EG-MLA: Embedding-Gated Multi-head Latent Attention for Scalable and Efficient LLMs
作者: Zhengge Cai, Haowen Hou
分类: cs.CL
发布日期: 2025-09-20
💡 一句话要点
提出EG-MLA,通过嵌入门控机制压缩KV缓存,提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 KV缓存压缩 注意力机制 嵌入门控 模型推理加速
📋 核心要点
- 大型语言模型推理时,KV缓存占用大量内存,限制了模型部署和效率,现有方法难以在性能无损情况下进一步压缩。
- EG-MLA在MLA基础上引入嵌入门控机制,对潜在空间的KV向量进行细粒度调制,提升表征能力并进一步压缩KV缓存。
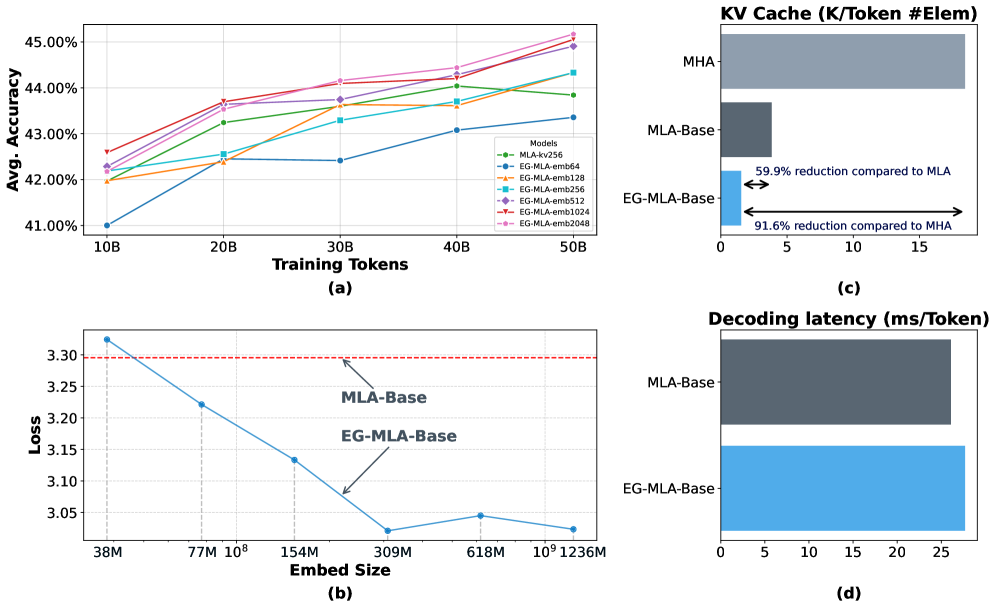
- 实验表明,EG-MLA相比MHA可减少91.6%的KV缓存,相比MLA可额外节省59.9%内存,并在多种推理任务上提升准确率。
📝 摘要(中文)
为了在延迟和内存约束下实现大型语言模型(LLM)的高效推理,减小键值(KV)缓存大小至关重要。多头注意力(MHA)虽然具有强大的表征能力,但会产生显著的内存开销。多头潜在注意力(MLA)通过将KV表示压缩到共享潜在空间来缓解这个问题,从而在性能和缓存效率之间取得更好的平衡。本文提出了一种新颖的MLA扩展方法——嵌入门控多头潜在注意力(EG-MLA),它进一步减小了KV缓存大小,同时增强了表征表达能力。EG-MLA在潜在空间中应用了一种token特定的嵌入门控机制,以最小的额外计算量实现对压缩KV向量的细粒度调制。与MHA相比,EG-MLA实现了超过91.6%的KV缓存大小缩减,而性能下降可忽略不计。相对于MLA,EG-MLA在不同的推理基准测试中始终提高了任务准确性,同时实现了高达59.9%的额外内存节省。理论分析强调了嵌入门控如何诱导隐式高阶交互,经验评估表明了其在模型规模和压缩方案中的稳健泛化能力。值得注意的是,我们成功地将EG-MLA扩展到超过10亿个参数,证明了其在大型LLM部署中的实际可行性。这些结果表明,EG-MLA是一种内存和计算效率高的注意力机制,可以在现代LLM中实现可扩展的高性能推理。
🔬 方法详解
问题定义:大型语言模型(LLM)在推理过程中需要维护一个键值(KV)缓存,用于存储先前token的表示。这个KV缓存会消耗大量的内存,尤其是在长序列和大型模型中,从而限制了LLM的部署和推理效率。现有的多头潜在注意力(MLA)虽然可以压缩KV缓存,但在性能不显著下降的前提下,压缩空间已经接近极限。
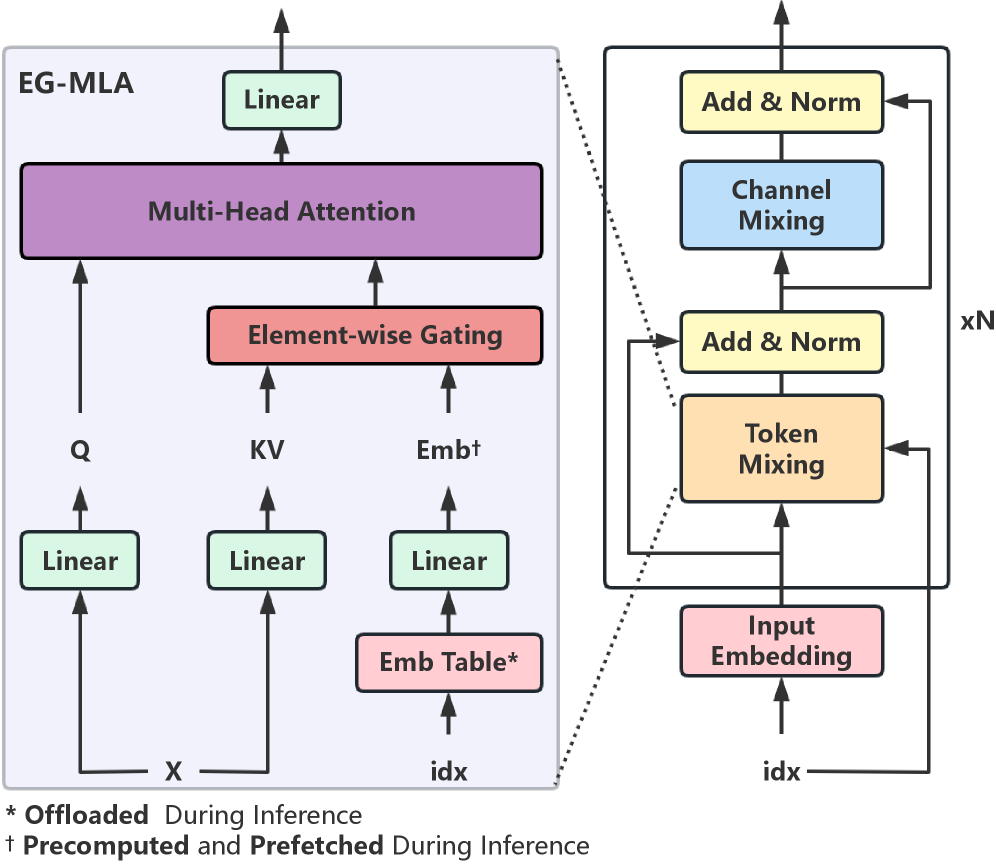
核心思路:EG-MLA的核心思路是在MLA的基础上,引入一个token特定的嵌入门控机制。这个门控机制作用于潜在空间中的KV向量,允许模型根据当前token的信息,对压缩后的KV表示进行细粒度的调制。通过这种方式,EG-MLA可以在不显著增加计算量的情况下,增强模型的表征能力,并进一步压缩KV缓存。
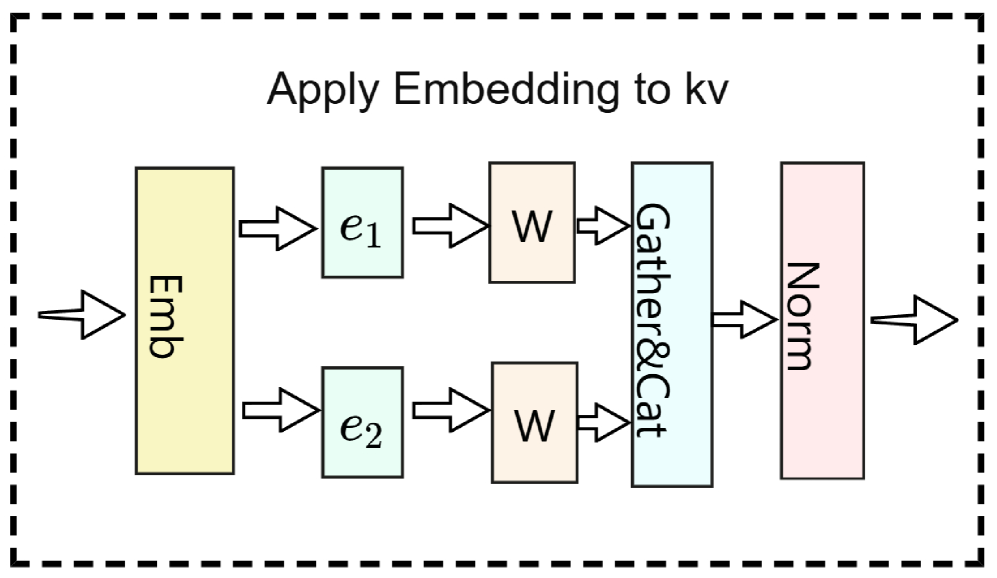
技术框架:EG-MLA的整体框架与MLA类似,首先将Query、Key和Value投影到潜在空间,然后进行注意力计算。不同之处在于,在注意力计算之前,EG-MLA会使用一个嵌入层生成一个token特定的门控向量,然后将这个门控向量与潜在空间中的Key和Value向量进行逐元素相乘。这个过程可以看作是对Key和Value向量进行加权,从而使模型能够更加灵活地利用历史信息。
关键创新:EG-MLA最关键的创新点在于引入了嵌入门控机制。这个机制允许模型根据当前token的信息,动态地调整历史信息的权重,从而增强了模型的表征能力。与传统的注意力机制相比,EG-MLA的嵌入门控机制可以看作是一种隐式的高阶交互,它可以捕捉token之间的复杂关系。
关键设计:EG-MLA的关键设计包括嵌入门控向量的生成方式和门控向量的应用方式。论文中使用了简单的线性层来生成嵌入门控向量,并使用逐元素相乘的方式将门控向量应用到Key和Value向量上。此外,论文还对嵌入门控向量的维度进行了实验,发现合适的维度可以平衡模型的性能和计算量。
🖼️ 关键图片
📊 实验亮点
EG-MLA在多个推理基准测试中表现出色。与MHA相比,EG-MLA实现了超过91.6%的KV缓存大小缩减,性能损失可忽略不计。与MLA相比,EG-MLA在各种推理任务中持续提高准确性,同时实现了高达59.9%的额外内存节省。此外,EG-MLA成功扩展到超过10亿个参数,证明了其在大规模LLM部署中的可行性。
🎯 应用场景
EG-MLA适用于对内存和延迟有严格要求的场景,例如移动设备上的LLM部署、边缘计算和实时对话系统。通过显著降低KV缓存大小,EG-MLA可以使大型语言模型在资源受限的环境中高效运行,并加速LLM在各个领域的应用。
📄 摘要(原文)
Reducing the key-value (KV) cache size is a crucial step toward enabling efficient inference in large language models (LLMs), especially under latency and memory constraints. While Multi-Head Attention (MHA) offers strong representational power, it incurs significant memory overhead. Recent work on Multi-head Latent Attention (MLA) mitigates this by compressing KV representations into a shared latent space, achieving a better trade-off between performance and cache efficiency. While MLA already achieves significant KV cache reduction, the scope for further compression remains limited without performance loss. In this paper, we propose \textbf{Embedding-Gated Multi-head Latent Attention (EG-MLA)}, a novel extension of MLA that further reduces KV cache size while enhancing representational expressiveness. EG-MLA introduces a token-specific embedding gating mechanism applied in the latent space, enabling fine-grained modulation of compressed KV vectors with minimal additional computation. Compared to MHA, EG-MLA achieves over 91.6\% reduction in KV cache size with negligible performance degradation. Relative to MLA, EG-MLA consistently improves task accuracy across diverse reasoning benchmarks while achieving up to 59.9\% additional memory savings. Our theoretical analysis highlights how embedding gating induces implicit high-order interactions, and empirical evaluations demonstrate robust generalization across model scales and compression regimes. Notably, we successfully scale EG-MLA to over 1 billion parameters, demonstrating its practical viability for large-scale LLM deployment. These results establish EG-MLA as a memory- and compute-efficient attention mechanism that enables scalable, high-performance inference in modern LLMs.