Semi-Supervised Synthetic Data Generation with Fine-Grained Relevance Control for Short Video Search Relevance Modeling
作者: Haoran Li, Zhiming Su, Junyan Yao, Enwei Zhang, Yang Ji, Yan Chen, Kan Zhou, Chao Feng, Jiao Ran
分类: cs.CL
发布日期: 2025-09-20 (更新: 2025-12-04)
备注: Submitted to AAAI 2026
💡 一句话要点
提出半监督合成数据生成方法,解决短视频搜索相关性建模中细粒度相关性控制问题
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 短视频搜索 相关性建模 半监督学习 合成数据生成 细粒度相关性 领域自适应 embedding模型
📋 核心要点
- 现有prompt方法在短视频搜索相关性建模中,难以捕捉领域数据分布,忽略细粒度相关性多样性,导致模型泛化能力不足。
- 提出半监督合成数据pipeline,通过协同训练模型生成领域自适应短视频数据,并控制相关性标签,提升数据多样性。
- 实验表明,该方法在离线和在线A/B测试中均取得显著提升,尤其在CTR、SRR和IUPR等指标上表现突出。
📝 摘要(中文)
合成数据在embedding模型中被广泛采用,以确保训练数据分布在难度、长度和语言等维度上的多样性。然而,现有的基于prompt的合成方法难以捕捉特定领域的数据分布,尤其是在数据稀缺的领域,并且常常忽略细粒度的相关性多样性。本文提出了一个包含4级相关性标注的中文短视频数据集,填补了关键的资源空白。此外,我们提出了一种半监督合成数据pipeline,其中两个协同训练的模型生成具有可控相关性标签的领域自适应短视频数据。我们的方法通过为代表性不足的中间相关性标签合成样本来增强相关性级别的多样性,从而产生更平衡和语义更丰富的训练数据集。大量的离线实验表明,在我们的合成数据上训练的embedding模型优于使用基于prompt或vanilla监督微调(SFT)生成的数据训练的模型。此外,我们证明了在训练数据中加入更多样化的细粒度相关性级别可以增强模型对细微语义差异的敏感性,突出了细粒度相关性监督在embedding学习中的价值。在抖音双列场景的搜索增强推荐pipeline中,通过在线A/B测试,所提出的模型点击率(CTR)提高了1.45%,强相关比例(SRR)提高了4.9%,图像用户渗透率(IUPR)提高了0.1054%。
🔬 方法详解
问题定义:论文旨在解决短视频搜索相关性建模中,训练数据不足以及现有合成数据方法无法有效捕捉细粒度相关性信息的问题。现有基于prompt的合成方法难以适应特定领域的数据分布,尤其是在数据稀缺的场景下,并且忽略了不同相关性级别之间的细微差异,导致模型无法准确区分不同程度的相关性。
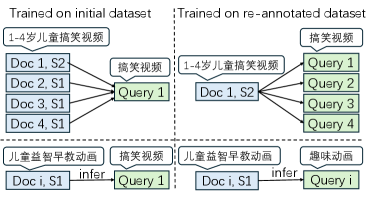
核心思路:论文的核心思路是利用半监督学习方法,协同训练两个模型,生成具有可控相关性标签的领域自适应短视频数据。通过这种方式,可以有效扩充训练数据集,并提升数据集中细粒度相关性级别的多样性,从而提高模型的泛化能力和对语义细微差别的敏感性。
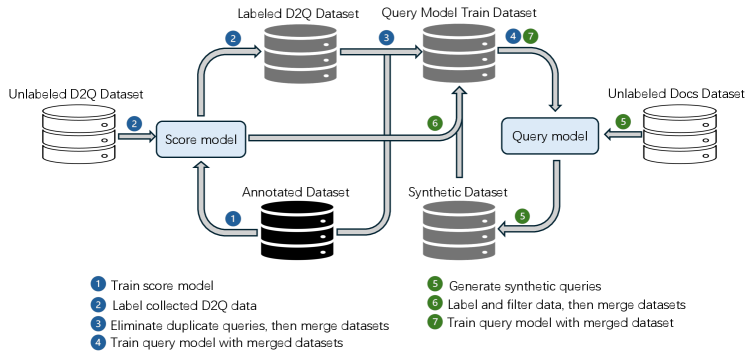
技术框架:该方法包含一个半监督合成数据pipeline,主要包括以下几个阶段:1) 构建包含4级相关性标注的中文短视频数据集;2) 设计两个协同训练的模型,分别负责生成短视频数据和预测相关性标签;3) 利用半监督学习策略,结合少量标注数据和大量未标注数据进行训练;4) 通过控制生成模型的参数,实现对合成数据相关性级别的精细控制。
关键创新:该方法最重要的创新点在于提出了一个半监督的合成数据生成框架,能够有效地生成具有细粒度相关性标签的短视频数据。与传统的prompt方法相比,该方法能够更好地适应特定领域的数据分布,并提升数据集中相关性级别的多样性。此外,协同训练的策略也能够提高生成数据的质量和标签的准确性。
关键设计:论文的关键设计包括:1) 设计了合适的网络结构,用于生成短视频数据和预测相关性标签;2) 采用了合适的损失函数,用于指导模型的训练,例如交叉熵损失函数和一致性损失函数;3) 设计了精细的参数控制机制,用于控制生成数据的相关性级别,例如通过调整生成模型的输入prompt或调整生成模型的输出分布。
🖼️ 关键图片

📊 实验亮点
离线实验表明,在合成数据上训练的embedding模型优于基于prompt或SFT方法训练的模型。在线A/B测试显示,该模型在抖音双列场景中,CTR提升1.45%,SRR提升4.9%,IUPR提升0.1054%,证明了细粒度相关性监督的有效性。
🎯 应用场景
该研究成果可应用于短视频搜索、推荐系统等领域,提升用户搜索体验和推荐准确率。通过生成高质量的合成数据,可以有效解决数据稀缺问题,降低模型训练成本,并提高模型在实际应用中的泛化能力。该方法还可推广到其他领域,例如图像搜索、文本检索等。
📄 摘要(原文)
Synthetic data is widely adopted in embedding models to ensure diversity in training data distributions across dimensions such as difficulty, length, and language. However, existing prompt-based synthesis methods struggle to capture domain-specific data distributions, particularly in data-scarce domains, and often overlook fine-grained relevance diversity. In this paper, we present a Chinese short video dataset with 4-level relevance annotations, filling a critical resource void. Further, we propose a semi-supervised synthetic data pipeline where two collaboratively trained models generate domain-adaptive short video data with controllable relevance labels. Our method enhances relevance-level diversity by synthesizing samples for underrepresented intermediate relevance labels, resulting in a more balanced and semantically rich training data set. Extensive offline experiments show that the embedding model trained on our synthesized data outperforms those using data generated based on prompting or vanilla supervised fine-tuning(SFT). Moreover, we demonstrate that incorporating more diverse fine-grained relevance levels in training data enhances the model's sensitivity to subtle semantic distinctions, highlighting the value of fine-grained relevance supervision in embedding learning. In the search enhanced recommendation pipeline of Douyin's dual-column scenario, through online A/B testing, the proposed model increased click-through rate(CTR) by 1.45%, raised the proportion of Strong Relevance Ratio (SRR) by 4.9%, and improved the Image User Penetration Rate (IUPR) by 0.1054%.