The Sound of Syntax: Finetuning and Comprehensive Evaluation of Language Models for Speech Pathology
作者: Fagun Patel, Duc Q. Nguyen, Sang T. Truong, Jody Vaynshtok, Sanmi Koyejo, Nick Haber
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2025-09-20 (更新: 2025-10-08)
备注: EMNLP 2025 Oral Presentation
💡 一句话要点
针对语音病理学,提出微调语言模型并进行全面评估的方案,旨在辅助语音治疗师。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音病理学 多模态语言模型 基准测试 微调 临床应用 语音识别 自然语言处理
📋 核心要点
- 现有语音治疗师数量远低于患病儿童数量,亟需技术手段提升治疗效率,但多模态语言模型在临床环境下的性能评估不足。
- 论文与领域专家合作,构建了语音病理学中多模态语言模型的用例分类,并提出了一个包含手动标注数据的综合评估基准。
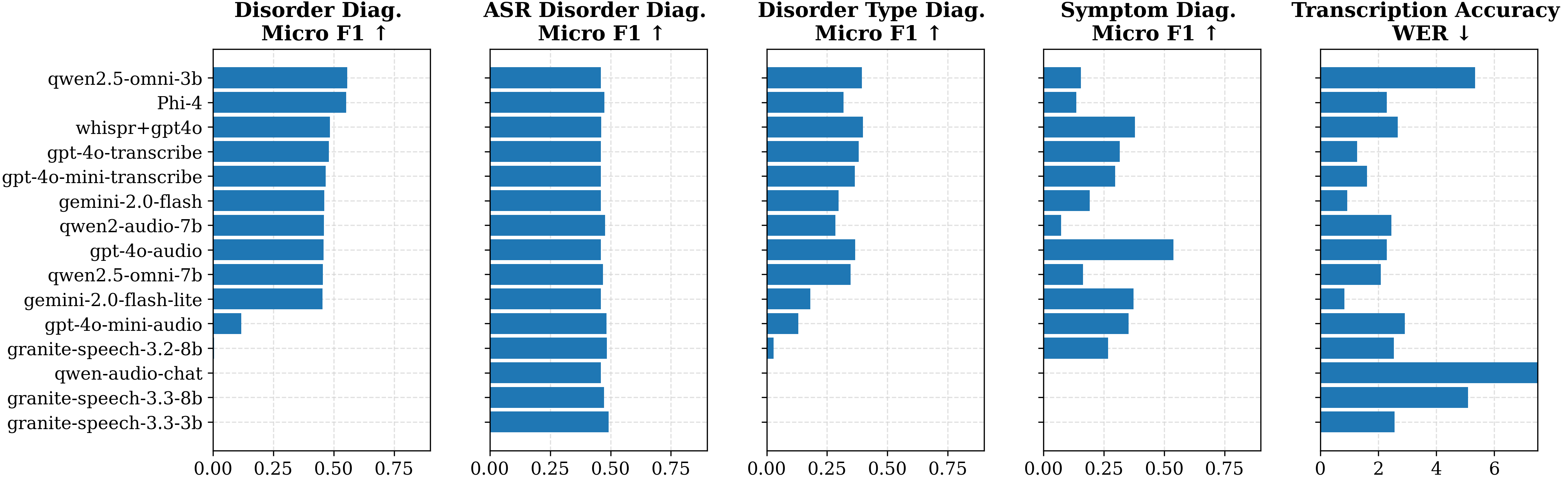
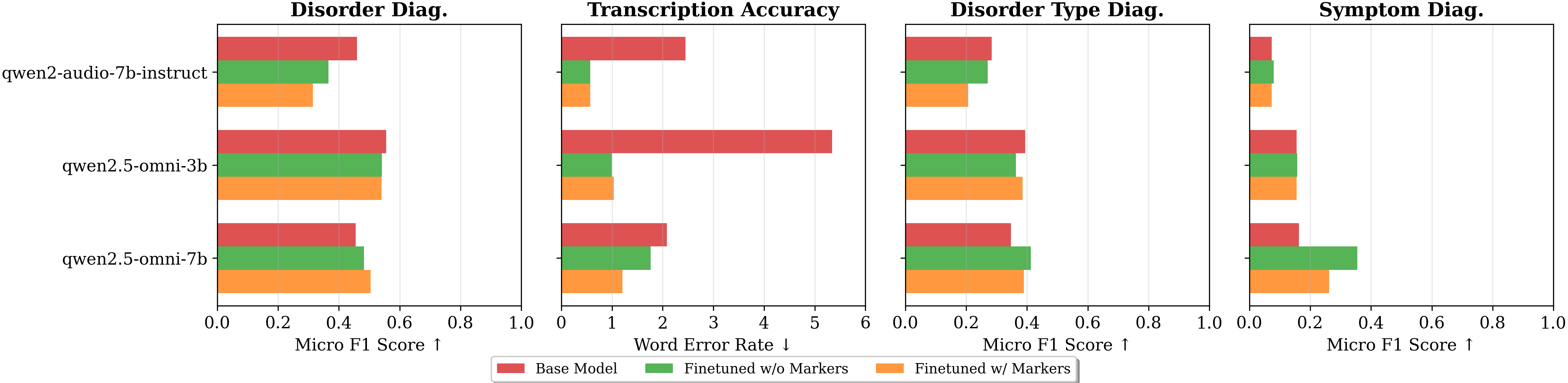
- 实验评估了15个先进模型,发现模型在不同性别说话人上的表现存在差异,且微调领域数据可显著提升模型性能。
📝 摘要(中文)
美国国立卫生研究院数据显示,超过340万儿童患有需要临床干预的言语障碍。但语音治疗师(SLP)的数量远少于患病儿童,凸显了儿童护理方面的巨大缺口,迫切需要技术支持来提高SLP的工作效率。多模态语言模型(MLM)在支持SLP方面显示出潜力,但由于对其在高风险临床环境中的性能了解有限,其应用仍未得到充分探索。为了解决这个问题,我们与领域专家合作,开发了MLM在语音病理学中实际用例的分类。在此基础上,我们推出了首个综合基准,用于评估MLM在五个核心用例中的表现,每个用例包含1000个手动标注的数据点。该基准包括在各种设置下的鲁棒性和敏感性测试,包括背景噪声、说话人性别和口音。我们对15个最先进的MLM的评估表明,没有一个模型在所有任务中始终优于其他模型。值得注意的是,我们发现存在系统性差异,模型在男性说话者上的表现更好,并且观察到思维链提示会降低标签空间大且决策边界窄的分类任务的性能。此外,我们研究了在领域特定数据上微调MLM,与基础模型相比,性能提高了10%以上。这些发现突出了当前MLM在语音病理学应用中的潜力和局限性,强调需要进一步研究和有针对性的开发。
🔬 方法详解
问题定义:论文旨在解决语音病理学领域中,语音治疗师资源短缺的问题,并探索多模态语言模型(MLM)在该领域的应用潜力。现有方法缺乏对MLM在高风险临床环境下的全面评估,难以有效指导实际应用。现有方法没有针对语音病理学任务的专用基准测试和评估标准。
核心思路:论文的核心思路是构建一个全面的评估基准,用于评估MLM在语音病理学领域的性能。通过与领域专家合作,定义了MLM在该领域的实际用例,并针对这些用例设计了相应的评估指标和数据集。通过对现有MLM进行评估和微调,探索其在语音病理学领域的应用潜力。
技术框架:论文的技术框架主要包括以下几个部分:1) 与领域专家合作,定义MLM在语音病理学中的用例分类;2) 构建包含手动标注数据的综合评估基准,包括鲁棒性和敏感性测试;3) 评估15个最先进的MLM在基准上的性能;4) 在领域特定数据上微调MLM,并评估其性能提升。
关键创新:论文的关键创新在于:1) 提出了首个针对语音病理学领域MLM的综合评估基准;2) 揭示了现有MLM在不同性别说话人上的性能差异,以及思维链提示对分类任务的影响;3) 通过在领域特定数据上微调MLM,显著提升了模型性能。
关键设计:论文的关键设计包括:1) 基准测试包含五个核心用例,每个用例包含1000个手动标注的数据点;2) 评估指标包括准确率、召回率、F1值等;3) 微调过程中,使用了领域特定的语音数据和文本数据,并调整了模型的学习率和训练轮数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,没有一个模型在所有任务中始终优于其他模型,模型在男性说话者上的表现普遍优于女性。通过在领域特定数据上微调MLM,模型性能提升超过10%。思维链提示在标签空间大且决策边界窄的分类任务中会降低性能。
🎯 应用场景
该研究成果可应用于开发辅助语音治疗的智能工具,例如自动语音诊断、治疗方案推荐等,从而提高语音治疗师的工作效率,并为更多患有言语障碍的儿童提供帮助。该研究也为多模态语言模型在医疗健康领域的应用提供了有价值的参考。
📄 摘要(原文)
According to the U.S. National Institutes of Health, more than 3.4 million children experience speech disorders that require clinical intervention. The number of speech-language pathologists (SLPs) is roughly 20 times fewer than the number of affected children, highlighting a significant gap in children's care and a pressing need for technological support that improves the productivity of SLPs. State-of-the-art multimodal language models (MLMs) show promise for supporting SLPs, but their use remains underexplored largely due to a limited understanding of their performance in high-stakes clinical settings. To address this gap, we collaborate with domain experts to develop a taxonomy of real-world use cases of MLMs in speech-language pathologies. Building on this taxonomy, we introduce the first comprehensive benchmark for evaluating MLM across five core use cases, each containing 1,000 manually annotated data points. This benchmark includes robustness and sensitivity tests under various settings, including background noise, speaker gender, and accent. Our evaluation of 15 state-of-the-art MLMs reveals that no single model consistently outperforms others across all tasks. Notably, we find systematic disparities, with models performing better on male speakers, and observe that chain-of-thought prompting can degrade performance on classification tasks with large label spaces and narrow decision boundaries. Furthermore, we study fine-tuning MLMs on domain-specific data, achieving improvements of over 10\% compared to base models. These findings highlight both the potential and limitations of current MLMs for speech-language pathology applications, underscoring the need for further research and targeted development.