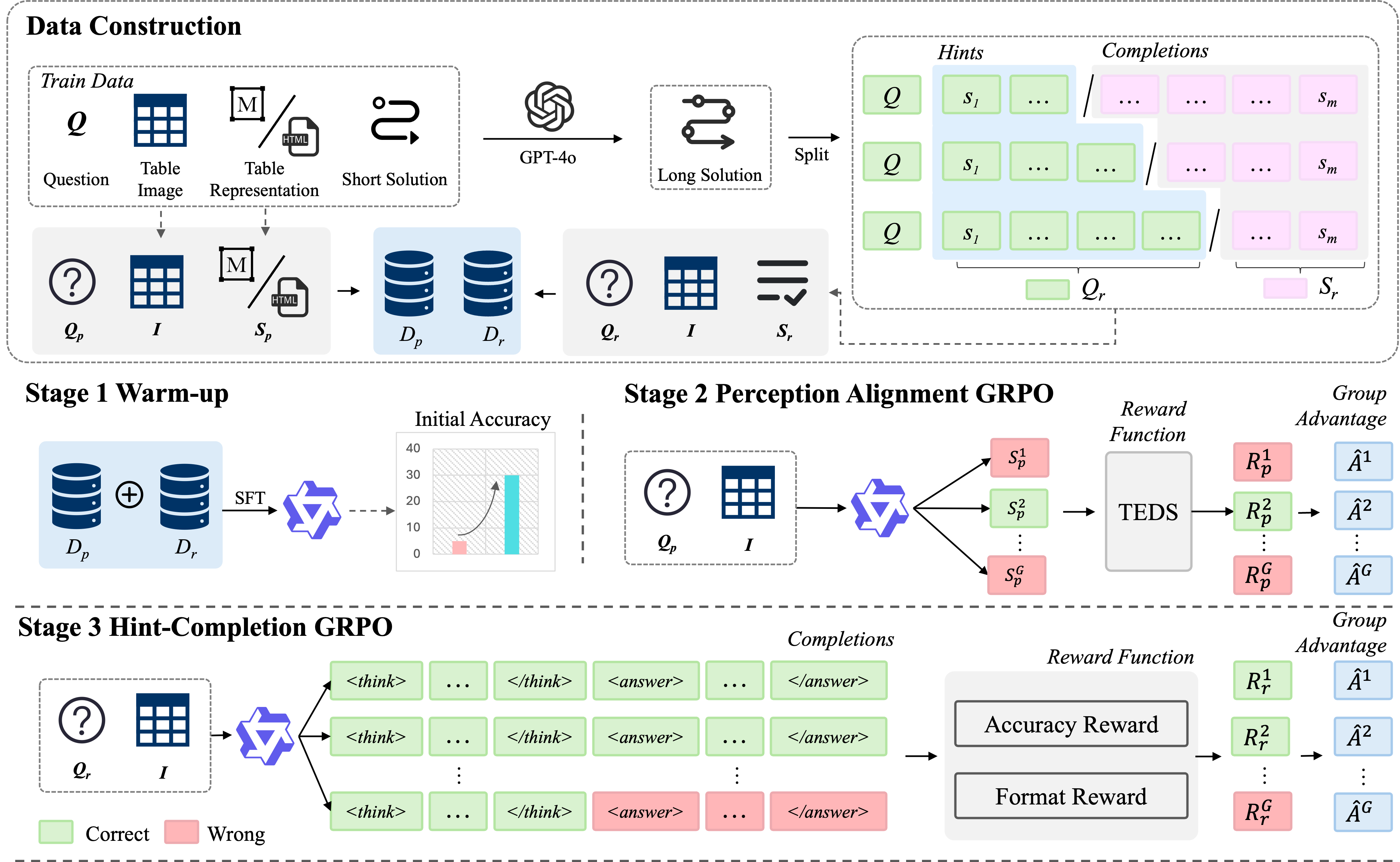
问题定义:现有表格理解方法在处理复杂表格时,面临结构理解和逻辑推理的挑战。监督微调方法虽然常用,但泛化能力有限。强化学习方法,如GRPO,虽然有潜力,但由于初始策略准确率低和奖励信号稀疏,难以有效训练。
核心思路:Table-R1的核心思路是通过一个三阶段的强化学习框架,逐步提升模型对表格的理解能力。首先通过预热阶段提高初始策略的准确率,然后通过感知对齐GRPO学习表格的结构和内容,最后通过提示补全GRPO学习表格的逻辑推理能力。这种逐步提升的策略可以有效克服初始化瓶颈和奖励稀疏性问题。
技术框架:Table-R1框架包含三个阶段: 1. Warm-up (预热):使用监督学习方法,让模型初步学习表格的感知和推理能力,为后续的强化学习提供一个较好的初始策略。 2. Perception Alignment GRPO (PA-GRPO):使用Group Relative Policy Optimization (GRPO)算法,并引入连续的树编辑距离相似度(TEDS)作为奖励信号,鼓励模型更好地识别表格的结构和内容。 3. Hint-Completion GRPO (HC-GRPO):使用GRPO算法,并利用基于提示引导问题的残差步骤的细粒度奖励,鼓励模型更好地进行表格的逻辑推理。
关键创新:Table-R1的关键创新在于其三阶段的强化学习框架,以及在每个阶段中使用的特定奖励函数。预热阶段解决了初始策略准确率低的问题,PA-GRPO阶段的TEDS奖励解决了结构和内容识别的奖励稀疏性问题,HC-GRPO阶段的细粒度奖励解决了逻辑推理的奖励稀疏性问题。这种分阶段、精细化的奖励设计是Table-R1能够取得良好效果的关键。
关键设计: * TEDS奖励:使用树编辑距离相似度来衡量模型生成的表格结构与真实表格结构之间的差异,从而提供连续的奖励信号。 * 残差步骤奖励:在HC-GRPO阶段,根据模型在回答问题时每一步的残差,给予不同的奖励,从而提供更细粒度的奖励信号。 * Qwen2-VL-7B:选择Qwen2-VL-7B作为基础模型,因为它具有较强的多模态理解能力。
🖼️ 关键图片


📊 实验亮点
Table-R1在同分布和异分布数据集上均显著优于SFT和GRPO方法。使用Table-R1的Qwen2-VL-7B超越了Table-LLaVA 13B等更大的特定表格理解模型,并在同分布数据集上取得了与闭源模型GPT-4o相当的性能,证明了该方法的有效性。
🎯 应用场景
Table-R1可应用于金融分析、数据挖掘、报告生成等领域,提升表格数据的自动化处理和理解能力。该研究有助于开发更智能的表格问答系统,辅助决策,提高工作效率,并为未来更复杂的表格理解任务奠定基础。
📄 摘要(原文)
Existing table understanding methods face challenges due to complex table structures and intricate logical reasoning. While supervised finetuning (SFT) dominates existing research, reinforcement learning (RL), such as Group Relative Policy Optimization (GRPO), has shown promise but struggled with low initial policy accuracy and coarse rewards in tabular contexts. In this paper, we introduce Table-R1, a three-stage RL framework that enhances multimodal table understanding through: (1) Warm-up that prompts initial perception and reasoning capabilities, (2) Perception Alignment GRPO (PA-GRPO), which employs continuous Tree-Edit-Distance Similarity (TEDS) rewards for recognizing table structures and contents, and (3) Hint-Completion GRPO (HC-GRPO), which utilizes fine-grained rewards of residual steps based on the hint-guided question. Extensive experiments demonstrate that Table-R1 can boost the model's table reasoning performance obviously on both held-in and held-out datasets, outperforming SFT and GRPO largely. Notably, Qwen2-VL-7B with Table-R1 surpasses larger specific table understanding models (e.g., Table-LLaVA 13B), even achieving comparable performance to the closed-source model GPT-4o on held-in datasets, demonstrating the efficacy of each stage of Table-R1 in overcoming initialization bottlenecks and reward sparsity, thereby advancing robust multimodal table understanding.